 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Conceptual Framework for Externally-influenced Agents: An Assisted Reinforcement Learning Review
Jul 03, 2020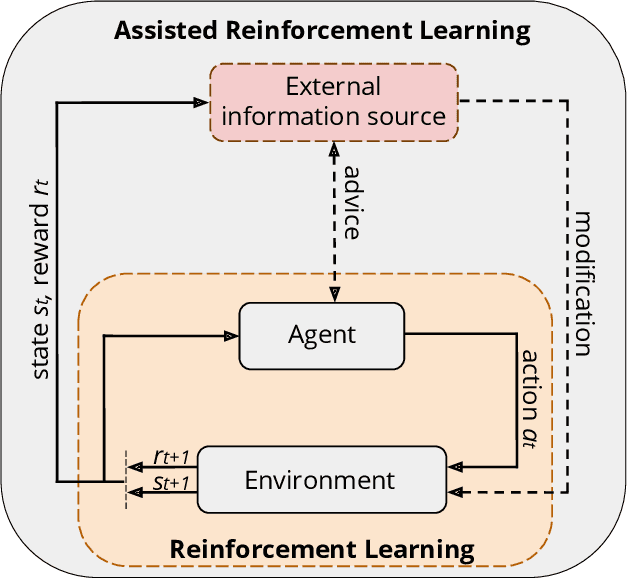
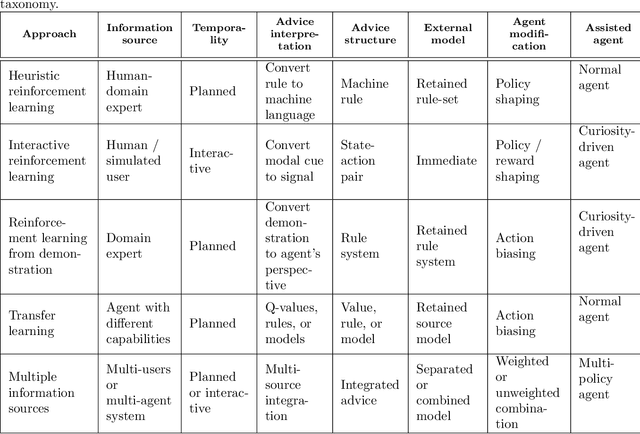
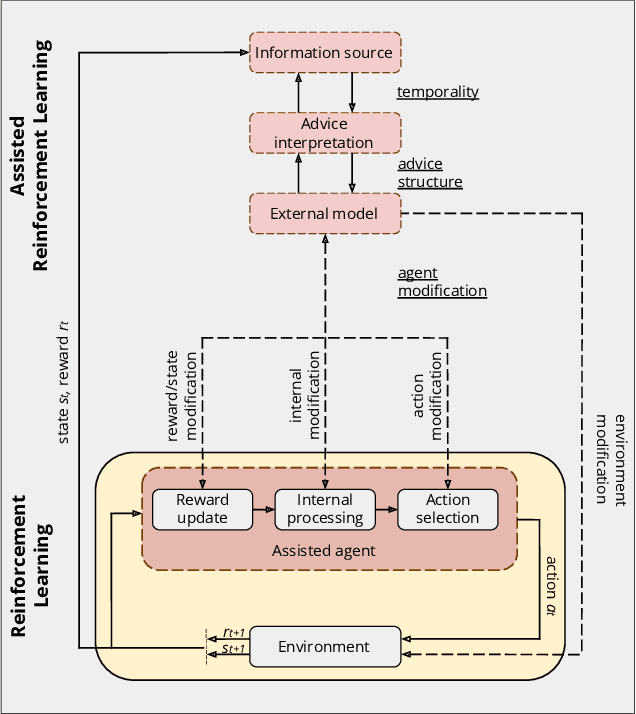
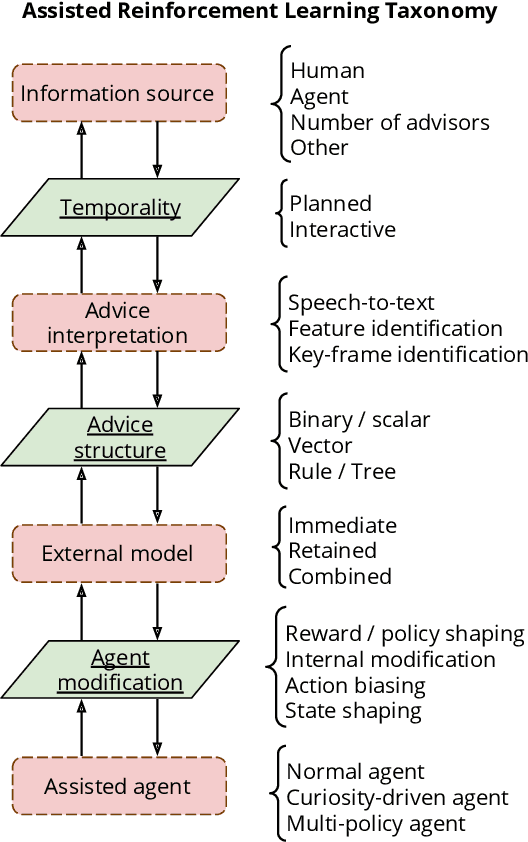
A long-term goal of reinforcement learning agents is to be able to perform tasks in complex real-world scenarios. The use of external information is one way of scaling agents to more complex problems. However, there is a general lack of collaboration or interoperability between different approaches using external information. In this work, we propose a conceptual framework and taxonomy for assisted reinforcement learning, aimed at fostering such collaboration by classifying and comparing various methods that use external information in the learning process. The proposed taxonomy details the relationship between the external information source and the learner agent, highlighting the process of information decomposition, structure, retention, and how it can be used to influence agent learning. As well as reviewing state-of-the-art methods, we identify current streams of reinforcement learning that use external information in order to improve the agent's performance and its decision-making process. These include heuristic reinforcement learning, interactive reinforcement