 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesising Reinforcement Learning Policies through Set-Valued Inductive Rule Learning
Paper and Code
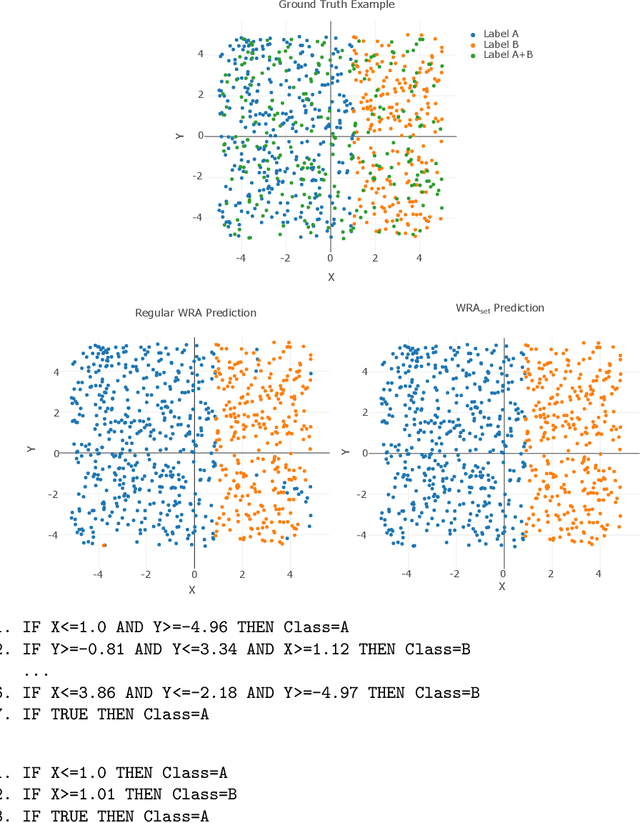
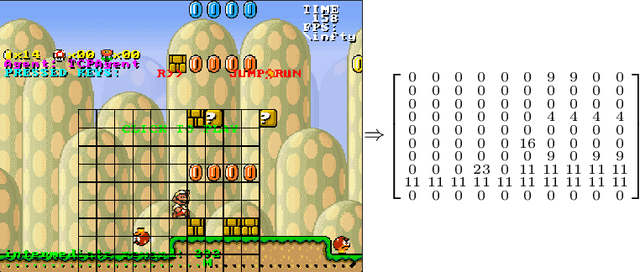

Today's advanced Reinforcement Learning algorithms produce black-box policies, that are often difficult to interpret and trust for a person. We introduce a policy distilling algorithm, building on the CN2 rule mining algorithm, that distills the policy into a rule-based decision system. At the core of our approach is the fact that an RL process does not just learn a policy, a mapping from states to actions, but also produces extra meta-information, such as action values indicating the quality of alternative actions. This meta-information can indicate whether more than one action is near-optimal for a certain state. We extend CN2 to make it able to leverage knowledge about equally-good actions to distill the policy into fewer rules, increasing its interpretability by a person. Then, to ensure that the rules explain a valid, non-degenerate policy, we introduce a refinement algorithm that fine-tunes the rules to obtain good performance when executed in the environment. We demonstrate the applicability of our algorithm on the Mario AI benchmark, a complex task that requires modern reinforcement learning algorithms including neural networks. The explanations we produce capture the learned policy in only a few rules, that allow a person to understand what the black-box agent learned. Source code: https://gitlab.ai.vub.ac.be/yocoppen/svcn2