 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept Inconsistency in Dermoscopic Concept Bottleneck Models: A Rough-Set Analysis of the Derm7pt Dataset
Apr 21, 2026Concept Bottleneck Models (CBMs) route predictions exclusively through a clinically grounded concept layer, binding interpretability to concept-label consistency. When a dataset contains concept-level inconsistencies, identical concept profiles mapped to conflicting diagnosis labels create an unresolvable bottleneck that imposes a hard ceiling on achievable accuracy. In this paper, we apply rough set theory to the Derm7pt dermoscopy benchmark and characterize the full extent and clinical structure of this inconsistency. Among 305 unique concept profiles formed by the 7 dermoscopic criteria of the 7-point melanoma checklist, 50 (16.4%) are inconsistent, spanning 306 images (30.3% of the dataset). This yields a theoretical accuracy ceiling of 92.1%, independent of backbone architecture or training strategy for CBMs that exclusively operate with hard concepts. In addition, we characterize the conflict-severity distribution, identify the clinical features most responsible for boundary ambiguity, and evaluate two filtering strategies with quantified effects on dataset composition and CBM interpretability. Symmetric removal of all boundary-region images yields Derm7pt+, a fully consistent benchmark subset of 705 images with perfect quality of classification and no hard accuracy ceiling. Building on this filtered dataset, we present a hard CBM evaluated across 19 backbone architectures from the EfficientNet, DenseNet, ResNet, and Wide ResNet families. Under symmetric filtering, explored for completeness, EfficientNet-B5 achieves the best label F1 score (0.85) and label accuracy (0.90) on the held-out test set, with a concept accuracy of 0.70. Under asymmetric filtering, EfficientNet-B7 leads across all four metrics, reaching a label F1 score of 0.82 and concept accuracy of 0.70. These results establish reproducible baselines for concept-consistent CBM evaluation on dermoscopic data.
AI in Support of Diversity and Inclusion
Jan 16, 2025

In this paper, we elaborate on how AI can support diversity and inclusion and exemplify research projects conducted in that direction. We start by looking at the challenges and progress in making large language models (LLMs) more transparent, inclusive, and aware of social biases. Even though LLMs like ChatGPT have impressive abilities, they struggle to understand different cultural contexts and engage in meaningful, human like conversations. A key issue is that biases in language processing, especially in machine translation, can reinforce inequality. Tackling these biases requires a multidisciplinary approach to ensure AI promotes diversity, fairness, and inclusion. We also highlight AI's role in identifying biased content in media, which is important for improving representation. By detecting unequal portrayals of social groups, AI can help challenge stereotypes and create more inclusive technologies. Transparent AI algorithms, which clearly explain their decisions, are essential for building trust and reducing bias in AI systems. We also stress AI systems need diverse and inclusive training data. Projects like the Child Growth Monitor show how using a wide range of data can help address real world problems like malnutrition and poverty. We present a project that demonstrates how AI can be applied to monitor the role of search engines in spreading disinformation about the LGBTQ+ community. Moreover, we discuss the SignON project as an example of how technology can bridge communication gaps between hearing and deaf people, emphasizing the importance of collaboration and mutual trust in developing inclusive AI. Overall, with this paper, we advocate for AI systems that are not only effective but also socially responsible, promoting fair and inclusive interactions between humans and machines.
Measuring Implicit Bias Using SHAP Feature Importance and Fuzzy Cognitive Maps
May 17, 2023



In this paper, we integrate the concepts of feature importance with implicit bias in the context of pattern classification. This is done by means of a three-step methodology that involves (i) building a classifier and tuning its hyperparameters, (ii) building a Fuzzy Cognitive Map model able to quantify implicit bias, and (iii) using the SHAP feature importance to active the neural concepts when performing simulations. The results using a real case study concerning fairness research support our two-fold hypothesis. On the one hand, it is illustrated the risks of using a feature importance method as an absolute tool to measure implicit bias. On the other hand, it is concluded that the amount of bias towards protected features might differ depending on whether the features are numerically or categorically encoded.
Which is the best model for my data?