learning, learning from demonstration, transfer learning, and learning from multiple sources, among others. These streams of reinforcement learning operate with the shared objective of scaffolding the learner agent. Lastly, we discuss further possibilities for future work in the field of assisted reinforcement learning systems.
Directed Policy Gradient for Safe Reinforcement Learning with Human Advice
Aug 13, 2018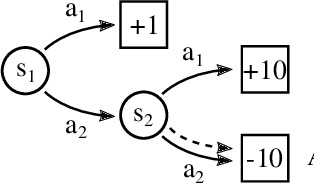


Many currently deployed Reinforcement Learning agents work in an environment shared with humans, be them co-workers, users or clients. It is desirable that these agents adjust to people's preferences, learn faster thanks to their help, and act safely around them. We argue that most current approaches that learn from human feedback are unsafe: rewarding or punishing the agent a-posteriori cannot immediately prevent it from wrong-doing. In this paper, we extend Policy Gradient to make it robust to external directives, that would otherwise break the fundamentally on-policy nature of Policy Gradient. Our technique, Directed Policy Gradient (DPG), allows a teacher or backup policy to override the agent before it acts undesirably, while allowing the agent to leverage human advice or directives to learn faster. Our experiments demonstrate that DPG makes the agent learn much faster than reward-based approaches, while requiring an order of magnitude less advice.
