 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Data Size Sensitivity in Unsupervised Rhyme Recognition
Apr 09, 2026Rhyme is deceptively intuitive: what is or is not a rhyme is constructed historically, scholars struggle with rhyme classification, and people disagree on whether two words are rhymed or not. This complicates automated rhymed recognition and evaluation, especially in multilingual context. This article investigates how much training data is needed for reliable unsupervised rhyme recognition using RhymeTagger, a language-independent tool that identifies rhymes based on repeating patterns in poetry corpora. We evaluate its performance across seven languages (Czech, German, English, French, Italian, Russian, and Slovene), examining how training size and language differences affect accuracy. To set a realistic performance benchmark, we assess inter-annotator agreement on a manually annotated subset of poems and analyze factors contributing to disagreement in expert annotations: phonetic similarity between rhyming words and their distance from each other in a poem. We also compare RhymeTagger to three large language models using a one-shot learning strategy. Our findings show that, once provided with sufficient training data, RhymeTagger consistently outperforms human agreement, while LLMs lacking phonetic representation significantly struggle with the task.
Co-creation for Sign Language Processing and Machine Translation
Mar 03, 2025Sign language machine translation (SLMT) -- the task of automatically translating between sign and spoken languages or between sign languages -- is a complex task within the field of NLP. Its multi-modal and non-linear nature require the joint efforts of sign language (SL) linguists, technical experts and SL users. Effective user involvement is a challenge that can be addressed through co-creation. Co-creation has been formally defined in many fields, e.g. business, marketing, educational and others, however in NLP and in particular in SLMT there is no formal, widely accepted definition. Starting from the inception and evolution of co-creation across various fields over time, we develop a relationship typology to address the collaboration between deaf, Hard of Hearing and hearing researchers and the co-creation with SL-users. We compare this new typology to the guiding principles of participatory design for NLP. We, then, assess 110 articles from the perspective of involvement of SL users and highlight the lack of involvement of the sign language community or users in decision-making processes required for effective co-creation. Finally, we derive formal guidelines for co-creation for SLMT which take the dynamic nature of co-creation throughout the life cycle of a research project into account.
AI in Support of Diversity and Inclusion
Jan 16, 2025

In this paper, we elaborate on how AI can support diversity and inclusion and exemplify research projects conducted in that direction. We start by looking at the challenges and progress in making large language models (LLMs) more transparent, inclusive, and aware of social biases. Even though LLMs like ChatGPT have impressive abilities, they struggle to understand different cultural contexts and engage in meaningful, human like conversations. A key issue is that biases in language processing, especially in machine translation, can reinforce inequality. Tackling these biases requires a multidisciplinary approach to ensure AI promotes diversity, fairness, and inclusion. We also highlight AI's role in identifying biased content in media, which is important for improving representation. By detecting unequal portrayals of social groups, AI can help challenge stereotypes and create more inclusive technologies. Transparent AI algorithms, which clearly explain their decisions, are essential for building trust and reducing bias in AI systems. We also stress AI systems need diverse and inclusive training data. Projects like the Child Growth Monitor show how using a wide range of data can help address real world problems like malnutrition and poverty. We present a project that demonstrates how AI can be applied to monitor the role of search engines in spreading disinformation about the LGBTQ+ community. Moreover, we discuss the SignON project as an example of how technology can bridge communication gaps between hearing and deaf people, emphasizing the importance of collaboration and mutual trust in developing inclusive AI. Overall, with this paper, we advocate for AI systems that are not only effective but also socially responsible, promoting fair and inclusive interactions between humans and machines.
Metronome: tracing variation in poetic meters via local sequence alignment
Apr 26, 2024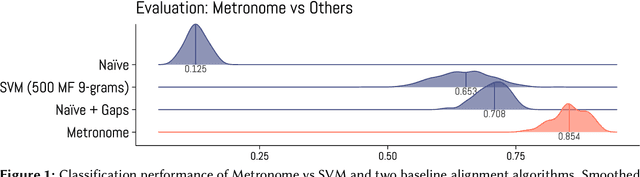
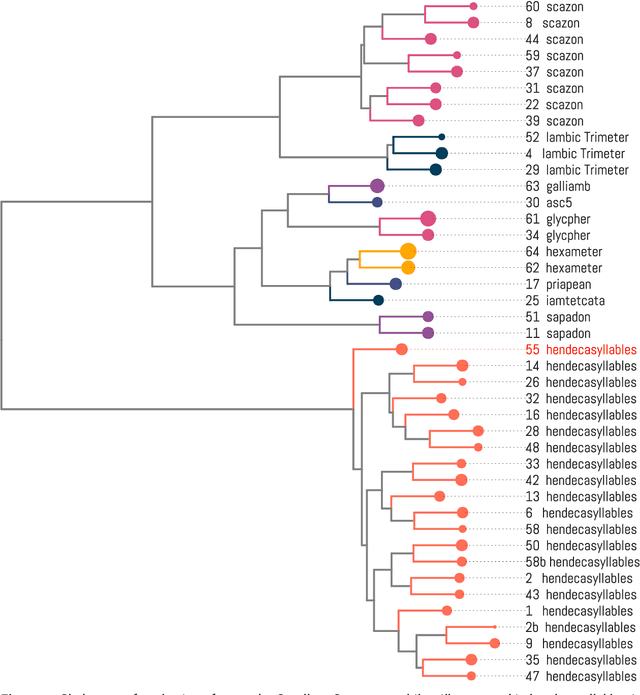