Oct 26, 2022In this paper, we tackle the problem of selecting the optimal model for a given structured pattern classification dataset. In this context, a model can be understood as a classifier and a hyperparameter configuration. The proposed meta-learning approach purely relies on machine learning and involves four major steps. Firstly, we present a concise collection of 62 meta-features that address the problem of information cancellation when aggregation measure values involving positive and negative measurements. Secondly, we describe two different approaches for synthetic data generation intending to enlarge the training data. Thirdly, we fit a set of pre-defined classification models for each classification problem while optimizing their hyperparameters using grid search. The goal is to create a meta-dataset such that each row denotes a multilabel instance describing a specific problem. The features of these meta-instances denote the statistical properties of the generated datasets, while the labels encode the grid search results as binary vectors such that best-performing models are positively labeled. Finally, we tackle the model selection problem with several multilabel classifiers, including a Convolutional Neural Network designed to handle tabular data. The simulation results show that our meta-learning approach can correctly predict an optimal model for 91% of the synthetic datasets and for 87% of the real-world datasets. Furthermore, we noticed that most meta-classifiers produced better results when using our meta-features. Overall, our proposal differs from other meta-learning approaches since it tackles the algorithm selection and hyperparameter tuning problems in a single step. Toward the end, we perform a feature importance analysis to determine which statistical features drive the model selection mechanism.
Multi-objective hyperparameter optimization with performance uncertainty
Sep 09, 2022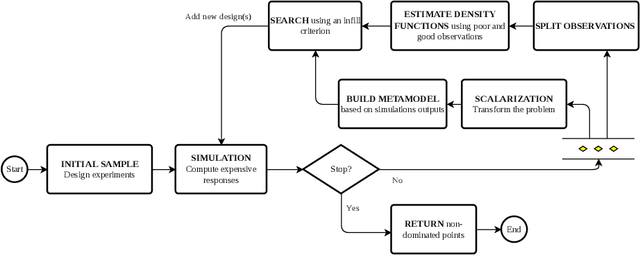

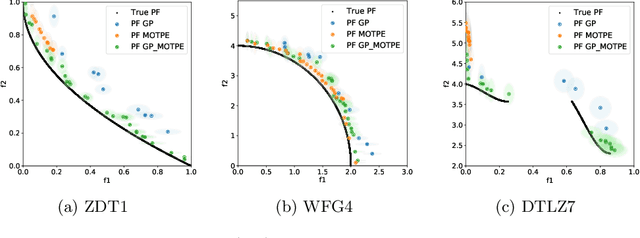
The performance of any Machine Learning (ML) algorithm is impacted by the choice of its hyperparameters. As training and evaluating a ML algorithm is usually expensive, the hyperparameter optimization (HPO) method needs to be computationally efficient to be useful in practice. Most of the existing approaches on multi-objective HPO use evolutionary strategies and metamodel-based optimization. However, few methods have been developed to account for uncertainty in the performance measurements. This paper presents results on multi-objective hyperparameter optimization with uncertainty on the evaluation of ML algorithms. We combine the sampling strategy of Tree-structured Parzen Estimators (TPE) with the metamodel obtained after training a Gaussian Process Regression (GPR) with heterogeneous noise. Experimental results on three analytical test functions and three ML problems show the improvement over multi-objective TPE and GPR, achieved with respect to the hypervolume indicator.
