 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Do Class-Dependent Evaluation Effects Occur with Time Series Feature Attributions? A Synthetic Data Investigation
Jun 13, 2025Evaluating feature attribution methods represents a critical challenge in explainable AI (XAI), as researchers typically rely on perturbation-based metrics when ground truth is unavailable. However, recent work demonstrates that these evaluation metrics can show different performance across predicted classes within the same dataset. These "class-dependent evaluation effects" raise questions about whether perturbation analysis reliably measures attribution quality, with direct implications for XAI method development and the trustworthiness of evaluation techniques. We investigate under which conditions these class-dependent effects arise by conducting controlled experiments with synthetic time series data where ground truth feature locations are known. We systematically vary feature types and class contrasts across binary classification tasks, then compare perturbation-based degradation scores with ground truth-based precision-recall metrics using multiple attribution methods. Our experiments demonstrate that class-dependent effects emerge with both evaluation approaches even in simple scenarios with temporally localized features, triggered by basic variations in feature amplitude or temporal extent between classes. Most critically, we find that perturbation-based and ground truth metrics frequently yield contradictory assessments of attribution quality across classes, with weak correlations between evaluation approaches. These findings suggest that researchers should interpret perturbation-based metrics with care, as they may not always align with whether attributions correctly identify discriminating features. These findings reveal opportunities to reconsider what attribution evaluation actually measures and to develop more comprehensive evaluation frameworks that capture multiple dimensions of attribution quality.
Class-Dependent Perturbation Effects in Evaluating Time Series Attributions
Feb 24, 2025As machine learning models become increasingly prevalent in time series applications, Explainable Artificial Intelligence (XAI) methods are essential for understanding their predictions. Within XAI, feature attribution methods aim to identify which input features contributed the most to a model's prediction, with their evaluation typically relying on perturbation-based metrics. Through empirical analysis across multiple datasets, model architectures, and perturbation strategies, we identify important class-dependent effects in these metrics: they show varying effectiveness across classes, achieving strong results for some while remaining less sensitive to others. In particular, we find that the most effective perturbation strategies often demonstrate the most pronounced class differences. Our analysis suggests that these effects arise from the learned biases of classifiers, indicating that perturbation-based evaluation may reflect specific model behaviors rather than intrinsic attribution quality. We propose an evaluation framework with a class-aware penalty term to help assess and account for these effects in evaluating feature attributions. Although our analysis focuses on time series classification, these class-dependent effects likely extend to other structured data domains where perturbation-based evaluation is common.
Measuring Perceived Trust in XAI-Assisted Decision-Making by Eliciting a Mental Model
Jul 15, 2023



This empirical study proposes a novel methodology to measure users' perceived trust in an Explainable Artificial Intelligence (XAI) model. To do so, users' mental models are elicited using Fuzzy Cognitive Maps (FCMs). First, we exploit an interpretable Machine Learning (ML) model to classify suspected COVID-19 patients into positive or negative cases. Then, Medical Experts' (MEs) conduct a diagnostic decision-making task based on their knowledge and then prediction and interpretations provided by the XAI model. In order to evaluate the impact of interpretations on perceived trust, explanation satisfaction attributes are rated by MEs through a survey. Then, they are considered as FCM's concepts to determine their influences on each other and, ultimately, on the perceived trust. Moreover, to consider MEs' mental subjectivity, fuzzy linguistic variables are used to determine the strength of influences. After reaching the steady state of FCMs, a quantified value is obtained to measure the perceived trust of each ME. The results show that the quantified values can determine whether MEs trust or distrust the XAI model. We analyze this behavior by comparing the quantified values with MEs' performance in completing diagnostic tasks.
