 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimistic Reinforcement Learning-Based Skill Insertions for Task and Motion Planning
Oct 15, 2025Task and motion planning (TAMP) for robotics manipulation necessitates long-horizon reasoning involving versatile actions and skills. While deterministic actions can be crafted by sampling or optimizing with certain constraints, planning actions with uncertainty, i.e., probabilistic actions, remains a challenge for TAMP. On the contrary, Reinforcement Learning (RL) excels in acquiring versatile, yet short-horizon, manipulation skills that are robust with uncertainties. In this letter, we design a method that integrates RL skills into TAMP pipelines. Besides the policy, a RL skill is defined with data-driven logical components that enable the skill to be deployed by symbolic planning. A plan refinement sub-routine is designed to further tackle the inevitable effect uncertainties. In the experiments, we compare our method with baseline hierarchical planning from both TAMP and RL fields and illustrate the strength of the method. The results show that by embedding RL skills, we extend the capability of TAMP to domains with probabilistic skills, and improve the planning efficiency compared to the previous methods.
A Task-Efficient Reinforcement Learning Task-Motion Planner for Safe Human-Robot Cooperation
Oct 14, 2025In a Human-Robot Cooperation (HRC) environment, safety and efficiency are the two core properties to evaluate robot performance. However, safety mechanisms usually hinder task efficiency since human intervention will cause backup motions and goal failures of the robot. Frequent motion replanning will increase the computational load and the chance of failure. In this paper, we present a hybrid Reinforcement Learning (RL) planning framework which is comprised of an interactive motion planner and a RL task planner. The RL task planner attempts to choose statistically safe and efficient task sequences based on the feedback from the motion planner, while the motion planner keeps the task execution process collision-free by detecting human arm motions and deploying new paths when the previous