 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompatibility of Fairness Metrics with EU Non-Discrimination Laws: Demographic Parity & Conditional Demographic Disparity
Jun 14, 2023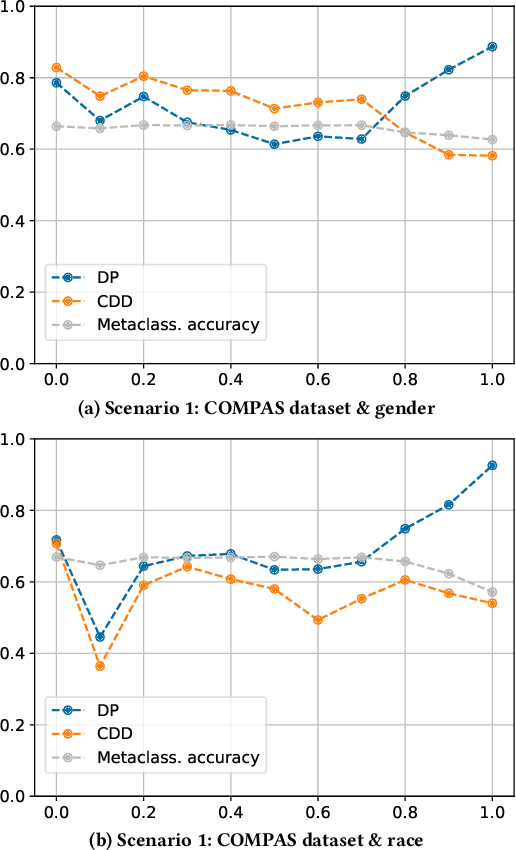
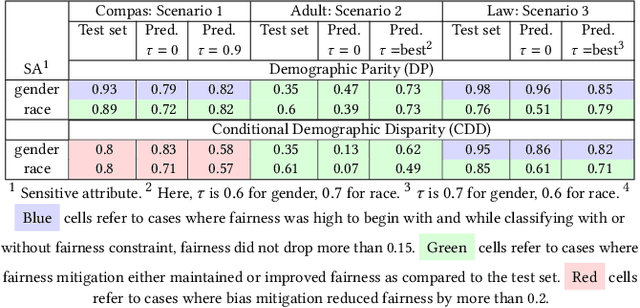
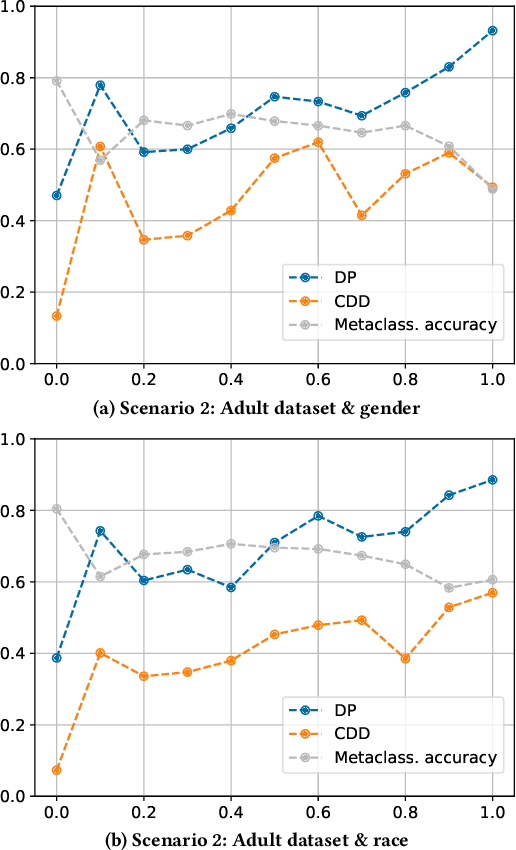
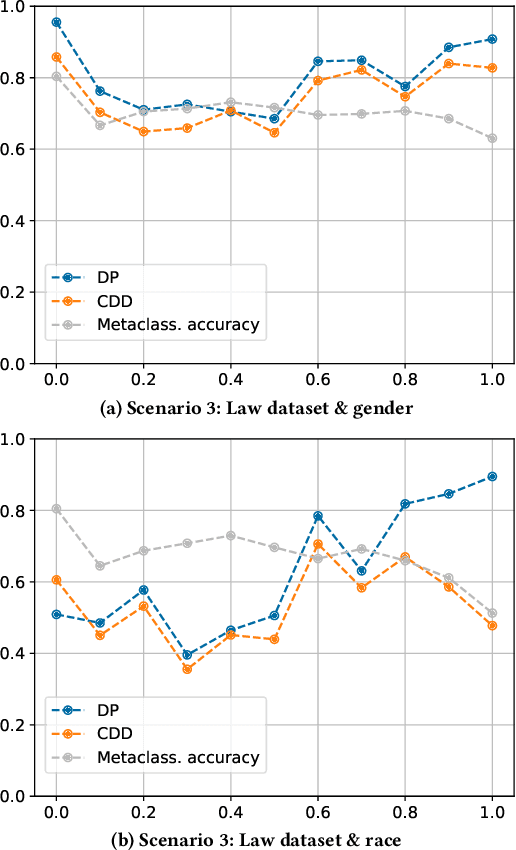
Empirical evidence suggests that algorithmic decisions driven by Machine Learning (ML) techniques threaten to discriminate against legally protected groups or create new sources of unfairness. This work supports the contextual approach to fairness in EU non-discrimination legal framework and aims at assessing up to what point we can assure legal fairness through fairness metrics and under fairness constraints. For that, we analyze the legal notion of non-discrimination and differential treatment with the fairness definition Demographic Parity (DP) through Conditional Demographic Disparity (CDD). We train and compare different classifiers with fairness constraints to assess whether it is possible to reduce bias in the prediction while enabling the contextual approach to judicial interpretation practiced under EU non-discrimination laws. Our experimental results on three scenarios show that the in-processing bias mitigation algorithm leads to different performances in each of them. Our experiments