Measuring Implicit Bias Using SHAP Feature Importance and Fuzzy Cognitive Maps
May 17, 2023



In this paper, we integrate the concepts of feature importance with implicit bias in the context of pattern classification. This is done by means of a three-step methodology that involves (i) building a classifier and tuning its hyperparameters, (ii) building a Fuzzy Cognitive Map model able to quantify implicit bias, and (iii) using the SHAP feature importance to active the neural concepts when performing simulations. The results using a real case study concerning fairness research support our two-fold hypothesis. On the one hand, it is illustrated the risks of using a feature importance method as an absolute tool to measure implicit bias. On the other hand, it is concluded that the amount of bias towards protected features might differ depending on whether the features are numerically or categorically encoded.
Which is the best model for my data?
Oct 26, 2022In this paper, we tackle the problem of selecting the optimal model for a given structured pattern classification dataset. In this context, a model can be understood as a classifier and a hyperparameter configuration. The proposed meta-learning approach purely relies on machine learning and involves four major steps. Firstly, we present a concise collection of 62 meta-features that address the problem of information cancellation when aggregation measure values involving positive and negative measurements. Secondly, we describe two different approaches for synthetic data generation intending to enlarge the training data. Thirdly, we fit a set of pre-defined classification models for each classification problem while optimizing their hyperparameters using grid search. The goal is to create a meta-dataset such that each row denotes a multilabel instance describing a specific problem. The features of these meta-instances denote the statistical properties of the generated datasets, while the labels encode the grid search results as binary vectors such that best-performing models are positively labeled. Finally, we tackle the model selection problem with several multilabel classifiers, including a Convolutional Neural Network designed to handle tabular data. The simulation results show that our meta-learning approach can correctly predict an optimal model for 91% of the synthetic datasets and for 87% of the real-world datasets. Furthermore, we noticed that most meta-classifiers produced better results when using our meta-features. Overall, our proposal differs from other meta-learning approaches since it tackles the algorithm selection and hyperparameter tuning problems in a single step. Toward the end, we perform a feature importance analysis to determine which statistical features drive the model selection mechanism.
Modeling Implicit Bias with Fuzzy Cognitive Maps
Jan 13, 2022
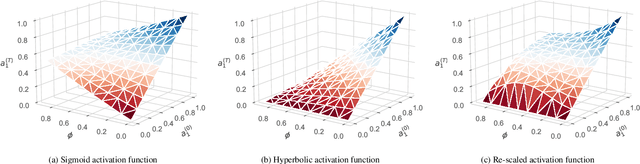
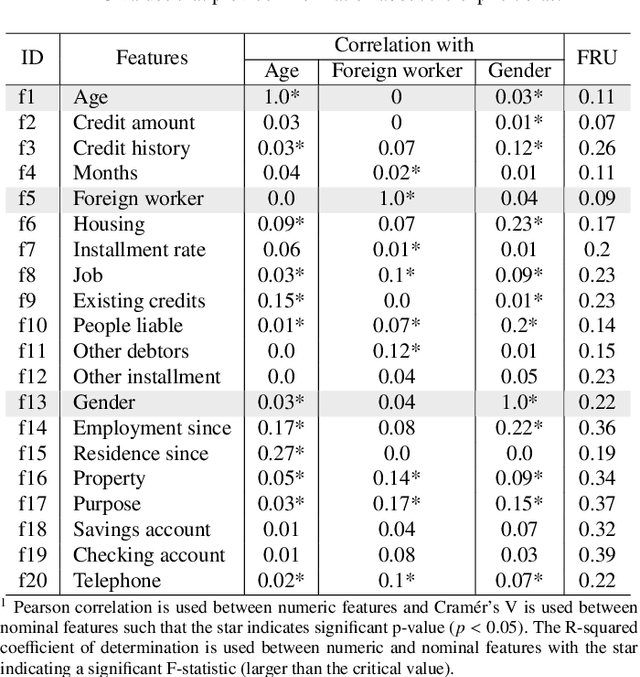
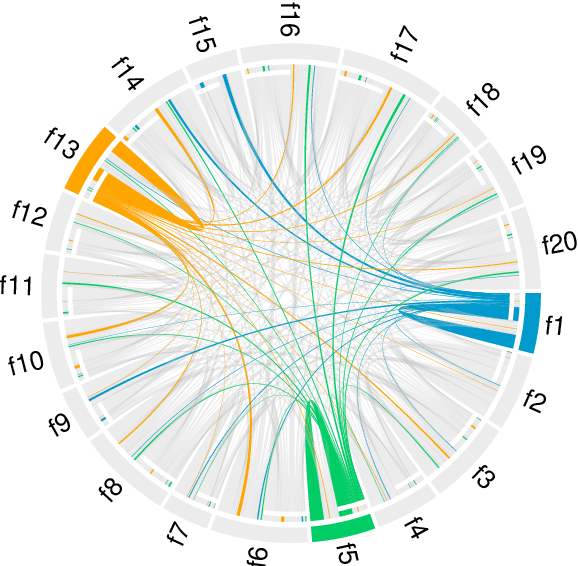
This paper presents a Fuzzy Cognitive Map model to quantify implicit bias in structured datasets where features can be numeric or discrete. In our proposal, problem features are mapped to neural concepts that are initially activated by experts when