 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCritic-Driven Voronoi-Quantization for Distilling Deep RL Policies to Explainable Models
May 14, 2026Despite many successful attempts at explaining Deep Reinforcement Learning policies using distillation, it remains difficult to balance the performance-interpretability trade-off and select a fitting surrogate model. In addition to this, traditional distillation only minimizes the distance between the behavior of the original and the surrogate policy while other RL-specific components such as action value are disregarded. To solve this, we introduce a new model-agnostic method called Critic-Driven Voronoi State Partitioning, which partitions a black box control policy into regions where a simple class of model can be optimized using gradient descent. By exploiting the critic value network of the original policy, we iteratively introduce new subpolicies in regions with insufficient value, standing in for a measure of policy complexity. The partitioning, a Voronoi quantizer, uses nearest neighbor lookups to assign a linear function to each point in the state space resulting in a cell-like diagram. We validate our approach on several well known benchmarks and proof that this distillation approaches the original policy using a reasonable sized set of linear functions.
Optimistic Reinforcement Learning-Based Skill Insertions for Task and Motion Planning
Oct 15, 2025Task and motion planning (TAMP) for robotics manipulation necessitates long-horizon reasoning involving versatile actions and skills. While deterministic actions can be crafted by sampling or optimizing with certain constraints, planning actions with uncertainty, i.e., probabilistic actions, remains a challenge for TAMP. On the contrary, Reinforcement Learning (RL) excels in acquiring versatile, yet short-horizon, manipulation skills that are robust with uncertainties. In this letter, we design a method that integrates RL skills into TAMP pipelines. Besides the policy, a RL skill is defined with data-driven logical components that enable the skill to be deployed by symbolic planning. A plan refinement sub-routine is designed to further tackle the inevitable effect uncertainties. In the experiments, we compare our method with baseline hierarchical planning from both TAMP and RL fields and illustrate the strength of the method. The results show that by embedding RL skills, we extend the capability of TAMP to domains with probabilistic skills, and improve the planning efficiency compared to the previous methods.
A Task-Efficient Reinforcement Learning Task-Motion Planner for Safe Human-Robot Cooperation
Oct 14, 2025In a Human-Robot Cooperation (HRC) environment, safety and efficiency are the two core properties to evaluate robot performance. However, safety mechanisms usually hinder task efficiency since human intervention will cause backup motions and goal failures of the robot. Frequent motion replanning will increase the computational load and the chance of failure. In this paper, we present a hybrid Reinforcement Learning (RL) planning framework which is comprised of an interactive motion planner and a RL task planner. The RL task planner attempts to choose statistically safe and efficient task sequences based on the feedback from the motion planner, while the motion planner keeps the task execution process collision-free by detecting human arm motions and deploying new paths when the previous path is not valid anymore. Intuitively, the RL agent will learn to avoid dangerous tasks, while the motion planner ensures that the chosen tasks are safe. The proposed framework is validated on the cobot in both simulation and the real world, we compare the planner with hard-coded task motion planning methods. The results show that our planning framework can 1) react to uncertain human motions at both joint and task levels; 2) reduce the times of repeating failed goal commands; 3) reduce the total number of replanning requests.
Human-Readable Programs as Actors of Reinforcement Learning Agents Using Critic-Moderated Evolution
Oct 29, 2024With Deep Reinforcement Learning (DRL) being increasingly considered for the control of real-world systems, the lack of transparency of the neural network at the core of RL becomes a concern. Programmatic Reinforcement Learning (PRL) is able to to create representations of this black-box in the form of source code, not only increasing the explainability of the controller but also allowing for user adaptations. However, these methods focus on distilling a black-box policy into a program and do so after learning using the Mean Squared Error between produced and wanted behaviour, discarding other elements of the RL algorithm. The distilled policy may therefore perform significantly worse than the black-box learned policy. In this paper, we propose to directly learn a program as the policy of an RL agent. We build on TD3 and use its critics as the basis of the objective function of a genetic algorithm that syntheses the program. Our approach builds the program during training, as opposed to after the fact. This steers the program to actual high rewards, instead of a simple Mean Squared Error. Also, our approach leverages the TD3 critics to achieve high sample-efficiency, as opposed to pure genetic methods that rely on Monte-Carlo evaluations. Our experiments demonstrate the validity, explainability and sample-efficiency of our approach in a simple gridworld environment.
