 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferring Multiple Policies to Hotstart Reinforcement Learning in an Air Compressor Management Problem
Jan 30, 2023Many instances of similar or almost-identical industrial machines or tools are often deployed at once, or in quick succession. For instance, a particular model of air compressor may be installed at hundreds of customers. Because these tools perform distinct but highly similar tasks, it is interesting to be able to quickly produce a high-quality controller for machine $N+1$ given the controllers already produced for machines $1..N$. This is even more important when the controllers are learned through Reinforcement Learning, as training takes time, energy and other resources. In this paper, we apply Policy Intersection, a Policy Shaping method, to help a Reinforcement Learning agent learn to solve a new variant of a compressors control problem faster, by transferring knowledge from several previously learned controllers. We show that our approach outperforms loading an old controller, and significantly improves performance in the long run.
Transfer Learning Across Simulated Robots With Different Sensors
Jul 18, 2019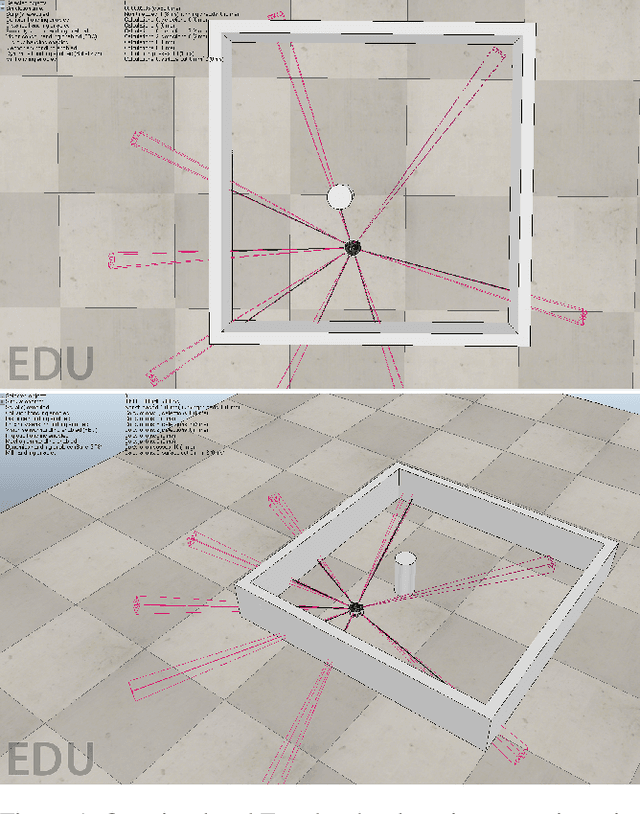
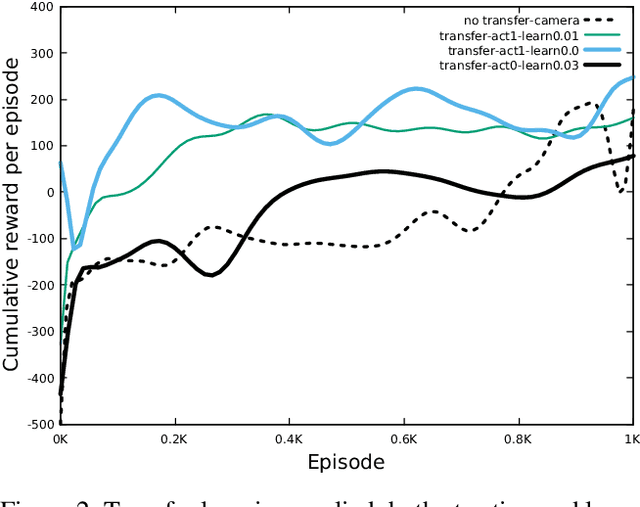
For a robot to learn a good policy, it often requires expensive equipment (such as sophisticated sensors) and a prepared training environment conducive to learning. However, it is seldom possible to perfectly equip robots for economic reasons, nor to guarantee ideal learning conditions, when deployed in real-life environments. A solution would be to prepare the robot in the lab environment, when all necessary material is available to learn a good policy. After training in the lab, the robot should be able to get by without the expensive equipment that used to be available to it, and yet still be guaranteed to perform well on the field. The transition between the lab (source) and the real-world environment (target) is related to transfer learning, where the state-space between the source and target tasks differ. We tackle a simulated task with continuous states and discrete actions presenting this challenge, using Bootstrapped Dual Policy Iteration, a model-free actor-critic reinforcement learning algorithm, and Policy Shaping. Specifically, we train a BDPI agent, embodied by a virtual robot performing a task in the V-Rep simulator, sensing its environment through several proximity sensors. The resulting policy is then used by a second agent learning the same task in the same environment, but with camera images as input. The goal is to obtain a policy able to perform the task relying on merely camera images.
