 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning Across Simulated Robots With Different Sensors
Jul 18, 2019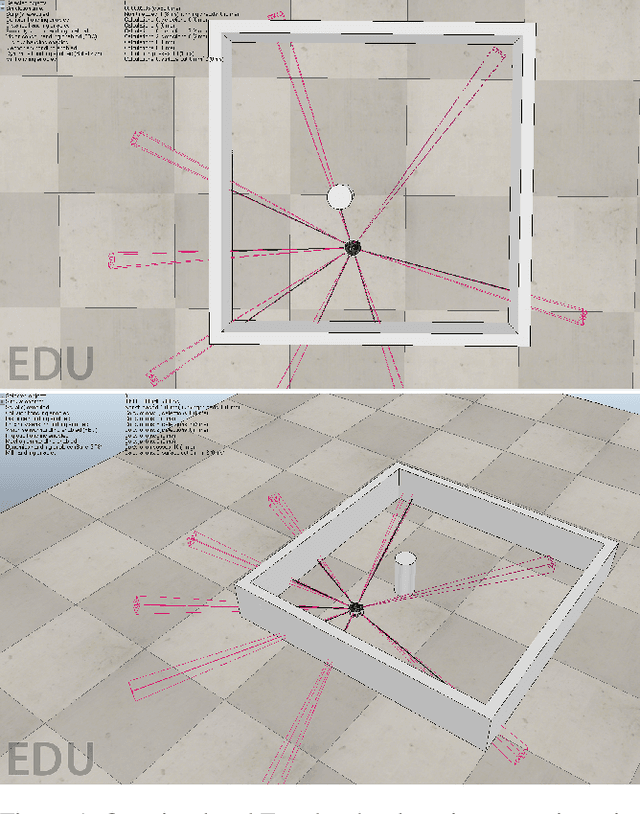
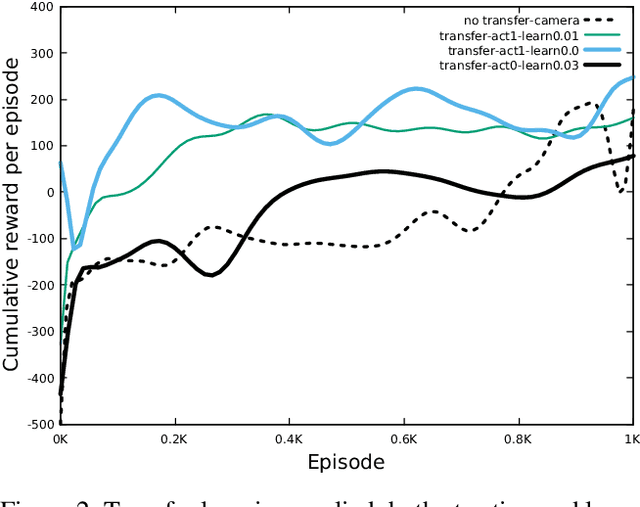
For a robot to learn a good policy, it often requires expensive equipment (such as sophisticated sensors) and a prepared training environment conducive to learning. However, it is seldom possible to perfectly equip robots for economic reasons, nor to guarantee ideal learning conditions, when deployed in real-life environments. A solution would be to prepare the robot in the lab environment, when all necessary material is available to learn a good policy. After training in the lab, the robot should be able to get by without the expensive equipment that used to be available to it, and yet still be guaranteed to perform well on the field. The transition between the lab (source) and the real-world environment (target) is related to transfer learning, where the state-space between the source and target tasks differ. We tackle a simulated task with continuous states and discrete actions presenting this challenge, using Bootstrapped Dual Policy Iteration, a model-free actor-critic reinforcement learning algorithm, and Policy Shaping. Specifically, we train a BDPI agent, embodied by a virtual robot performing a task in the V-Rep simulator, sensing its environment through several proximity sensors. The resulting policy is then used by a second agent learning the same task in the same environment, but with camera images as input. The goal is to obtain a policy able to perform the task relying on merely camera images.