Dynamic Size Message Scheduling for Multi-Agent Communication under Limited Bandwidth
Jun 16, 2023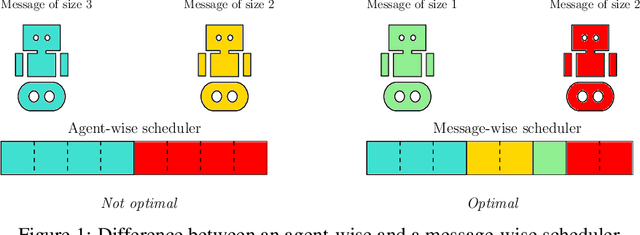
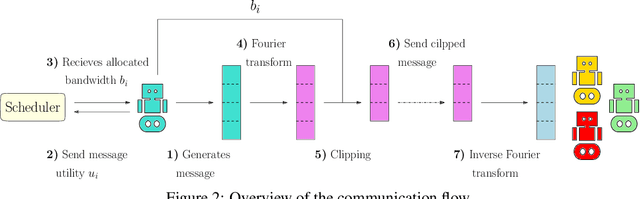
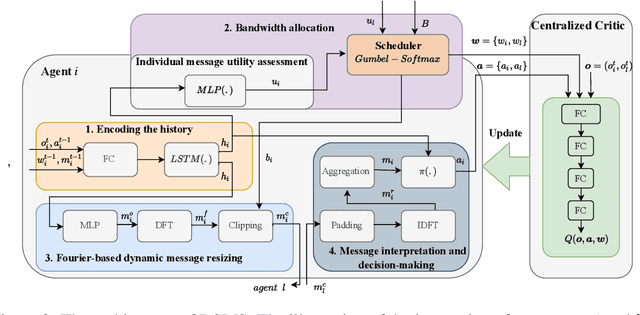
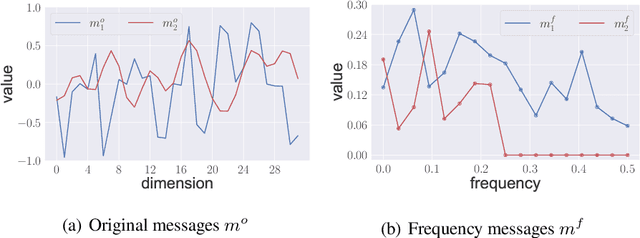
Communication plays a vital role in multi-agent systems, fostering collaboration and coordination. However, in real-world scenarios where communication is bandwidth-limited, existing multi-agent reinforcement learning (MARL) algorithms often provide agents with a binary choice: either transmitting a fixed number of bytes or no information at all. This limitation hinders the ability to effectively utilize the available bandwidth. To overcome this challenge, we present the Dynamic Size Message Scheduling (DSMS) method, which introduces a finer-grained approach to scheduling by considering the actual size of the information to be exchanged. Our contribution lies in adaptively adjusting message sizes using Fourier transform-based compression techniques, enabling agents to tailor their messages to match the allocated bandwidth while striking a balance between information loss and transmission efficiency. Receiving agents can reliably decompress the messages using the inverse Fourier transform. Experimental results demonstrate that DSMS significantly improves performance in multi-agent cooperative tasks by optimizing the utilization of bandwidth and effectively balancing information value.