Modeling Implicit Bias with Fuzzy Cognitive Maps
Jan 13, 2022
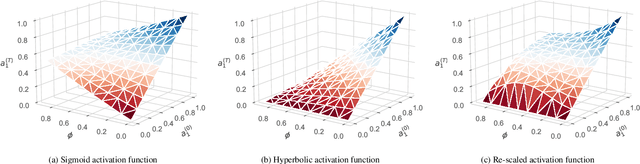
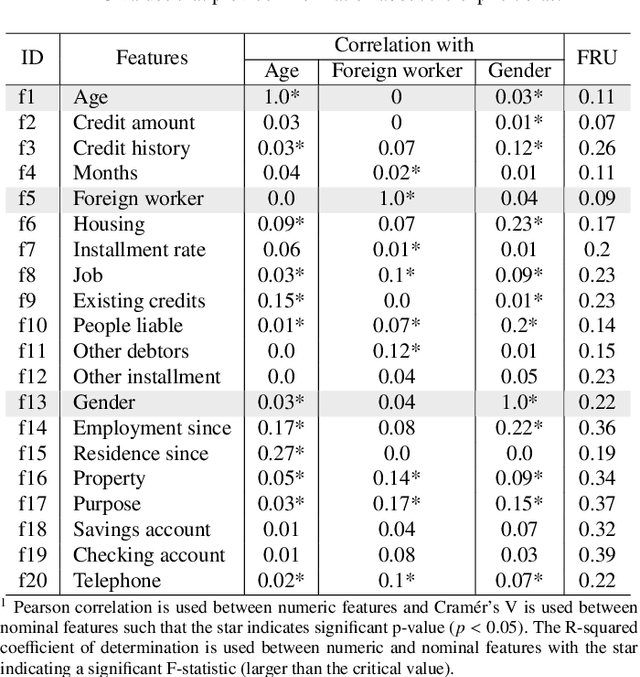
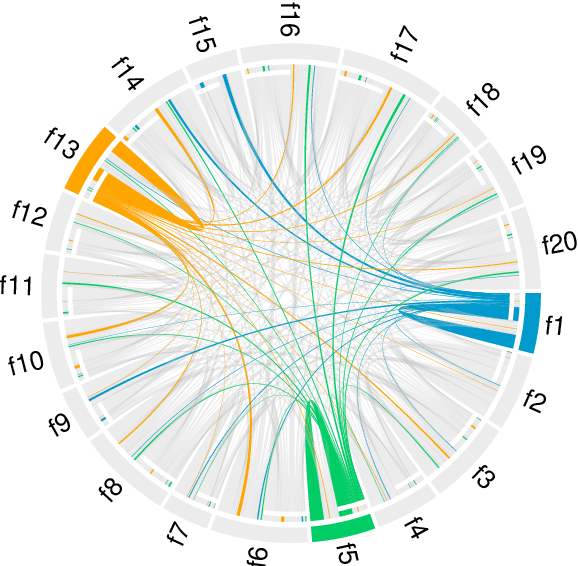
This paper presents a Fuzzy Cognitive Map model to quantify implicit bias in structured datasets where features can be numeric or discrete. In our proposal, problem features are mapped to neural concepts that are initially activated by experts when running what-if simulations, whereas weights connecting the neural concepts represent absolute correlation/association patterns between features. In addition, we introduce a new reasoning mechanism equipped with a normalization-like transfer function that prevents neurons from saturating. Another advantage of this new reasoning mechanism is that it can easily be controlled by regulating nonlinearity when updating neurons' activation values in each iteration. Finally, we study the convergence of our model and derive analytical conditions concerning the existence and unicity of fixed-point attractors.