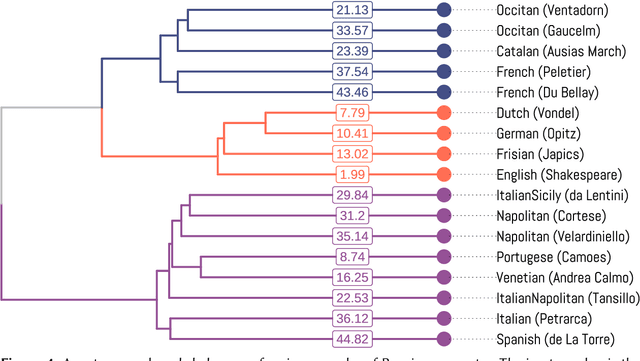
All poetic forms come from somewhere. Prosodic templates can be copied for generations, altered by individuals, imported from foreign traditions, or fundamentally changed under the pressures of language evolution. Yet these relationships are notoriously difficult to trace across languages and times. This paper introduces an unsupervised method for detecting structural similarities in poems using local sequence alignment. The method relies on encoding poetic texts as strings of prosodic features using a four-letter alphabet; these sequences are then aligned to derive a distance measure based on weighted symbol (mis)matches. Local alignment allows poems to be clustered according to emergent properties of their underlying prosodic patterns. We evaluate method performance on a meter recognition tasks against strong baselines and show its potential for cross-lingual and historical research using three short case studies: 1) mutations in quantitative meter in classical Latin, 2) European diffusion of the Renaissance hendecasyllable, and 3) comparative alignment of modern meters in 18--19th century Czech, German and Russian. We release an implementation of the algorithm as a Python package with an open license.
Tailoring Domain Adaptation for Machine Translation Quality Estimation
Apr 18, 2023
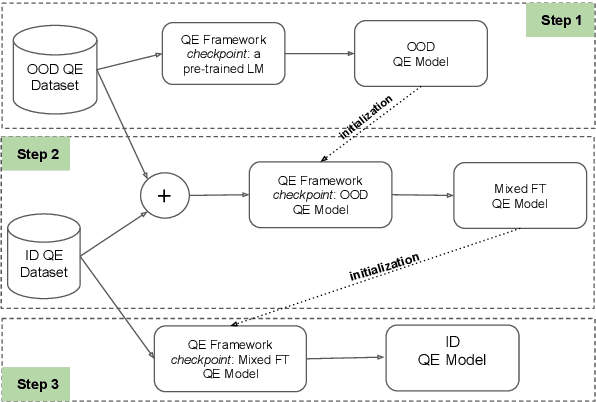


While quality estimation (QE) can play an important role in the translation process, its effectiveness relies on the availability and quality of training data. For QE in particular, high-quality labeled data is often lacking due to the high-cost and effort associated with labeling such data. Aside from the data scarcity challenge, QE models should also be generalizable, i.e., they should be able to handle data from different domains, both generic and specific. To alleviate these two main issues -- data scarcity and domain mismatch -- this paper combines domain adaptation and data augmentation within a robust QE system. Our method is to first train a generic QE model and then fine-tune it on a specific domain while retaining generic knowledge. Our results show a significant improvement for all the language pairs investigated, better cross-lingual inference, and a superior performance in zero-shot learning scenarios as compared to state-of-the-art baselines.