Transferring Multiple Policies to Hotstart Reinforcement Learning in an Air Compressor Management Problem
Jan 30, 2023Many instances of similar or almost-identical industrial machines or tools are often deployed at once, or in quick succession. For instance, a particular model of air compressor may be installed at hundreds of customers. Because these tools perform distinct but highly similar tasks, it is interesting to be able to quickly produce a high-quality controller for machine $N+1$ given the controllers already produced for machines $1..N$. This is even more important when the controllers are learned through Reinforcement Learning, as training takes time, energy and other resources. In this paper, we apply Policy Intersection, a Policy Shaping method, to help a Reinforcement Learning agent learn to solve a new variant of a compressors control problem faster, by transferring knowledge from several previously learned controllers. We show that our approach outperforms loading an old controller, and significantly improves performance in the long run.
Synthesising Reinforcement Learning Policies through Set-Valued Inductive Rule Learning
Jun 10, 2021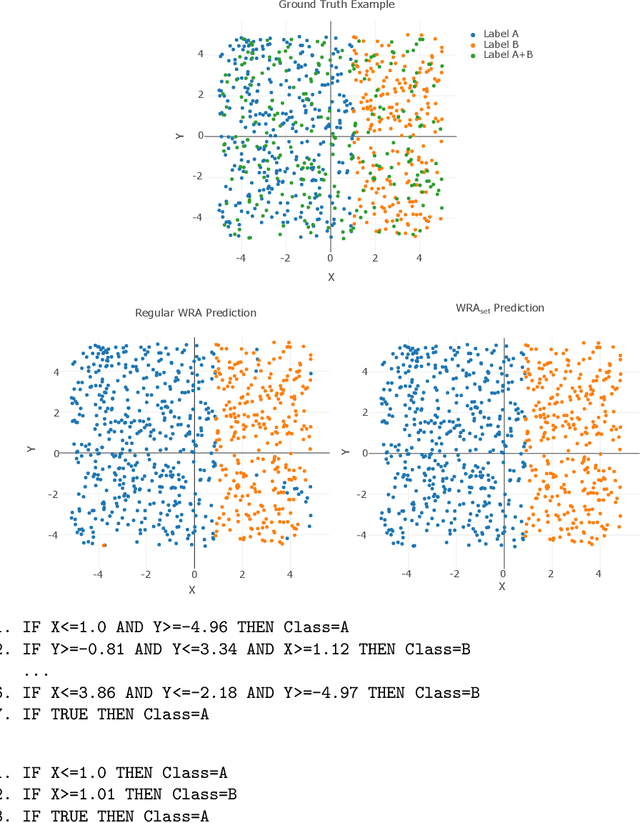
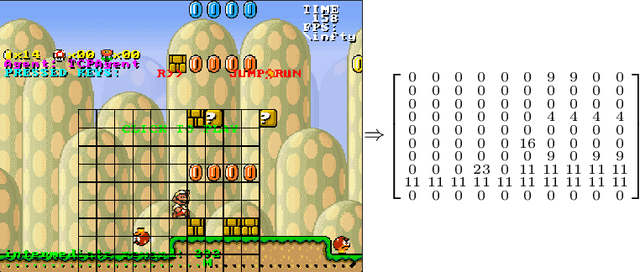

Today's advanced Reinforcement Learning algorithms produce black-box policies, that are often difficult to interpret and trust for a person. We introduce a policy distilling algorithm, building on the CN2 rule mining algorithm, that distills the policy into a rule-based decision system. At the core of our approach is the fact that an RL process does not just learn a policy, a mapping from states to actions, but also produces extra meta-information, such as action values indicating the quality of alternative actions. This meta-information can indicate whether more than one action is near-optimal for a certain state. We extend CN2 to make it able to leverage knowledge about equally-good actions to distill the policy into fewer rules, increasing its interpretability by a person. Then, to ensure that the rules explain a valid, non-degenerate policy, we introduce a refinement algorithm that fine-tunes