running what-if simulations, whereas weights connecting the neural concepts represent absolute correlation/association patterns between features. In addition, we introduce a new reasoning mechanism equipped with a normalization-like transfer function that prevents neurons from saturating. Another advantage of this new reasoning mechanism is that it can easily be controlled by regulating nonlinearity when updating neurons' activation values in each iteration. Finally, we study the convergence of our model and derive analytical conditions concerning the existence and unicity of fixed-point attractors.
Forward Composition Propagation for Explainable Neural Reasoning
Dec 23, 2021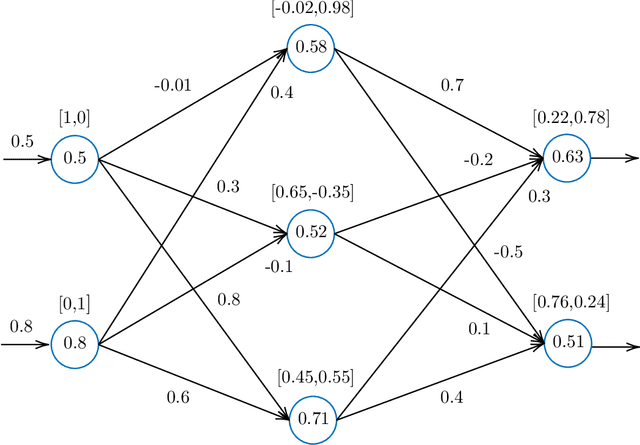
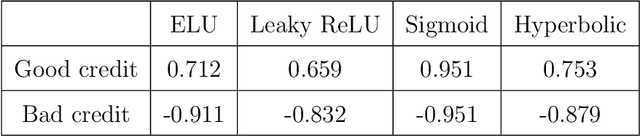
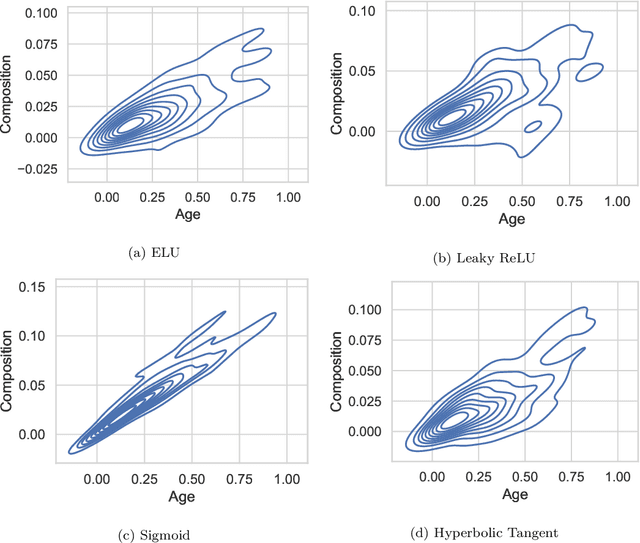
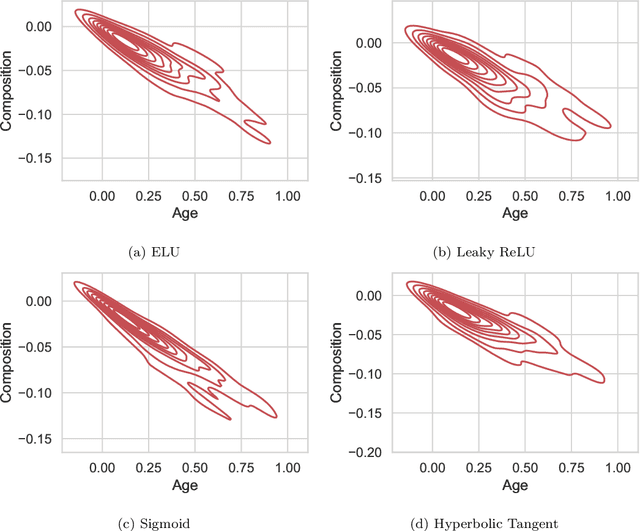
This paper proposes an algorithm called Forward Composition Propagation (FCP) to explain the predictions of feed-forward neural networks operating on structured pattern recognition problems. In the proposed FCP algorithm, each neuron is described by a composition vector indicating the role of each problem feature in that neuron. Composition vectors are initialized using a given input instance and subsequently propagated through the whole network until we reach the output layer. It is worth mentioning that the algorithm is executed once the network's training network is done. The sign of each composition value indicates whether the corresponding feature excites or inhibits the neuron, while the absolute value quantifies such an impact. Aiming to validate the FCP algorithm's