Forward Composition Propagation for Explainable Neural Reasoning
Dec 23, 2021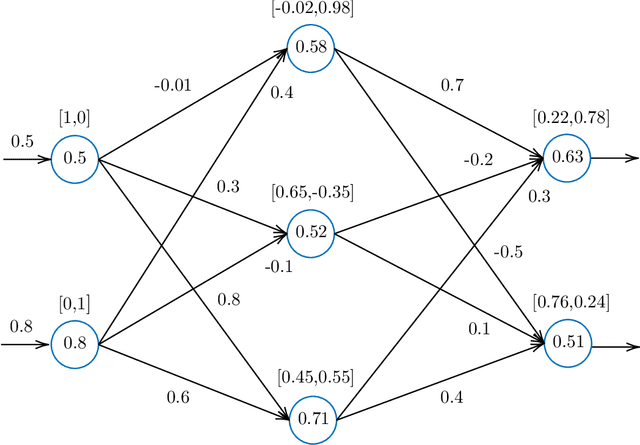
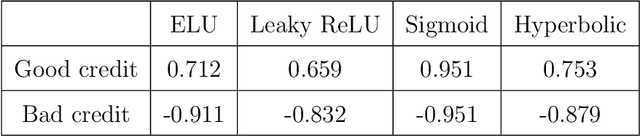
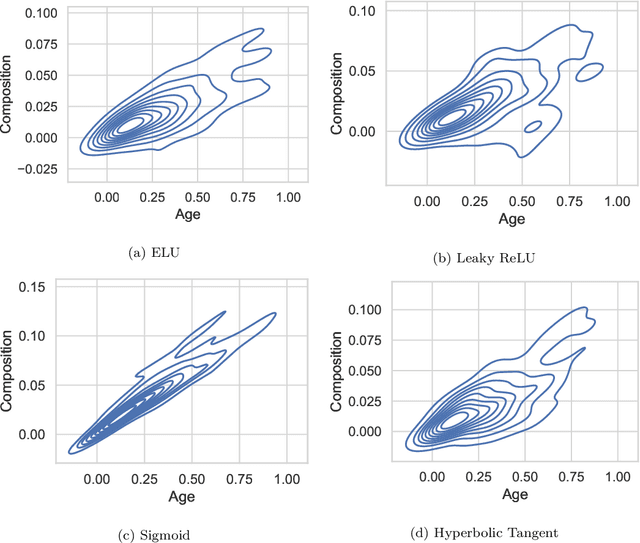
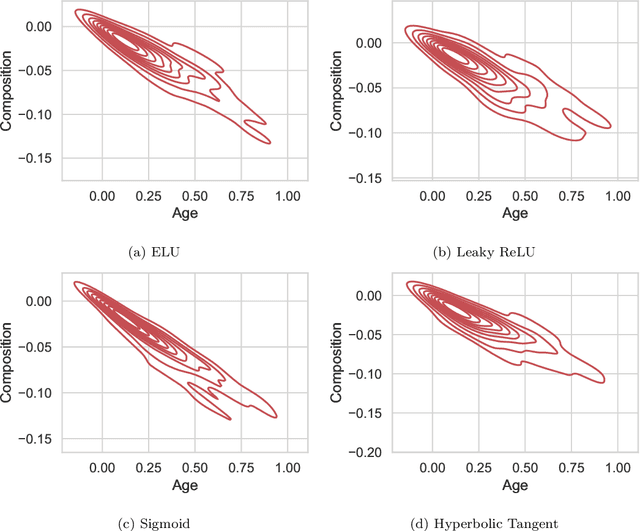
This paper proposes an algorithm called Forward Composition Propagation (FCP) to explain the predictions of feed-forward neural networks operating on structured pattern recognition problems. In the proposed FCP algorithm, each neuron is described by a composition vector indicating the role of each problem feature in that neuron. Composition vectors are initialized using a given input instance and subsequently propagated through the whole network until we reach the output layer. It is worth mentioning that the algorithm is executed once the network's training network is done. The sign of each composition value indicates whether the corresponding feature excites or inhibits the neuron, while the absolute value quantifies such an impact. Aiming to validate the FCP algorithm's correctness, we develop a case study concerning bias detection in a state-of-the-art problem in which the ground truth is known. The simulation results show that the composition values closely align with the expected behavior of protected features.