the rules to obtain good performance when executed in the environment. We demonstrate the applicability of our algorithm on the Mario AI benchmark, a complex task that requires modern reinforcement learning algorithms including neural networks. The explanations we produce capture the learned policy in only a few rules, that allow a person to understand what the black-box agent learned. Source code: https://gitlab.ai.vub.ac.be/yocoppen/svcn2
* 17 pages, 4 figures. The final authenticated publication is available online at https://doi.org/10.1007/978-3-030-73959-1_15
Transfer Learning Across Simulated Robots With Different Sensors
Jul 18, 2019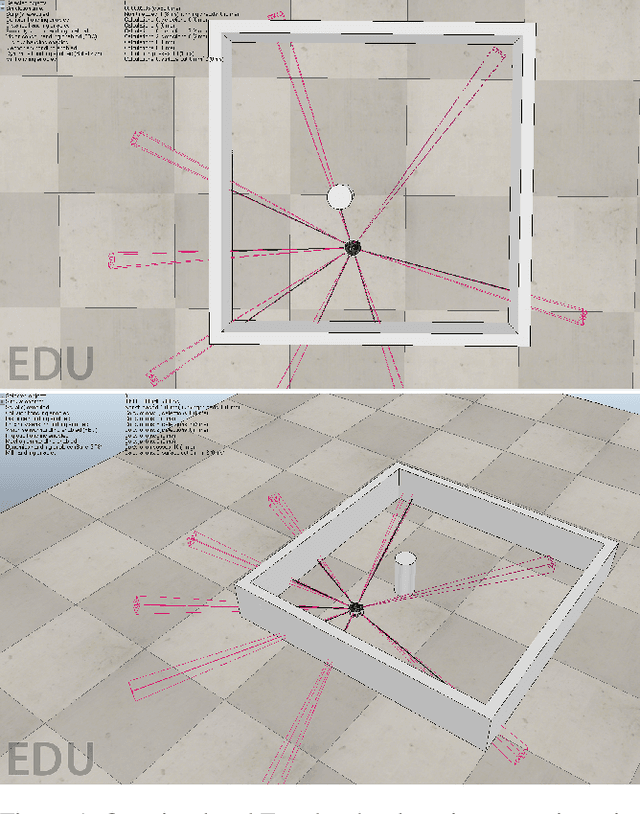
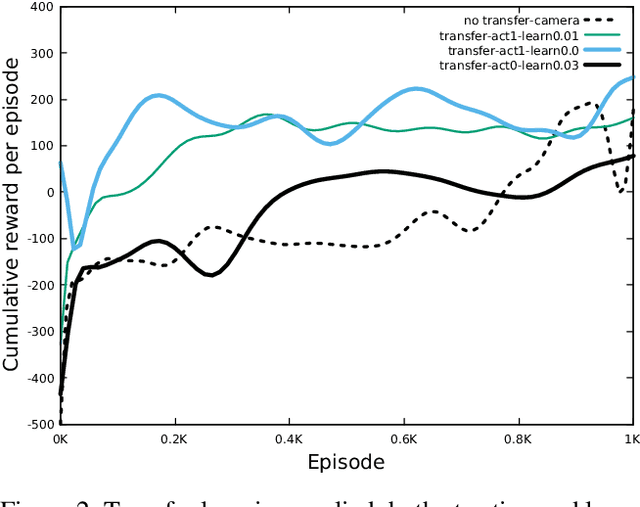
For a robot to learn a good policy, it often requires expensive equipment (such as sophisticated sensors) and a prepared training environment conducive to learning. However, it is seldom possible to perfectly equip robots for economic reasons, nor to guarantee ideal learning conditions, when deployed in real-life environments. A solution would be to prepare the robot in the lab environment, when all necessary material is available to learn a good policy. After training in the lab, the robot should be able to get by without the expensive equipment that used to be available to it, and yet still be guaranteed to perform well on the field. The transition between the lab (source) and the real-world environment (target) is related to transfer learning, where the state-space between the source and target tasks differ. We tackle a simulated task with continuous states and discrete actions presenting this challenge, using Bootstrapped Dual Policy Iteration, a model-free actor-critic reinforcement learning algorithm, and Policy Shaping. Specifically, we train a BDPI agent, embodied by a virtual robot performing a task in the V-Rep simulator, sensing its environment through several proximity sensors. The resulting policy is then used by a second agent learning the same task in the same environment, but with camera images as input. The goal is to obtain a policy able to perform the task relying on merely camera images.