correctness, we develop a case study concerning bias detection in a state-of-the-art problem in which the ground truth is known. The simulation results show that the composition values closely align with the expected behavior of protected features.
Recurrence-Aware Long-Term Cognitive Network for Explainable Pattern Classification
Jul 07, 2021
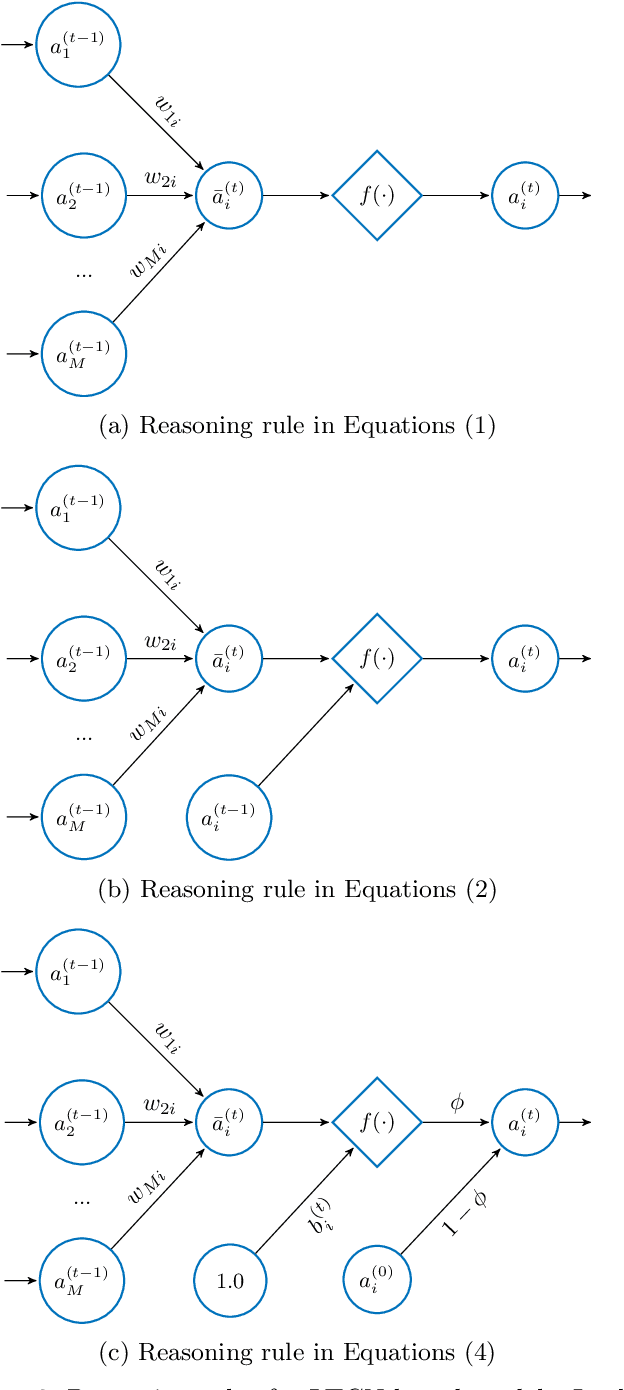
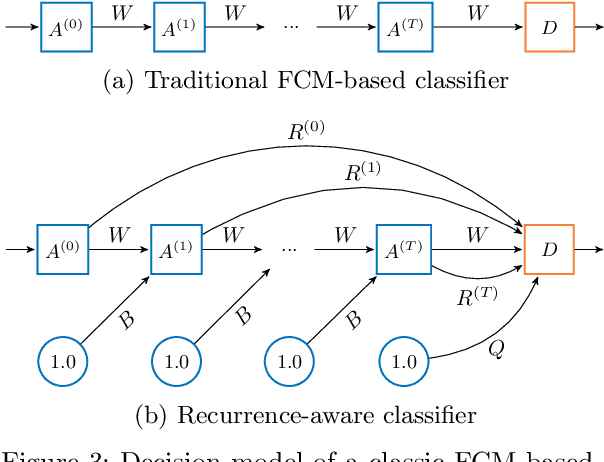
Machine learning solutions for pattern classification problems are nowadays widely deployed in society and industry. However, the lack of transparency and accountability of most accurate models often hinders their meaningful and safe use. Thus, there is a clear need for developing explainable artificial intelligence mechanisms. There exist model-agnostic methods that summarize feature contributions, but their interpretability is limited to specific predictions made by black-box models. An open challenge is to develop models that have intrinsic interpretability and produce their own explanations, even for classes of models that are traditionally considered black boxes like (recurrent) neural networks. In this paper, we propose an LTCN-based model for interpretable pattern classification of structured data. Our method brings its own mechanism for providing explanations by quantifying the relevance of each feature in the decision process. For supporting the interpretability without affecting the performance, the model incorporates more flexibility through a quasi-nonlinear reasoning rule that allows controlling nonlinearity. Besides, we propose a recurrence-aware decision model