 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWisdom from Diversity: Bias Mitigation Through Hybrid Human-LLM Crowds
May 18, 2025Despite their performance, large language models (LLMs) can inadvertently perpetuate biases found in the data they are trained on. By analyzing LLM responses to bias-eliciting headlines, we find that these models often mirror human biases. To address this, we explore crowd-based strategies for mitigating bias through response aggregation. We first demonstrate that simply averaging responses from multiple LLMs, intended to leverage the "wisdom of the crowd", can exacerbate existing biases due to the limited diversity within LLM crowds. In contrast, we show that locally weighted aggregation methods more effectively leverage the wisdom of the LLM crowd, achieving both bias mitigation and improved accuracy. Finally, recognizing the complementary strengths of LLMs (accuracy) and humans (diversity), we demonstrate that hybrid crowds containing both significantly enhance performance and further reduce biases across ethnic and gender-related contexts.
Mitigating Biases in Collective Decision-Making: Enhancing Performance in the Face of Fake News
Mar 11, 2024



Individual and social biases undermine the effectiveness of human advisers by inducing judgment errors which can disadvantage protected groups. In this paper, we study the influence these biases can have in the pervasive problem of fake news by evaluating human participants' capacity to identify false headlines. By focusing on headlines involving sensitive characteristics, we gather a comprehensive dataset to explore how human responses are shaped by their biases. Our analysis reveals recurring individual biases and their permeation into collective decisions. We show that demographic factors, headline categories, and the manner in which information is presented significantly influence errors in human judgment. We then use our collected data as a benchmark problem on which we evaluate the efficacy of adaptive aggregation algorithms. In addition to their improved accuracy, our results highlight the interactions between the emergence of collective intelligence and the mitigation of participant biases.
Expertise Trees Resolve Knowledge Limitations in Collective Decision-Making
May 04, 2023