Sample-Efficient Model-Free Reinforcement Learning with Off-Policy Critics
Mar 11, 2019
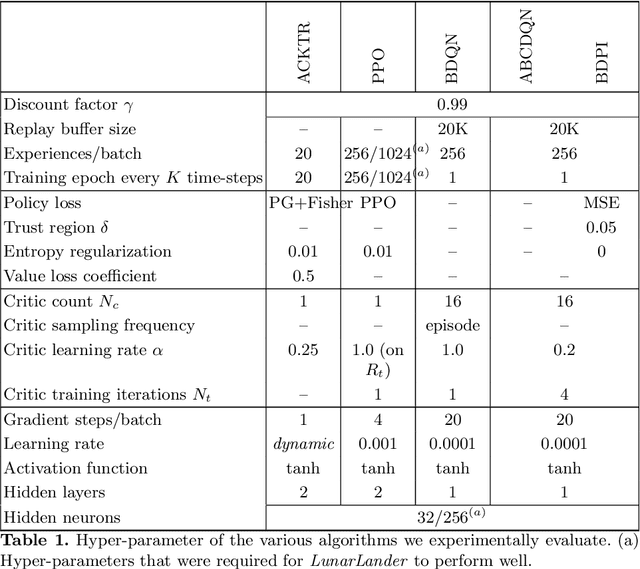
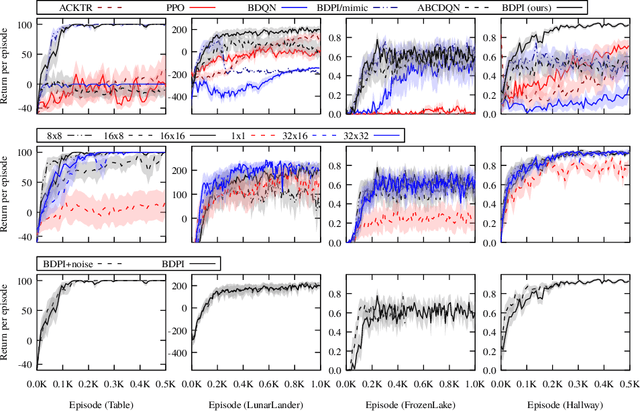
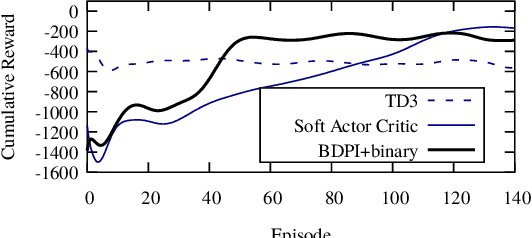
Value-based reinforcement-learning algorithms are currently state-of-the-art in model-free discrete-action settings, and tend to outperform actor-critic algorithms. We argue that actor-critic algorithms are currently limited by their need for an on-policy critic, which severely constraints how the critic is learned. We propose Bootstrapped Dual Policy Iteration (BDPI), a novel model-free actor-critic reinforcement-learning algorithm for continuous states and discrete actions, with off-policy critics. Off-policy critics are compatible with experience replay, ensuring high sample-efficiency, without the need for off-policy corrections. The actor, by slowly imitating the average greedy policy of the critics, leads to high-quality and state-specific exploration, which we show approximates Thompson sampling. Because the actor and critics are fully decoupled, BDPI is remarkably stable and, contrary to other state-of-the-art algorithms, unusually forgiving for poorly-configured hyper-parameters. BDPI is significantly more sample-efficient compared to Bootstrapped DQN, PPO, A3C and ACKTR, on a variety of tasks. Source code: https://github.com/vub-ai-lab/bdpi.