Using PCA to Efficiently Represent State Spaces
Jun 03, 2015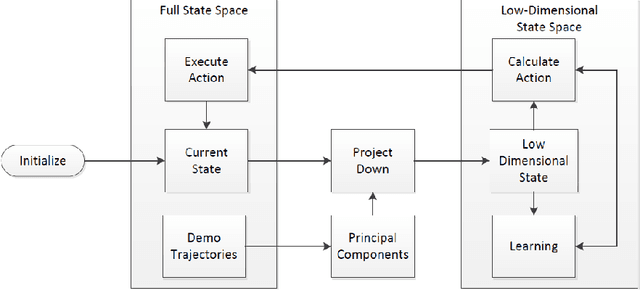
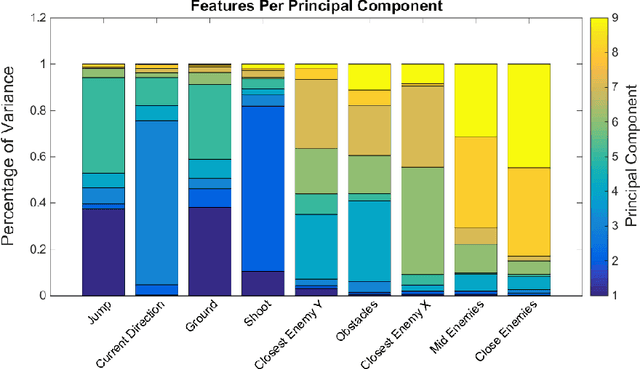

Reinforcement learning algorithms need to deal with the exponential growth of states and actions when exploring optimal control in high-dimensional spaces. This is known as the curse of dimensionality. By projecting the agent's state onto a low-dimensional manifold, we can represent the state space in a smaller and more efficient representation. By using this representation during learning, the agent can converge to a good policy much faster. We test this approach in the Mario Benchmarking Domain. When using dimensionality reduction in Mario, learning converges much faster to a good policy. But, there is a critical convergence-performance trade-off. By projecting onto a low-dimensional manifold, we are ignoring important data. In this paper, we explore this trade-off of convergence and performance. We find that learning in as few as 4 dimensions (instead of 9), we can improve performance past learning in the full dimensional space at a faster convergence rate.
Off-Policy Reward Shaping with Ensembles
Mar 23, 2015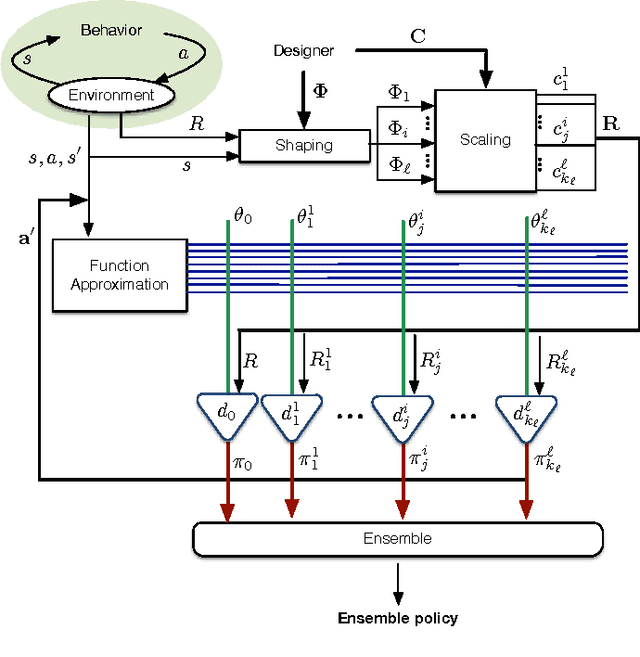
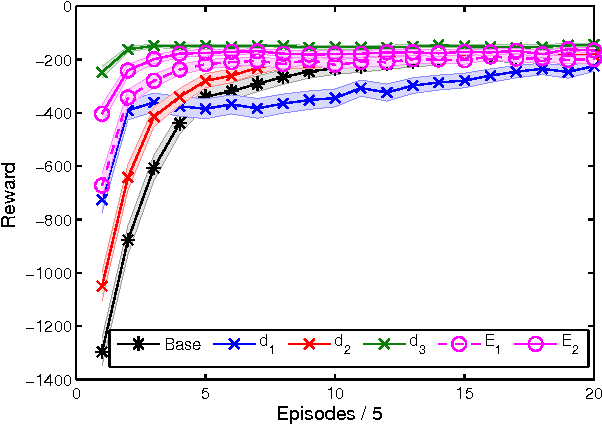
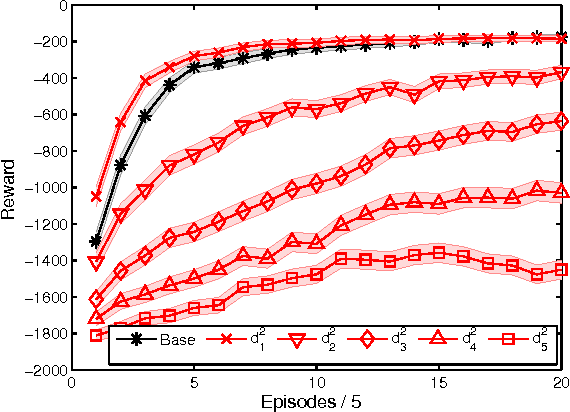
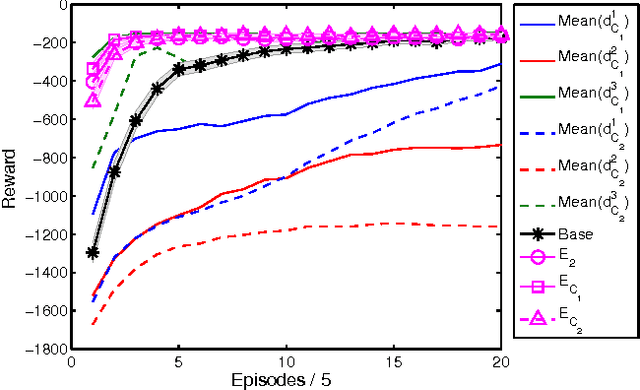
Potential-based reward shaping (PBRS) is an effective and popular technique to speed up reinforcement learning by leveraging domain knowledge. While PBRS is proven to always preserve optimal policies, its effect on learning speed is determined by the quality of its potential function, which, in turn, depends