path is not valid anymore. Intuitively, the RL agent will learn to avoid dangerous tasks, while the motion planner ensures that the chosen tasks are safe. The proposed framework is validated on the cobot in both simulation and the real world, we compare the planner with hard-coded task motion planning methods. The results show that our planning framework can 1) react to uncertain human motions at both joint and task levels; 2) reduce the times of repeating failed goal commands; 3) reduce the total number of replanning requests.
An interpretable semi-supervised classifier using two different strategies for amended self-labeling
Jan 26, 2020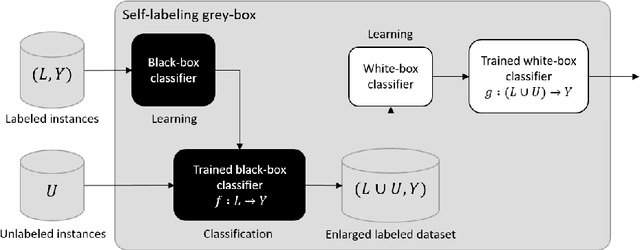
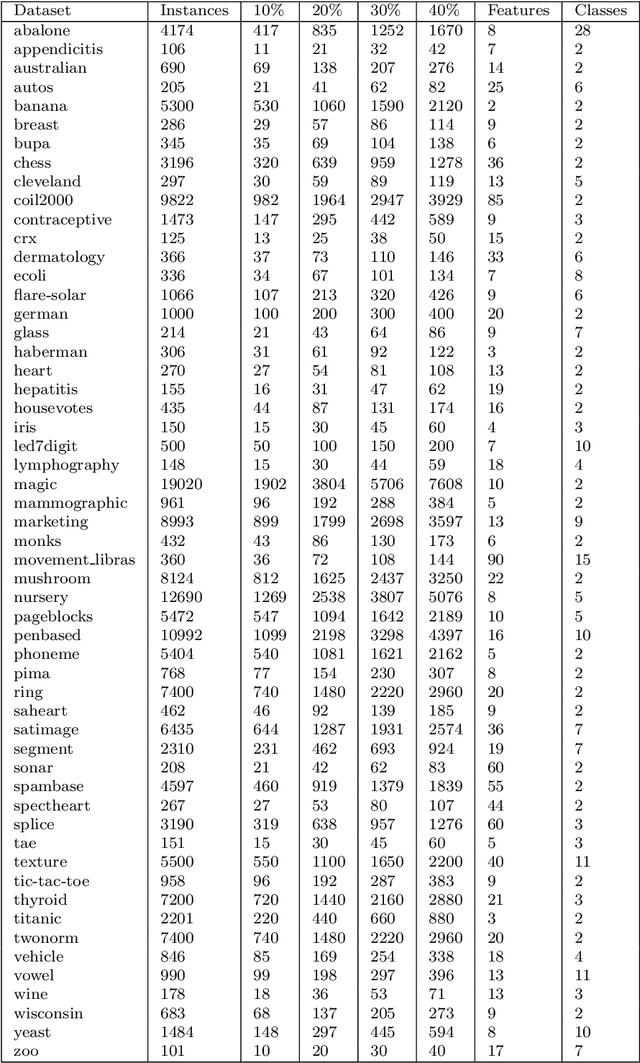
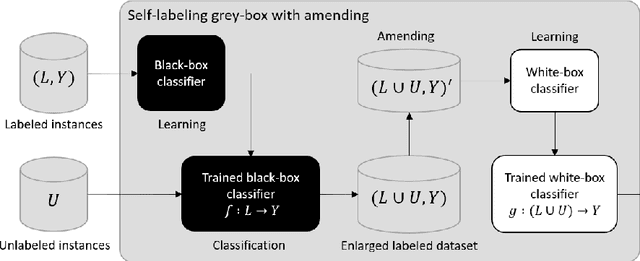
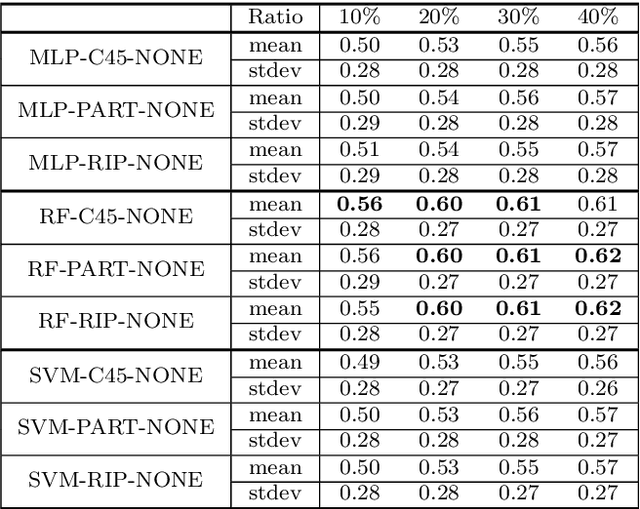
In the context of some machine learning applications, obtaining data instances is a relatively easy process but labeling them could become quite expensive or tedious. Such scenarios lead to datasets with few labeled instances and a larger number of unlabeled ones. Semi-supervised classification techniques combine labeled and unlabeled data during the learning phase in order to increase classifier's generalization capability. Regrettably, most successful semi-supervised classifiers do not allow explaining their outcome, thus behaving like black boxes. However, there is an increasing number of problem domains in which experts demand a clear understanding of the decision process. In this paper, we report on an extended experimental study presenting an interpretable self-labeling grey-box classifier that uses a black box to estimate the missing class labels and a white box to make the final predictions. Two different approaches for amending the self-labeling process are explored: a first one based on the confidence of the black box and the latter one based on measures from Rough Set Theory. The results of the extended experimental study support the interpretability by means of transparency and simplicity of our classifier, while attaining superior prediction rates when compared with state-of-the-art self-labeling classifiers reported in the literature.