The Actor-Advisor: Policy Gradient With Off-Policy Advice
Feb 07, 2019
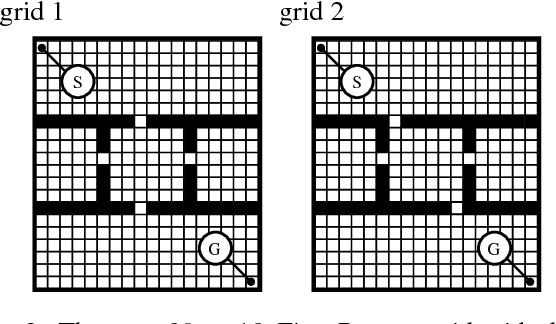
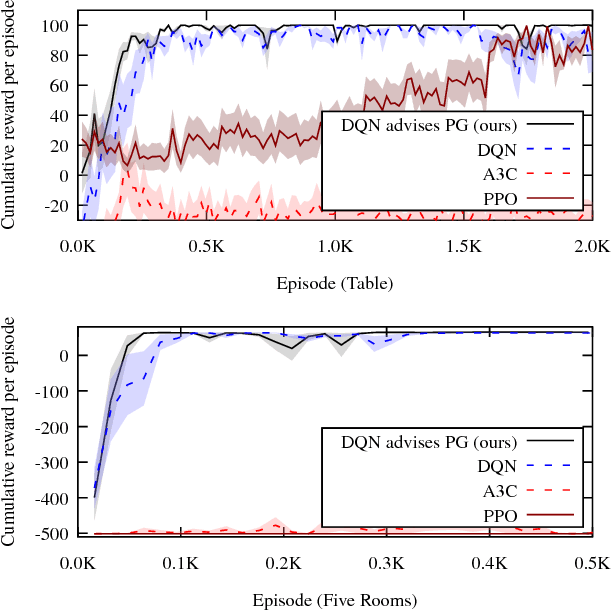
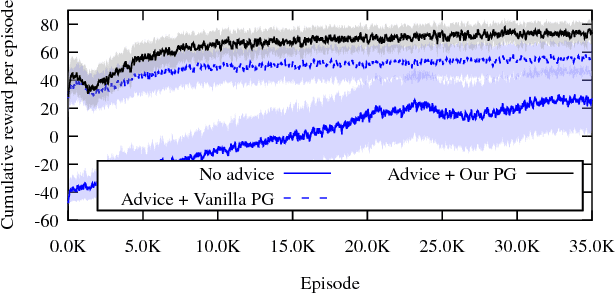
Actor-critic algorithms learn an explicit policy (actor), and an accompanying value function (critic). The actor performs actions in the environment, while the critic evaluates the actor's current policy. However, despite their stability and promising convergence properties, current actor-critic algorithms do not outperform critic-only ones in practice. We believe that the fact that the critic learns Q^pi, instead of the optimal Q-function Q*, prevents state-of-the-art robust and sample-efficient off-policy learning algorithms from being used. In this paper, we propose an elegant solution, the Actor-Advisor architecture, in which a Policy Gradient actor learns from unbiased Monte-Carlo returns, while being shaped (or advised) by the Softmax policy arising from an off-policy critic. The critic can be learned independently from the actor, using any state-of-the-art algorithm. Being advised by a high-quality critic, the actor quickly and robustly learns the task, while its use of the Monte-Carlo return helps overcome any bias the critic may have. In addition to a new Actor-Critic formulation, the Actor-Advisor, a method that allows an external advisory policy to shape a Policy Gradient actor, can be applied to many other domains. By varying the source of advice, we demonstrate the wide applicability of the Actor-Advisor to three other important subfields of RL: safe RL with backup policies, efficient leverage of domain knowledge, and transfer learning in RL. Our experimental results demonstrate the benefits of the Actor-Advisor compared to state-of-the-art actor-critic methods, illustrate its applicability to the three other application scenarios listed above, and show that many important challenges of RL can now be solved using a single elegant solution.