Experts advising decision-makers are likely to display expertise which varies as a function of the problem instance. In practice, this may lead to sub-optimal or discriminatory decisions against minority cases. In this work we model such changes in depth and breadth of knowledge as a partitioning of the problem space into regions of differing expertise. We provide here new algorithms that explicitly consider and adapt to the relationship between problem instances and experts' knowledge. We first propose and highlight the drawbacks of a naive approach based on nearest neighbor queries. To address these drawbacks we then introduce a novel algorithm - expertise trees - that constructs decision trees enabling the learner to select appropriate models. We provide theoretical insights and empirically validate the improved performance of our novel approach on a range of problems for which existing methods proved to be inadequate.
Dealing with Expert Bias in Collective Decision-Making
Jun 25, 2021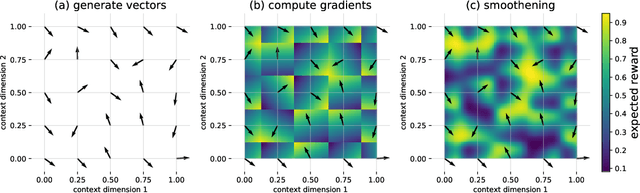
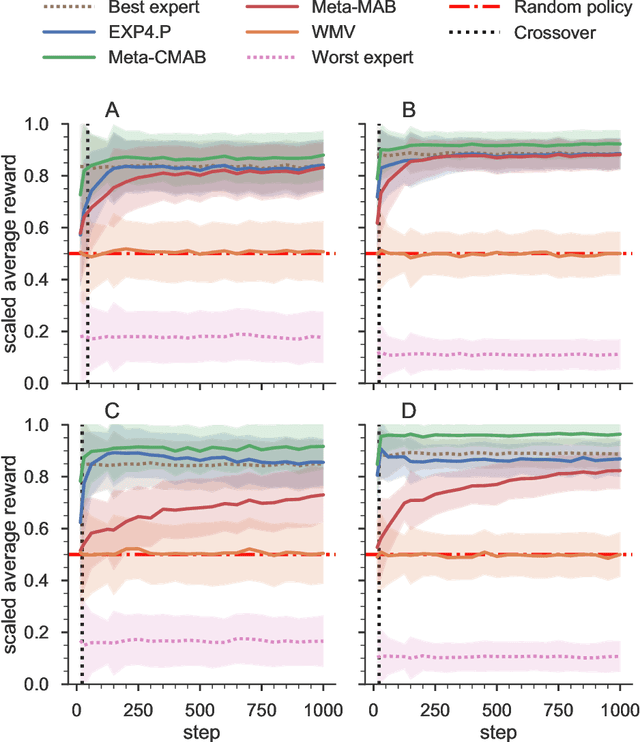
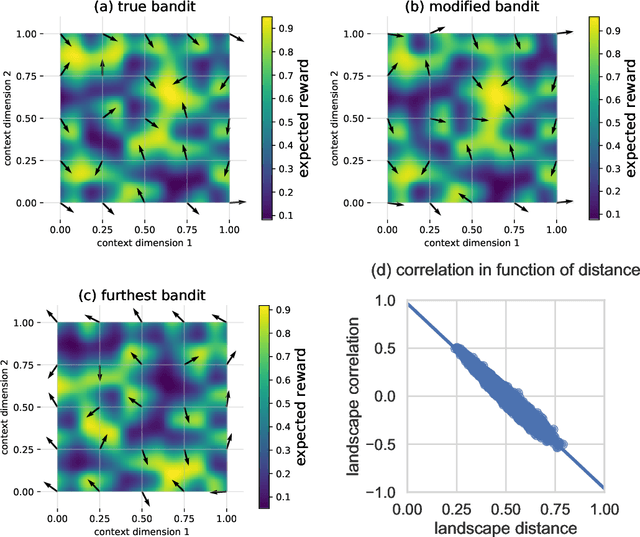
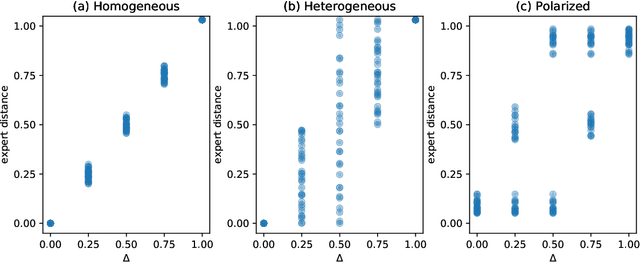
Quite some real-world problems can be formulated as decision-making problems wherein one must repeatedly make an appropriate choice from a set of alternatives. Expert judgements, whether human or artificial, can help in taking correct decisions, especially when exploration of alternative solutions is costly. As expert opinions might deviate, the problem of finding the right alternative can be approached as a collective decision making problem (CDM). Current state-of-the-art approaches to solve CDM are limited by the quality of the best expert in the group, and perform poorly if experts are not qualified or if they are overly biased, thus potentially derailing the decision-making process. In this paper, we propose a new algorithmic approach based on contextual multi-armed bandit problems (CMAB) to identify and counteract such biased expertises. We explore homogeneous, heterogeneous and polarised expert groups and show that this approach is able to effectively exploit the collective expertise, irrespective of whether the provided advice is directly conducive to good performance, outperforming state-of-the-art methods, especially when the quality of the provided expertise degrades. Our novel CMAB-inspired approach achieves a higher final performance and does so while converging more rapidly than previous adaptive algorithms, especially when heterogeneous expertise is readily available.
Dynamic Weights in Multi-Objective Deep Reinforcement Learning
Sep 20, 2018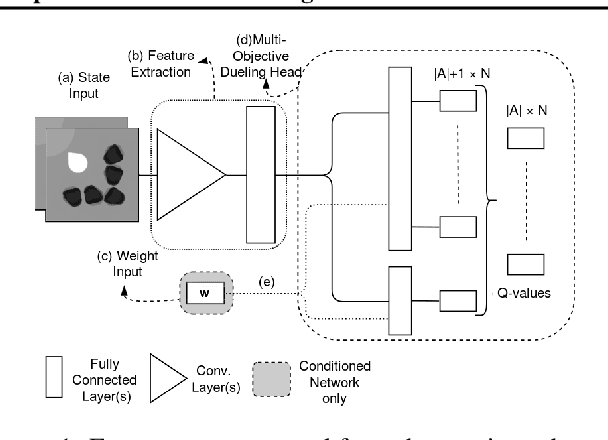
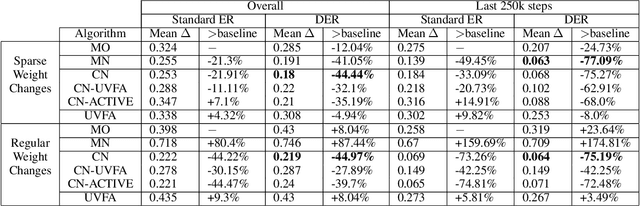
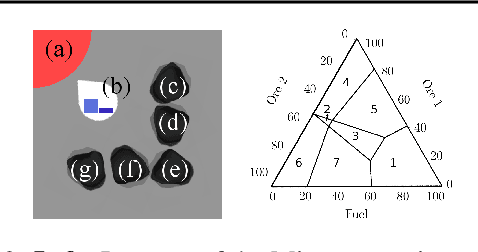

Many real-world decision problems are characterized by multiple objectives which must be balanced based on their relative importance. In the dynamic weights setting this relative importance changes over time, as recognized by Natarajan and Tadepalli (2005) who proposed a tabular Reinforcement Learning algorithm to deal with this problem. However, this earlier work is not feasible for reinforcement learning settings in which the input is high-dimensional, necessitating the use of function approximators, such as neural networks. We propose two novel methods for multi-objective RL with dynamic weights, a multi-network approach and a single-network approach that conditions on the weights. Due to the inherent non-stationarity of the dynamic weights setting, standard experience replay techniques are insufficient. We therefore propose diverse experience replay, a framework to maintain a diverse set of experiences in the replay buffer, and show how it can be applied to make experience replay relevant in multi-objective RL. To evaluate the performance of our algorithms we introduce a new benchmark called the Minecart problem. We show empirically that our algorithms outperform more naive approaches. We also show that, while there are significant differences between many small changes in the weights opposed to sparse larger changes, the conditioned network with diverse experience replay consistently outperforms the other algorithms.