Learning with Options that Terminate Off-Policy
Dec 02, 2017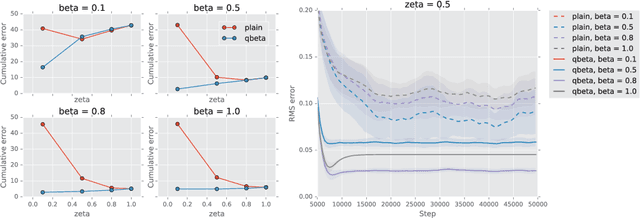
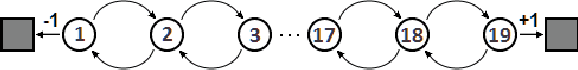
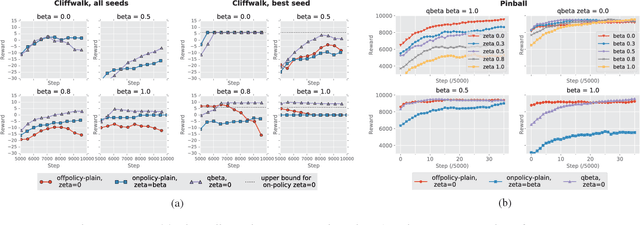
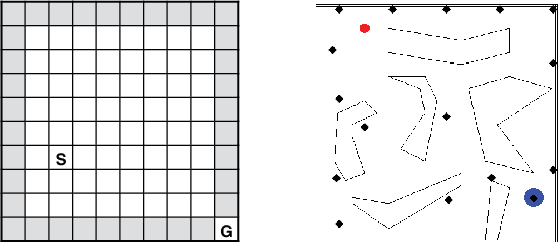
A temporally abstract action, or an option, is specified by a policy and a termination condition: the policy guides option behavior, and the termination condition roughly determines its length. Generally, learning with longer options (like learning with multi-step returns) is known to be more efficient. However, if the option set for the task is not ideal, and cannot express the primitive optimal policy exactly, shorter options offer more flexibility and can yield a better solution. Thus, the termination condition puts learning efficiency at odds with solution quality. We propose to resolve this dilemma by decoupling the behavior and target terminations, just like it is done with policies in off-policy learning. To this end, we give a new algorithm, Q(\beta), that learns the solution with respect to any termination condition, regardless of how the options actually terminate. We derive Q(\beta) by casting learning with options into a common framework with well-studied multi-step off-policy learning. We validate our algorithm empirically, and show that it holds up to its motivating claims.
Off-Policy Reward Shaping with Ensembles
Mar 23, 2015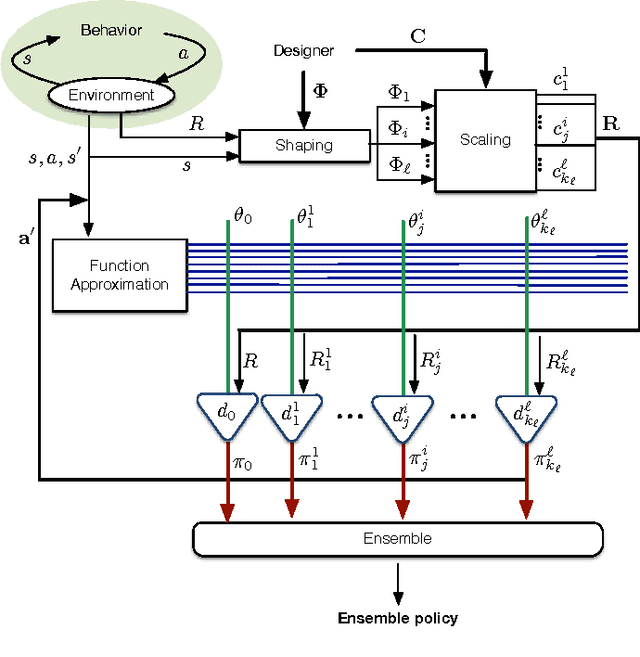
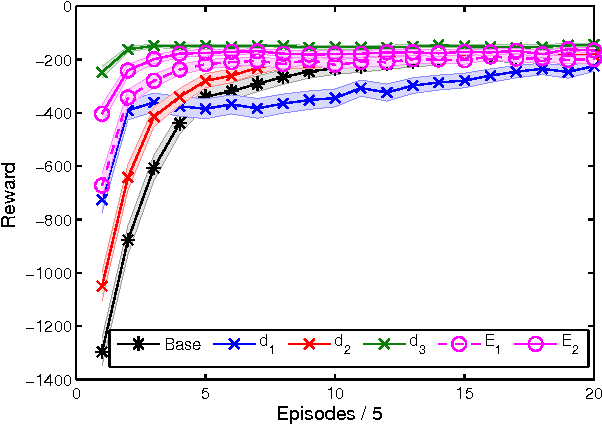
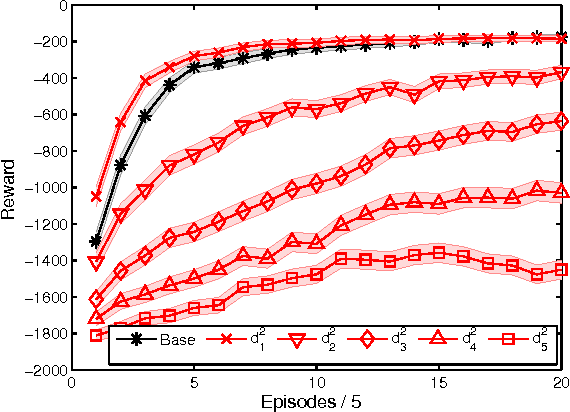
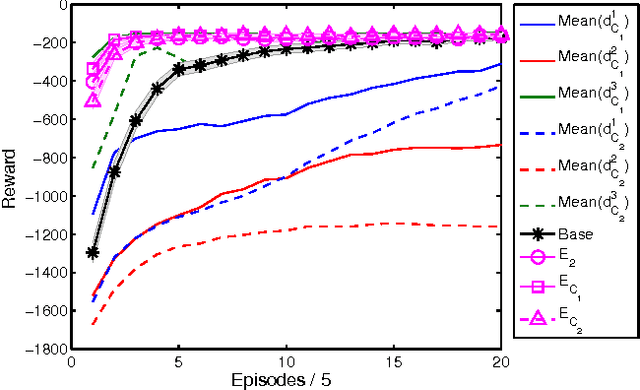