Sample-Efficient Model-Free Reinforcement Learning with Off-Policy Critics
Mar 11, 2019
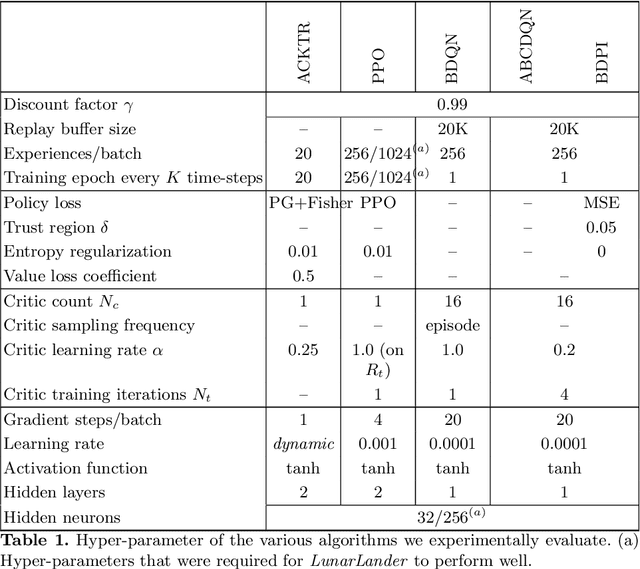
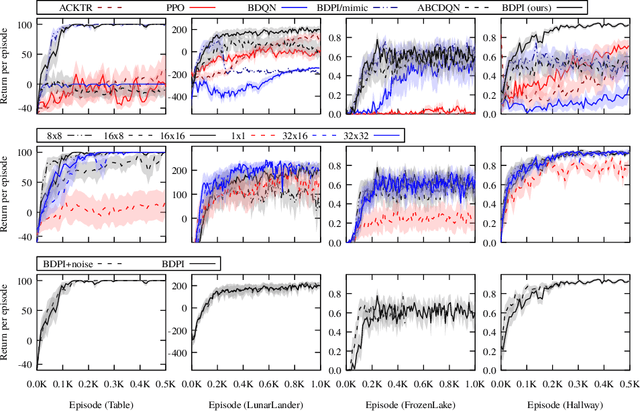
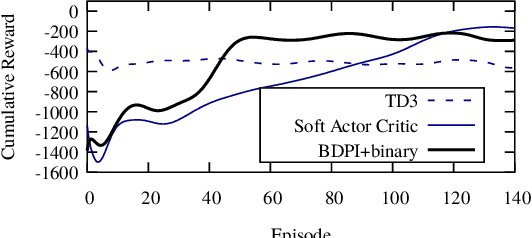
Value-based reinforcement-learning algorithms are currently state-of-the-art in model-free discrete-action settings, and tend to outperform actor-critic algorithms. We argue that actor-critic algorithms are currently limited by their need for an on-policy critic, which severely constraints how the critic is learned. We propose Bootstrapped Dual Policy Iteration (BDPI), a novel model-free actor-critic reinforcement-learning algorithm for continuous states and discrete actions, with off-policy critics. Off-policy critics are compatible with experience replay, ensuring high sample-efficiency, without the need for off-policy corrections. The actor, by slowly imitating the average greedy policy of the critics, leads to high-quality and state-specific exploration, which we show approximates Thompson sampling. Because the actor and critics are fully decoupled, BDPI is remarkably stable and, contrary to other state-of-the-art algorithms, unusually forgiving for poorly-configured hyper-parameters. BDPI is significantly more sample-efficient compared to Bootstrapped DQN, PPO, A3C and ACKTR, on a variety of tasks. Source code: https://github.com/vub-ai-lab/bdpi.
The Actor-Advisor: Policy Gradient With Off-Policy Advice
Feb 07, 2019
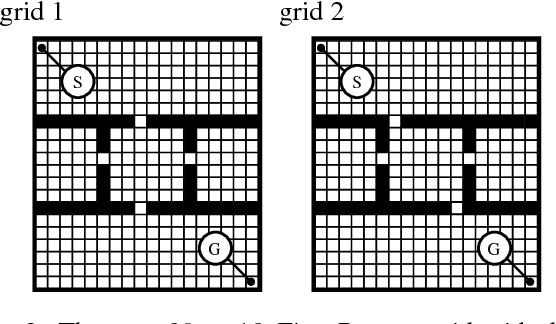
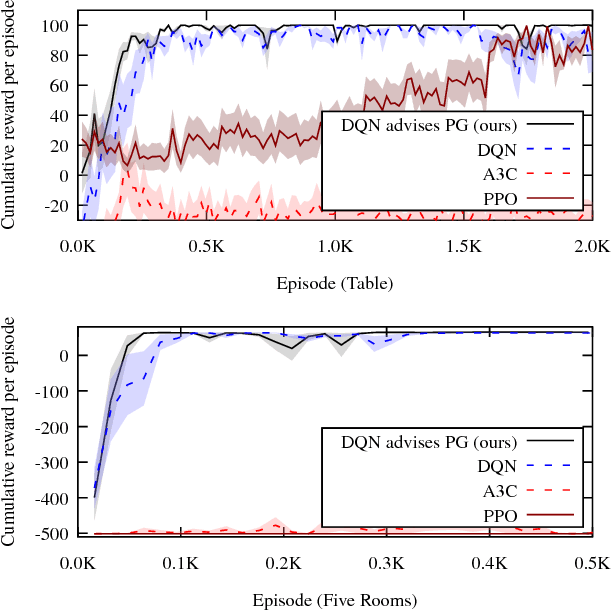
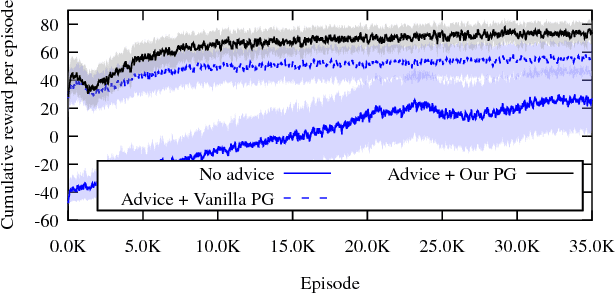
Actor-critic algorithms learn an explicit policy (actor), and an accompanying value function (critic). The actor performs actions in the environment, while the critic evaluates the actor's current policy. However, despite their stability and promising convergence properties, current actor-critic algorithms do not outperform critic-only ones in practice. We believe that the fact that the critic learns Q^pi, instead of the optimal Q-function Q*, prevents state-of-the-art robust and sample-efficient off-policy learning algorithms from being used. In this paper, we propose an elegant solution, the Actor-Advisor architecture, in which a Policy Gradient actor learns from unbiased Monte-Carlo returns, while being shaped (or advised) by the Softmax policy arising from an off-policy critic. The critic can be learned independently from the actor, using any state-of-the-art algorithm. Being advised by a high-quality critic, the actor quickly and robustly learns the task, while its use of the Monte-Carlo return helps overcome any bias the critic may have. In addition to a new Actor-Critic formulation, the Actor-Advisor, a method that allows an external advisory policy to shape a Policy Gradient actor, can be applied to many other domains. By