 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI in Support of Diversity and Inclusion
Jan 16, 2025

In this paper, we elaborate on how AI can support diversity and inclusion and exemplify research projects conducted in that direction. We start by looking at the challenges and progress in making large language models (LLMs) more transparent, inclusive, and aware of social biases. Even though LLMs like ChatGPT have impressive abilities, they struggle to understand different cultural contexts and engage in meaningful, human like conversations. A key issue is that biases in language processing, especially in machine translation, can reinforce inequality. Tackling these biases requires a multidisciplinary approach to ensure AI promotes diversity, fairness, and inclusion. We also highlight AI's role in identifying biased content in media, which is important for improving representation. By detecting unequal portrayals of social groups, AI can help challenge stereotypes and create more inclusive technologies. Transparent AI algorithms, which clearly explain their decisions, are essential for building trust and reducing bias in AI systems. We also stress AI systems need diverse and inclusive training data. Projects like the Child Growth Monitor show how using a wide range of data can help address real world problems like malnutrition and poverty. We present a project that demonstrates how AI can be applied to monitor the role of search engines in spreading disinformation about the LGBTQ+ community. Moreover, we discuss the SignON project as an example of how technology can bridge communication gaps between hearing and deaf people, emphasizing the importance of collaboration and mutual trust in developing inclusive AI. Overall, with this paper, we advocate for AI systems that are not only effective but also socially responsible, promoting fair and inclusive interactions between humans and machines.
Explaining Predictions by Approximating the Local Decision Boundary
Jun 14, 2020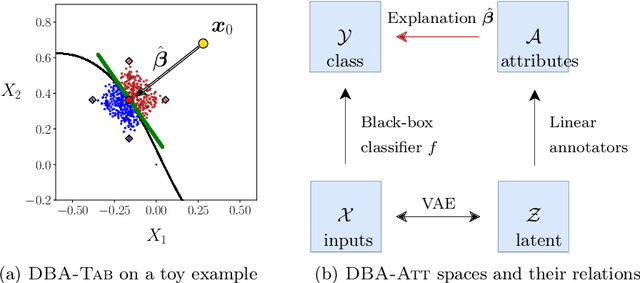

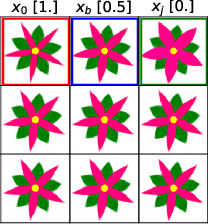
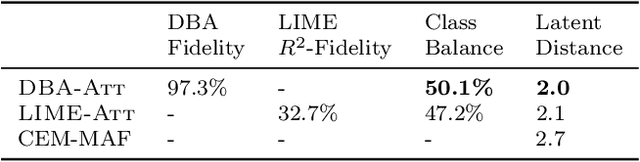
Constructing accurate model-agnostic explanations for opaque machine learning models remains a challenging task. Classification models for high-dimensional data, like images, are often complex and highly parameterized. To reduce this complexity, various authors attempt to explain individual predictions locally, either in terms of a simpler local surrogate model or by communicating how the predictions contrast with those of another class. However, existing approaches still fall short in the following ways: a) they measure locality using a (Euclidean) metric that is not meaningful for non-linear high-dimensional data; or b) they do not attempt to explain the decision boundary, which is the most relevant characteristic of classifiers that are optimized for classification accuracy; or c) they do not give the user any freedom in specifying attributes that are meaningful to them. We address these issues in a new procedure for local decision boundary approximation (DBA). To construct a meaningful metric, we train a variational autoencoder to learn a Euclidean latent space of encoded data representations. We impose interpretability by exploiting attribute annotations to map the latent space to attributes that are meaningful to the user. A difficulty in evaluating explainability approaches is the lack of a ground truth. We address this by introducing a new benchmark data set with artificially generated Iris images, and showing that we can recover the latent attributes that locally determine the class. We further evaluate our approach on the CelebA image data set.