on both the underlying heuristic and the scale. Knowing which heuristic will prove effective requires testing the options beforehand, and determining the appropriate scale requires tuning, both of which introduce additional sample complexity. We formulate a PBRS framework that reduces learning speed, but does not incur extra sample complexity. For this, we propose to simultaneously learn an ensemble of policies, shaped w.r.t. many heuristics and on a range of scales. The target policy is then obtained by voting. The ensemble needs to be able to efficiently and reliably learn off-policy: requirements fulfilled by the recent Horde architecture, which we take as our basis. We demonstrate empirically that (1) our ensemble policy outperforms both the base policy, and its single-heuristic components, and (2) an ensemble over a general range of scales performs at least as well as one with optimally tuned components.
Off-Policy Shaping Ensembles in Reinforcement Learning
May 21, 2014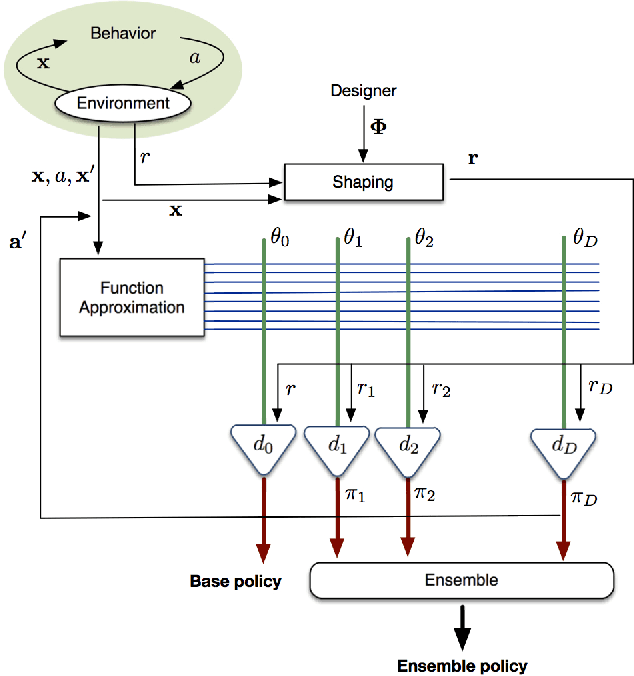


Recent advances of gradient temporal-difference methods allow to learn off-policy multiple value functions in parallel with- out sacrificing convergence guarantees or computational efficiency. This opens up new possibilities for sound ensemble techniques in reinforcement learning. In this work we propose learning an ensemble of policies related through potential-based shaping rewards. The ensemble induces a combination policy by using a voting mechanism on its components. Learning happens in real time, and we empirically show the combination policy to outperform the individual policies of the ensemble.