that evades the issues posed by unique fixed points while introducing a deterministic learning method to compute the learnable parameters. The simulations show that our interpretable model obtains competitive performance when compared to the state-of-the-art white and black boxes.
Long Short-term Cognitive Networks
Jun 30, 2021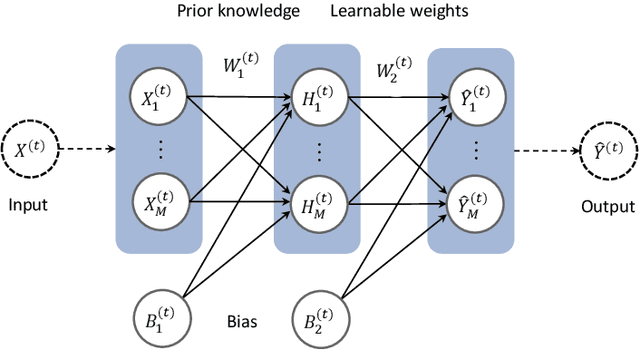
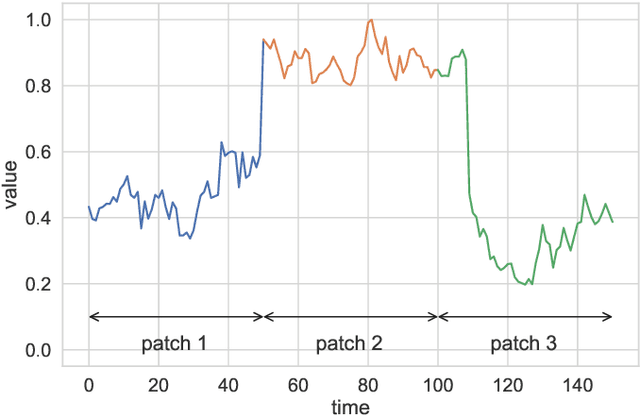
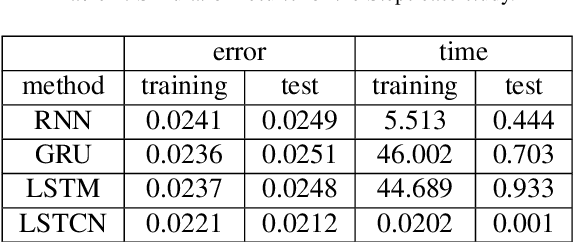
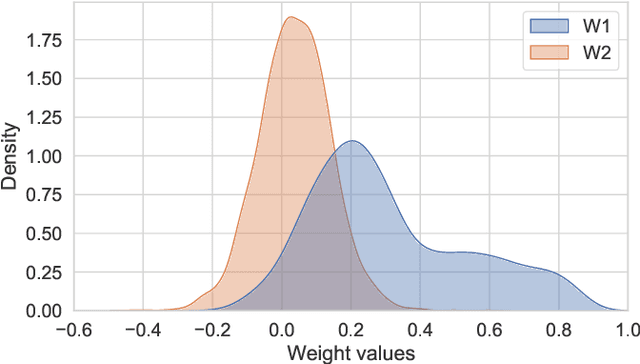
In this paper, we present a recurrent neural system named Long Short-term Cognitive Networks (LSTCNs) as a generalisation of the Short-term Cognitive Network (STCN) model. Such a generalisation is motivated by the difficulty of forecasting very long time series in an efficient, greener fashion. The LSTCN model can be defined as a collection of STCN blocks, each processing a specific time patch of the (multivariate) time series being modelled. In this neural ensemble, each block passes information to the subsequent one in the form of a weight matrix referred to as the prior knowledge matrix. As a second contribution, we propose a deterministic learning algorithm to compute the learnable weights while preserving the prior knowledge resulting from previous learning processes. As a third contribution, we introduce a feature influence score as a proxy to explain the forecasting process in multivariate time series. The simulations using three case studies show that our neural system reports small forecasting errors while being up to thousands of times faster than state-of-the-art recurrent models.