and analysis suggest that AI-assisted decision-making can be fair from a legal perspective depending on the case at hand and the legal justification. These preliminary results encourage future work which will involve further case studies, metrics, and fairness notions.
Measuring Implicit Bias Using SHAP Feature Importance and Fuzzy Cognitive Maps
May 17, 2023



In this paper, we integrate the concepts of feature importance with implicit bias in the context of pattern classification. This is done by means of a three-step methodology that involves (i) building a classifier and tuning its hyperparameters, (ii) building a Fuzzy Cognitive Map model able to quantify implicit bias, and (iii) using the SHAP feature importance to active the neural concepts when performing simulations. The results using a real case study concerning fairness research support our two-fold hypothesis. On the one hand, it is illustrated the risks of using a feature importance method as an absolute tool to measure implicit bias. On the other hand, it is concluded that the amount of bias towards protected features might differ depending on whether the features are numerically or categorically encoded.
Measuring Wind Turbine Health Using Drifting Concepts
Dec 09, 2021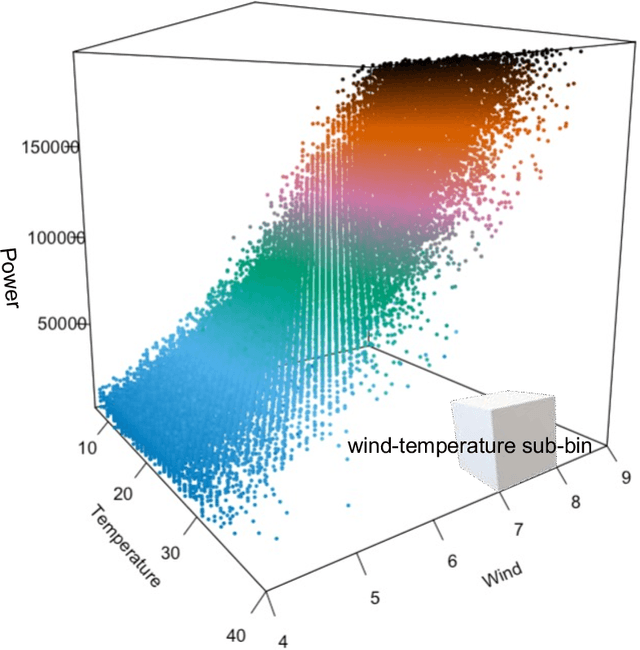
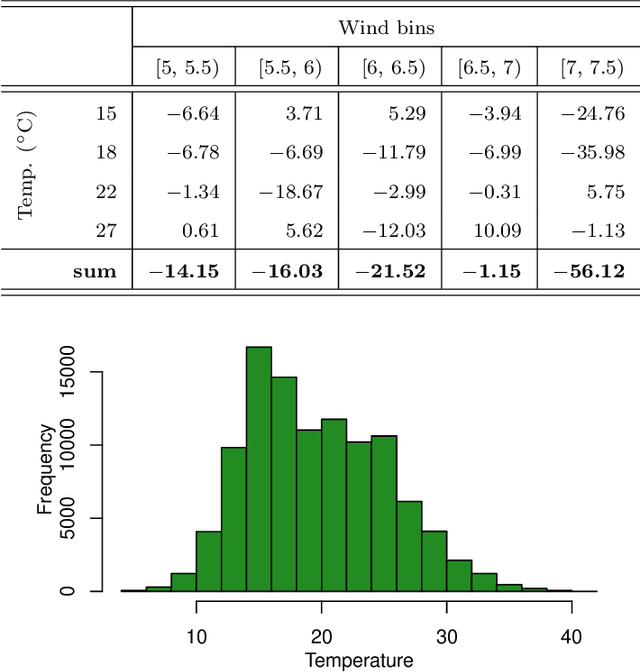
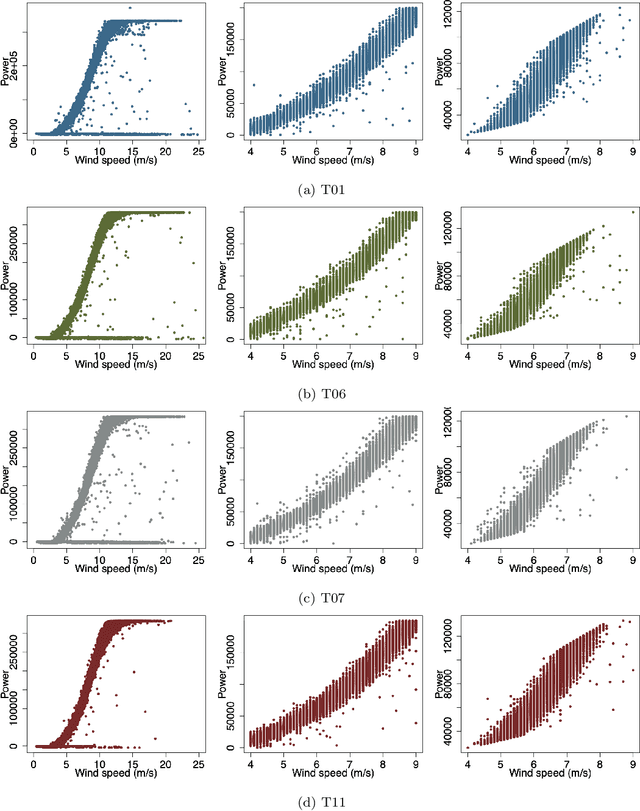