Prolog-based agnostic explanation module for structured pattern classification
Dec 23, 2021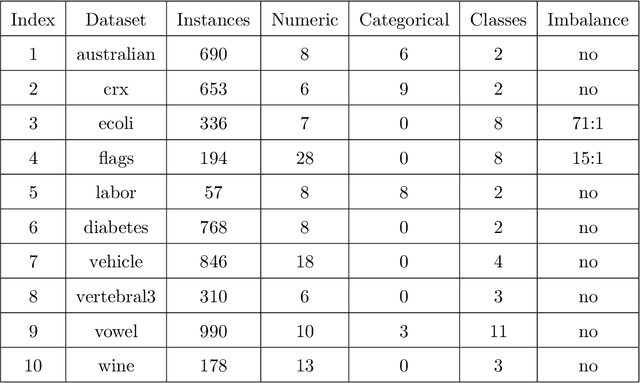


This paper presents a Prolog-based reasoning module to generate counterfactual explanations given the predictions computed by a black-box classifier. The proposed symbolic reasoning module can also resolve what-if queries using the ground-truth labels instead of the predicted ones. Overall, our approach comprises four well-defined stages that can be applied to any structured pattern classification problem. Firstly, we pre-process the given dataset by imputing missing values and normalizing the numerical features. Secondly, we transform numerical features into symbolic ones using fuzzy clustering such that extracted fuzzy clusters are mapped to an ordered set of predefined symbols. Thirdly, we encode instances as a Prolog rule using the nominal values, the predefined symbols, the decision classes, and the confidence values. Fourthly, we compute the overall confidence of each Prolog rule using fuzzy-rough set theory to handle the uncertainty caused by transforming numerical quantities into symbols. This step comes with an additional theoretical contribution to a new similarity function to compare the previously defined Prolog rules involving confidence values. Finally, we implement a chatbot as a proxy between human beings and the Prolog-based reasoning module to resolve natural language queries and generate counterfactual explanations. During the numerical simulations using synthetic datasets, we study the performance of our system when using different fuzzy operators and similarity functions. Towards the end, we illustrate how our reasoning module works using different use cases.