An interpretable semi-supervised classifier using two different strategies for amended self-labeling
Jan 26, 2020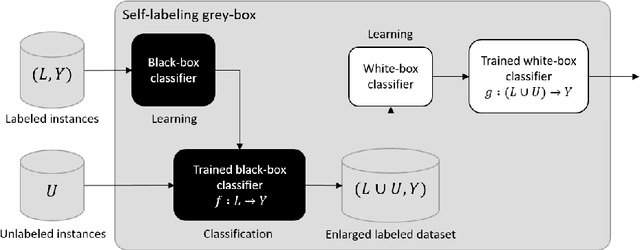
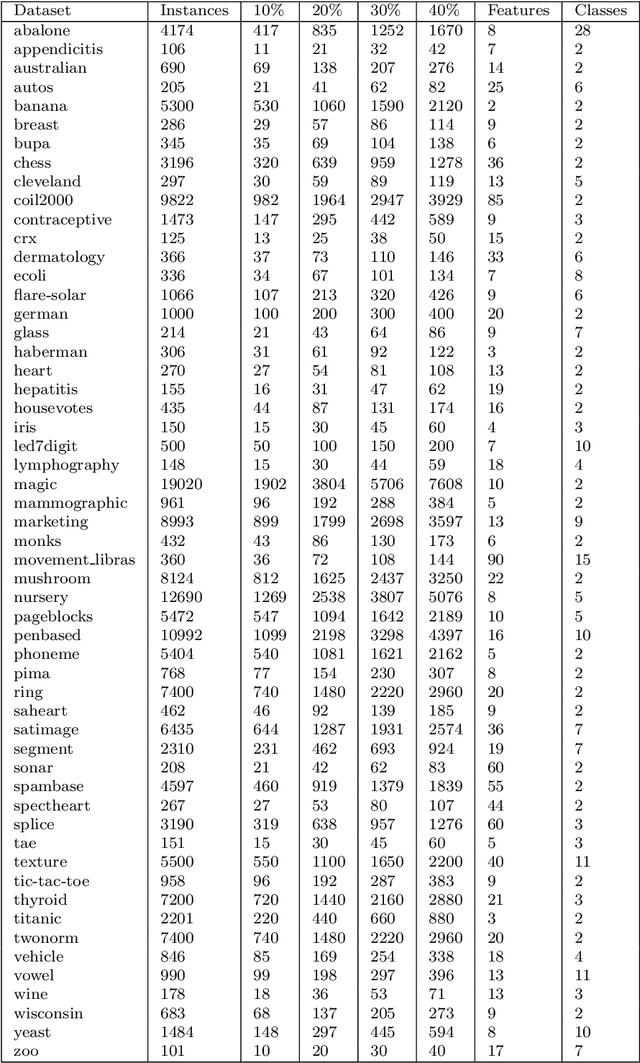
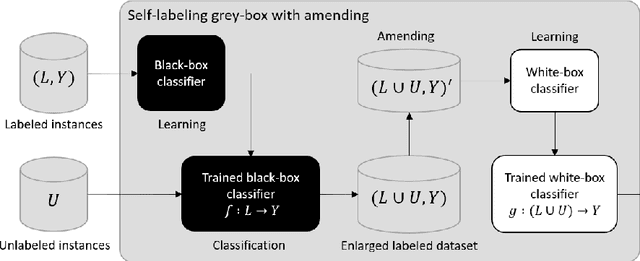
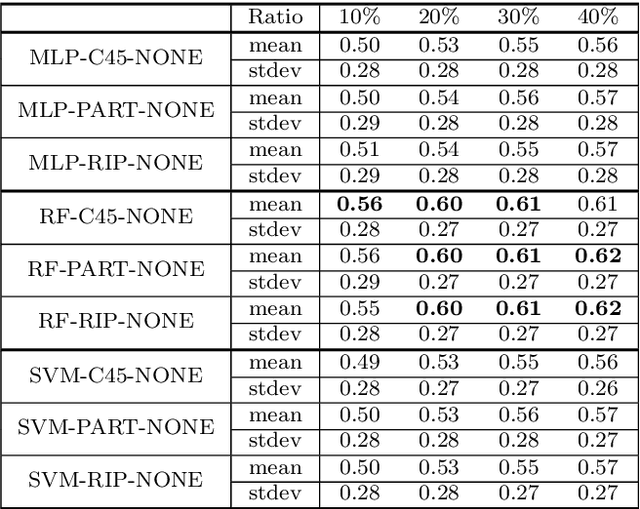
In the context of some machine learning applications, obtaining data instances is a relatively easy process but labeling them could become quite expensive or tedious. Such scenarios lead to datasets with few labeled instances and a larger number of unlabeled ones. Semi-supervised classification techniques combine labeled and unlabeled data during the learning phase in order to increase classifier's generalization capability. Regrettably, most successful semi-supervised classifiers do not allow explaining their outcome, thus behaving like black boxes. However, there is an increasing number of problem domains in which experts demand a clear understanding of the decision process. In this paper, we report on an extended experimental study presenting an interpretable self-labeling grey-box classifier that uses a black box to estimate the missing class labels and a white box to make the final predictions. Two different approaches for amending the self-labeling process are explored: a first one based on the confidence of the black box and the latter one based on measures from Rough Set Theory. The results of the extended experimental study support the interpretability by means of transparency and simplicity of our classifier, while attaining superior prediction rates when compared with state-of-the-art self-labeling classifiers reported in the literature.