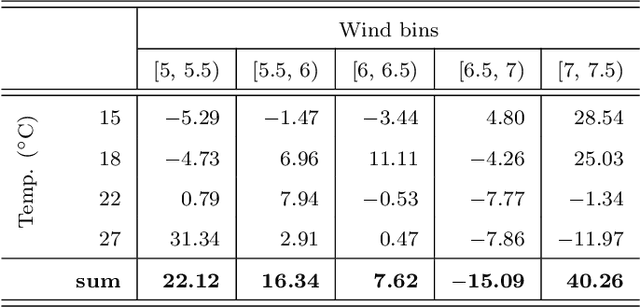
Time series processing is an essential aspect of wind turbine health monitoring. Despite the progress in this field, there is still room for new methods to improve modeling quality. In this paper, we propose two new approaches for the analysis of wind turbine health. Both approaches are based on abstract concepts, implemented using fuzzy sets, which summarize and aggregate the underlying raw data. By observing the change in concepts, we infer about the change in the turbine's health. Analyzes are carried out separately for different external conditions (wind speed and temperature). We extract concepts that represent relative low, moderate, and high power production. The first method aims at evaluating the decrease or increase in relatively high and low power production. This task is performed using a regression-like model. The second method evaluates the overall drift of the extracted concepts. Large drift indicates that the power production process undergoes fluctuations in time. Concepts are labeled using linguistic labels, thus equipping our model with improved interpretability features. We applied the proposed approach to process publicly available data describing four wind turbines. The simulation results have shown that the aging process is not homogeneous in all wind turbines.