Potential-based reward shaping (PBRS) is an effective and popular technique to speed up reinforcement learning by leveraging domain knowledge. While PBRS is proven to always preserve optimal policies, its effect on learning speed is determined by the quality of its potential function, which, in turn, depends on both the underlying heuristic and the scale. Knowing which heuristic will prove effective requires testing the options beforehand, and determining the appropriate scale requires tuning, both of which introduce additional sample complexity. We formulate a PBRS framework that reduces learning speed, but does not incur extra sample complexity. For this, we propose to simultaneously learn an ensemble of policies, shaped w.r.t. many heuristics and on a range of scales. The target policy is then obtained by voting. The ensemble needs to be able to efficiently and reliably learn off-policy: requirements fulfilled by the recent Horde architecture, which we take as our basis. We demonstrate empirically that (1) our ensemble policy outperforms both the base policy, and its single-heuristic components, and (2) an ensemble over a general range of scales performs at least as well as one with optimally tuned components.
Off-Policy Shaping Ensembles in Reinforcement Learning
May 21, 2014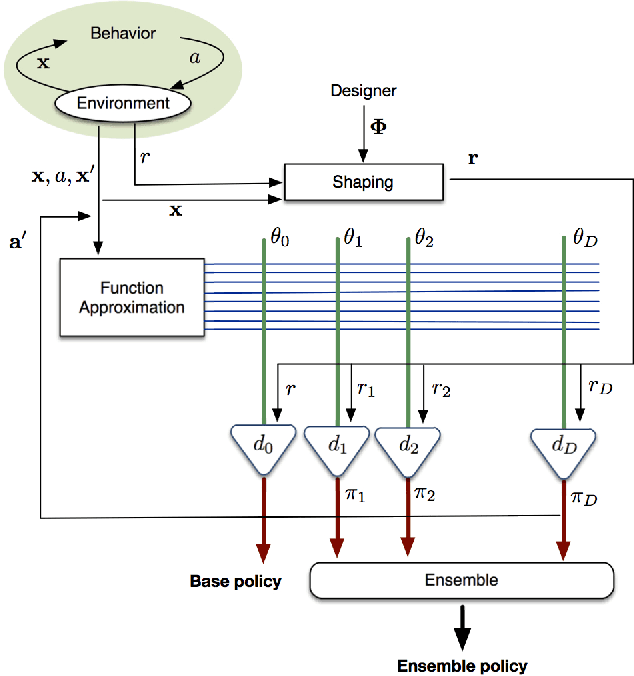


Recent advances of gradient temporal-difference methods allow to learn off-policy multiple value functions in parallel with- out sacrificing convergence guarantees or computational efficiency. This opens up new possibilities for sound ensemble techniques in reinforcement learning. In this work we propose learning an ensemble of policies related through potential-based shaping rewards. The ensemble induces a combination policy by using a voting mechanism on its components. Learning happens in real time, and we empirically show the combination policy to outperform the individual policies of the ensemble.