varying the source of advice, we demonstrate the wide applicability of the Actor-Advisor to three other important subfields of RL: safe RL with backup policies, efficient leverage of domain knowledge, and transfer learning in RL. Our experimental results demonstrate the benefits of the Actor-Advisor compared to state-of-the-art actor-critic methods, illustrate its applicability to the three other application scenarios listed above, and show that many important challenges of RL can now be solved using a single elegant solution.
Directed Policy Gradient for Safe Reinforcement Learning with Human Advice
Aug 13, 2018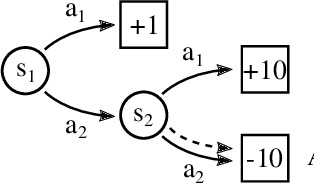


Many currently deployed Reinforcement Learning agents work in an environment shared with humans, be them co-workers, users or clients. It is desirable that these agents adjust to people's preferences, learn faster thanks to their help, and act safely around them. We argue that most current approaches that learn from human feedback are unsafe: rewarding or punishing the agent a-posteriori cannot immediately prevent it from wrong-doing. In this paper, we extend Policy Gradient to make it robust to external directives, that would otherwise break the fundamentally on-policy nature of Policy Gradient. Our technique, Directed Policy Gradient (DPG), allows a teacher or backup policy to override the agent before it acts undesirably, while allowing the agent to leverage human advice or directives to learn faster. Our experiments demonstrate that DPG makes the agent learn much faster than reward-based approaches, while requiring an order of magnitude less advice.
Reinforcement Learning in POMDPs with Memoryless Options and Option-Observation Initiation Sets
Sep 12, 2017
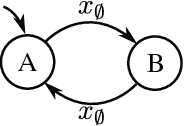
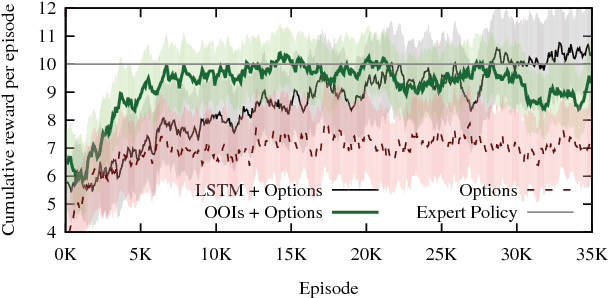
Many real-world reinforcement learning problems have a hierarchical nature, and often exhibit some degree of partial observability. While hierarchy and partial observability are usually tackled separately (for instance by combining recurrent neural networks and options), we show that addressing both problems simultaneously is simpler and more efficient in many cases. More specifically, we make the initiation set of options conditional on the previously-executed option, and show that options with such Option-Observation Initiation Sets (OOIs) are at least as expressive as Finite State Controllers (FSCs), a state-of-the-art approach for learning in POMDPs. OOIs are easy to design based on an intuitive description of the task, lead to explainable policies and keep the top-level and option policies memoryless. Our experiments show that OOIs allow agents to learn optimal policies in challenging POMDPs, while being much more sample-efficient than a recurrent neural network over options.