Online learning of windmill time series using Long Short-term Cognitive Networks
Jul 01, 2021
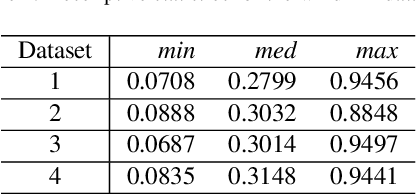

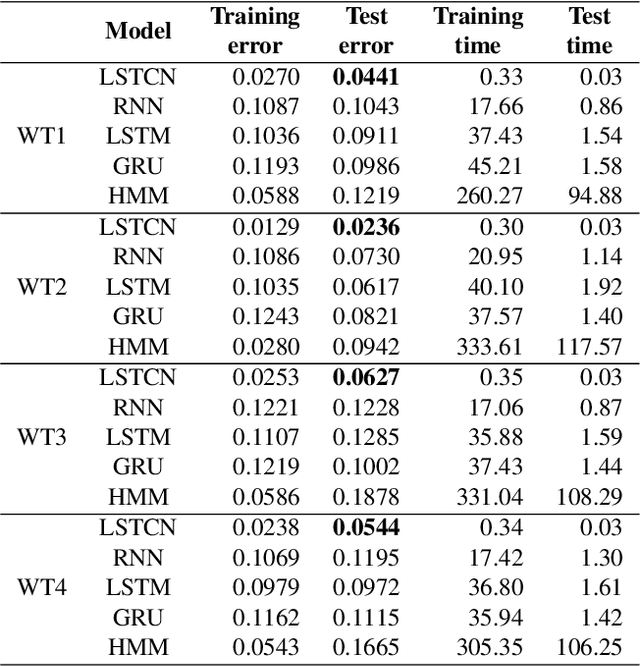
Forecasting windmill time series is often the basis of other processes such as anomaly detection, health monitoring, or maintenance scheduling. The amount of data generated on windmill farms makes online learning the most viable strategy to follow. Such settings require retraining the model each time a new batch of data is available. However, update the model with the new information is often very expensive to perform using traditional Recurrent Neural Networks (RNNs). In this paper, we use Long Short-term Cognitive Networks (LSTCNs) to forecast windmill time series in online settings. These recently introduced neural systems consist of chained Short-term Cognitive Network blocks, each processing a temporal data chunk. The learning algorithm of these blocks is based on a very fast, deterministic learning rule that makes LSTCNs suitable for online learning tasks. The numerical simulations using a case study with four windmills showed that our approach reported the lowest forecasting errors with respect to a simple RNN, a Long Short-term Memory, a Gated Recurrent Unit, and a Hidden Markov Model. What is perhaps more important is that the LSTCN approach is significantly faster than these state-of-the-art models.