Measuring Wind Turbine Health Using Drifting Concepts
Dec 09, 2021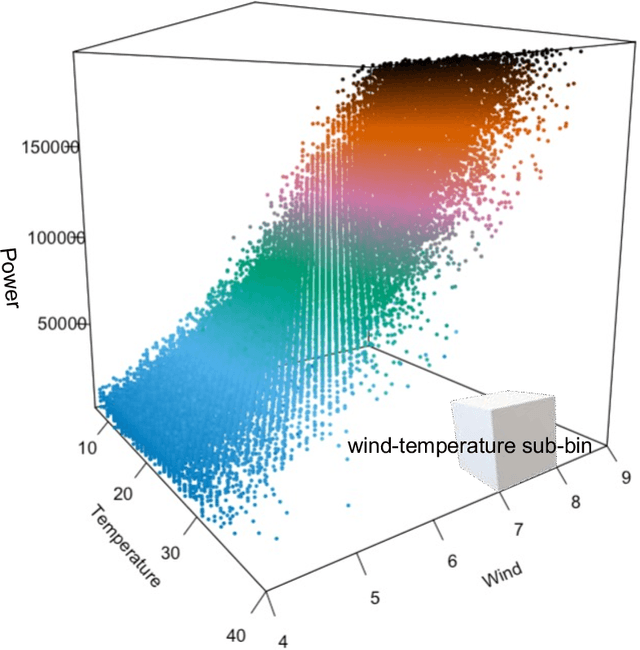
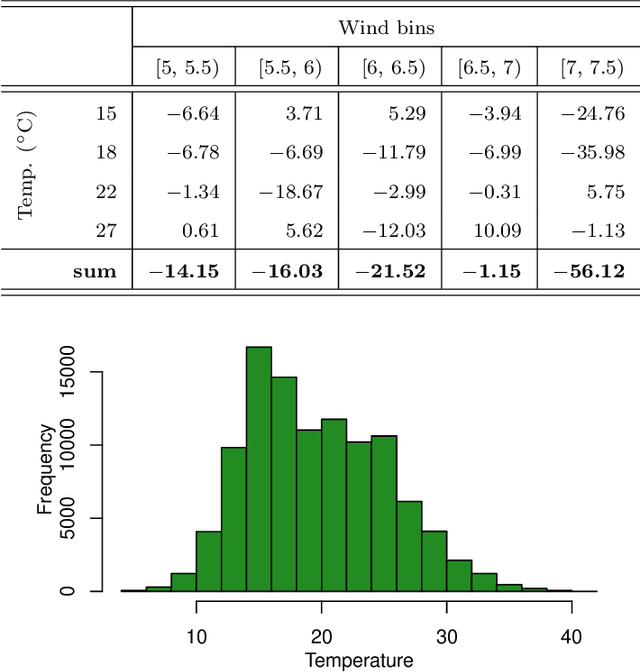
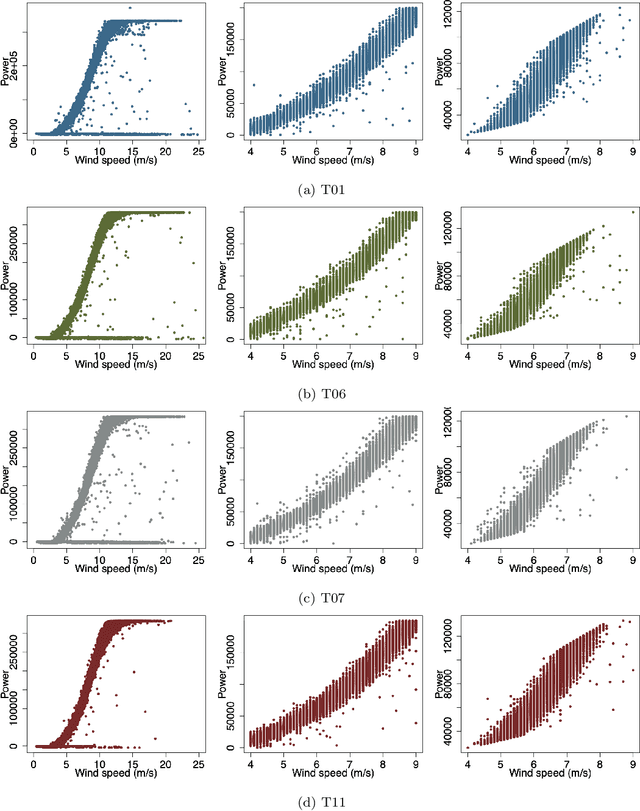
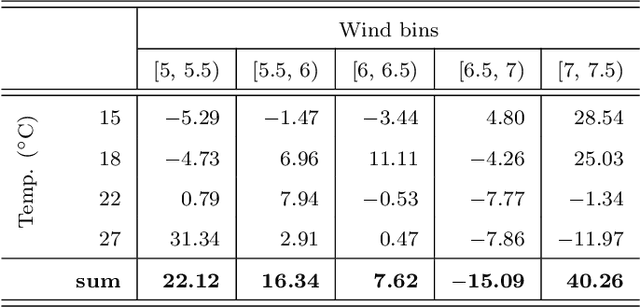
Time series processing is an essential aspect of wind turbine health monitoring. Despite the progress in this field, there is still room for new methods to improve modeling quality. In this paper, we propose two new approaches for the analysis of wind turbine health. Both approaches are based on abstract concepts, implemented using fuzzy sets, which summarize and aggregate the underlying raw data. By observing the change in concepts, we infer about the change in the turbine's health. Analyzes are carried out separately for different external conditions (wind speed and temperature). We extract concepts that represent relative low, moderate, and high power production. The first method aims at evaluating the decrease or increase in relatively high and low power production. This task is performed using a regression-like model. The second method evaluates the overall drift of the extracted concepts. Large drift indicates that the power production process undergoes fluctuations in time. Concepts are labeled using linguistic labels, thus equipping our model with improved interpretability features. We applied the proposed approach to process publicly available data describing four wind turbines. The simulation results have shown that the aging process is not homogeneous in all wind turbines.