Short-term Cognitive Networks, Flexible Reasoning and Nonsynaptic Learning
Sep 16, 2018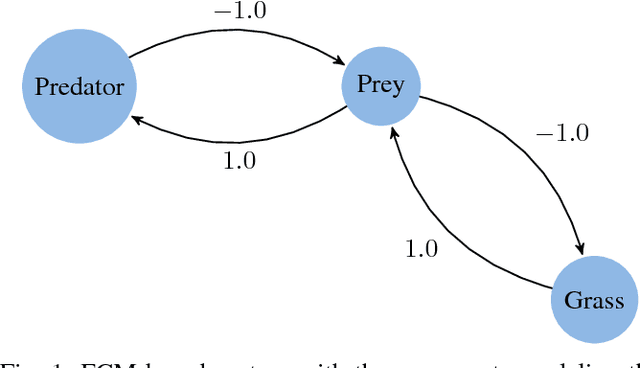
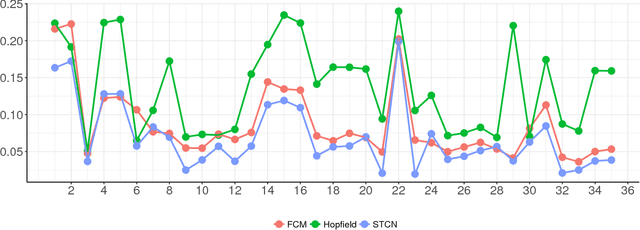

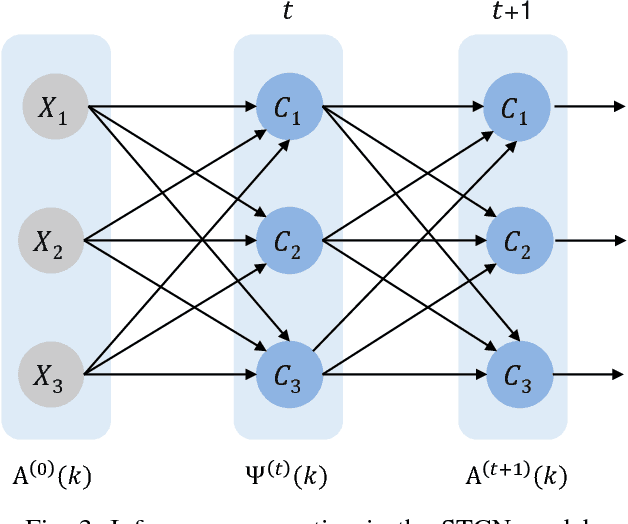
While the machine learning literature dedicated to fully automated reasoning algorithms is abundant, the number of methods enabling the inference process on the basis of previously defined knowledge structures is scanter. Fuzzy Cognitive Maps (FCMs) are neural networks that can be exploited towards this goal because of their flexibility to handle external knowledge. However, FCMs suffer from a number of issues that range from the limited prediction horizon to the absence of theoretically sound learning algorithms able to produce accurate predictions. In this paper, we propose a neural network system named Short-term Cognitive Networks that tackle some of these limitations. In our model weights are not constricted and may have a causal nature or not. As a second contribution, we present a nonsynaptic learning algorithm to improve the network performance without modifying the previously defined weights. Moreover, we derive a stop condition to prevent the learning algorithm from iterating without decreasing the simulation error.
A Data Mining Framework for Optimal Product Selection in Retail Supermarket Data: The Generalized PROFSET Model
Dec 11, 2001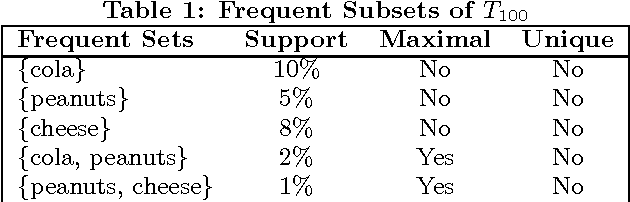
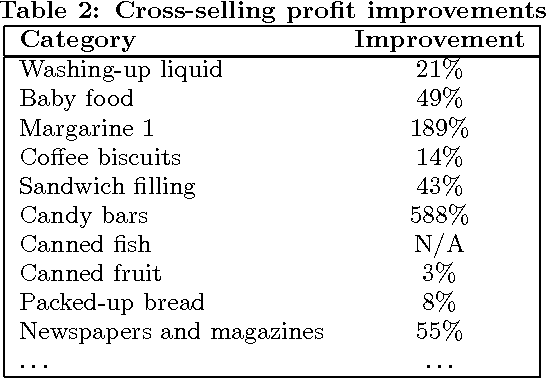

In recent years, data mining researchers have developed efficient association rule algorithms for retail market basket analysis. Still, retailers often complain about how to adopt association rules to optimize concrete retail marketing-mix decisions. It is in this context that, in a previous paper, the authors have introduced a product selection model called PROFSET. This model selects the most interesting products from a product assortment based on their cross-selling potential given some retailer defined constraints. However this model suffered from an important deficiency: it could not deal effectively with supermarket data, and no provisions were taken to include retail category management principles. Therefore, in this paper, the authors present an important generalization of the existing model in order to make it suitable for supermarket data as well, and to enable retailers to add category restrictions to the model. Experiments on real world data obtained from a Belgian supermarket chain produce very promising results and demonstrate the effectiveness of the generalized PROFSET model.