A fuzzy-rough uncertainty measure to discover bias encoded explicitly or implicitly in features of structured pattern classification datasets
Aug 20, 2021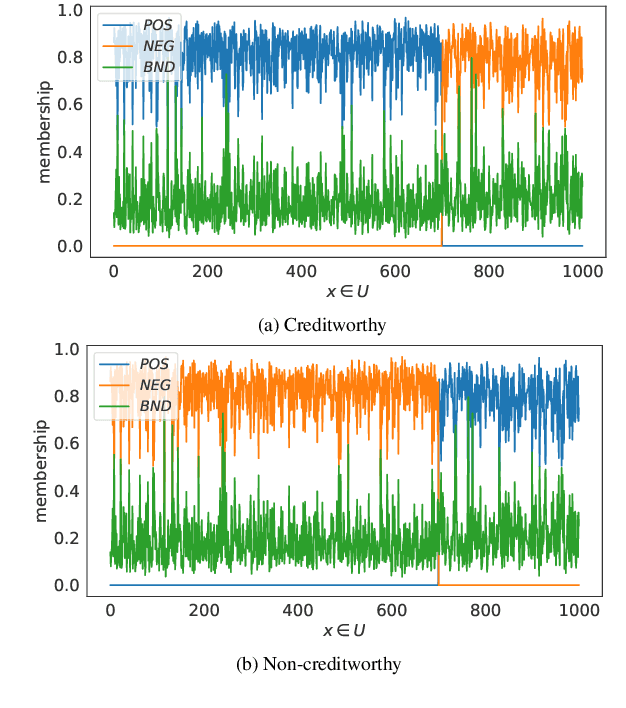

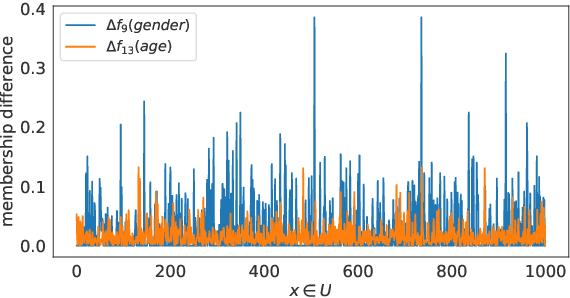
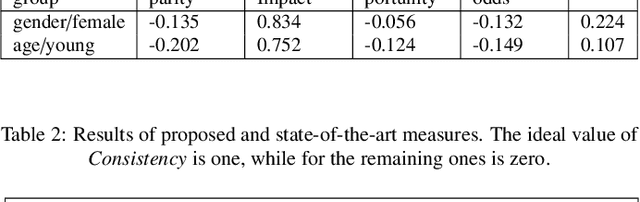
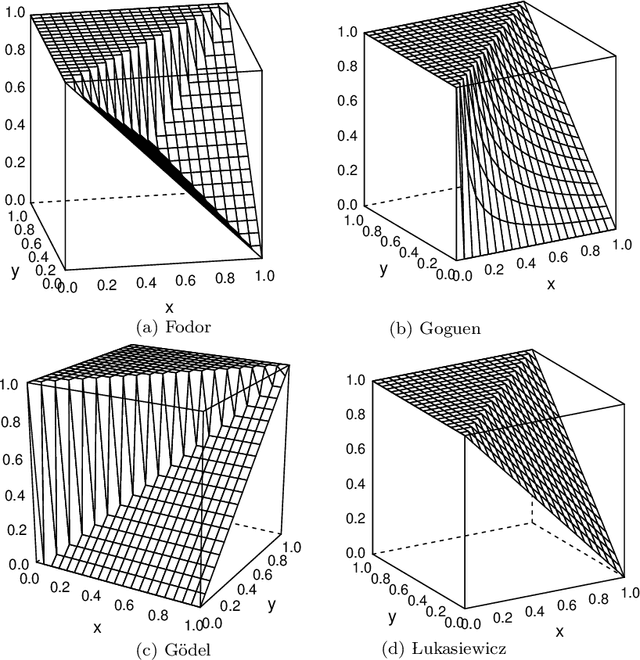
The need to measure bias encoded in tabular data that are used to solve pattern recognition problems is widely recognized by academia, legislators and enterprises alike. In previous work, we proposed a bias quantification measure, called fuzzy-rough uncer-tainty, which relies on the fuzzy-rough set theory. The intuition dictates that protected features should not change the fuzzy-rough boundary regions of a decision class significantly. The extent to which this happens is a proxy for bias expressed as uncertainty in adecision-making context. Our measure's main advantage is that it does not depend on any machine learning prediction model but adistance function. In this paper, we extend our study by exploring the existence of bias encoded implicitly in non-protected featuresas defined by the correlation between protected and unprotected attributes. This analysis leads to four scenarios that domain experts should evaluate before deciding how to tackle bias. In addition, we conduct a sensitivity analysis to determine the fuzzy operatorsand distance function that best capture change in the boundary regions.