 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Actor-Advisor: Policy Gradient With Off-Policy Advice
Paper and Code
Feb 07, 2019
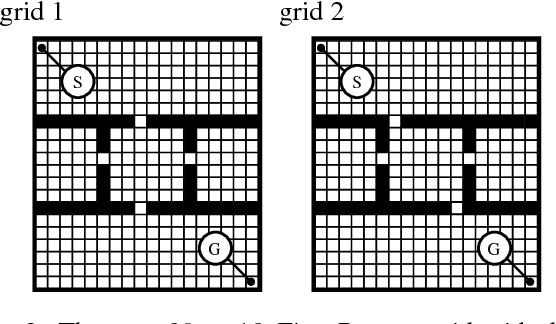
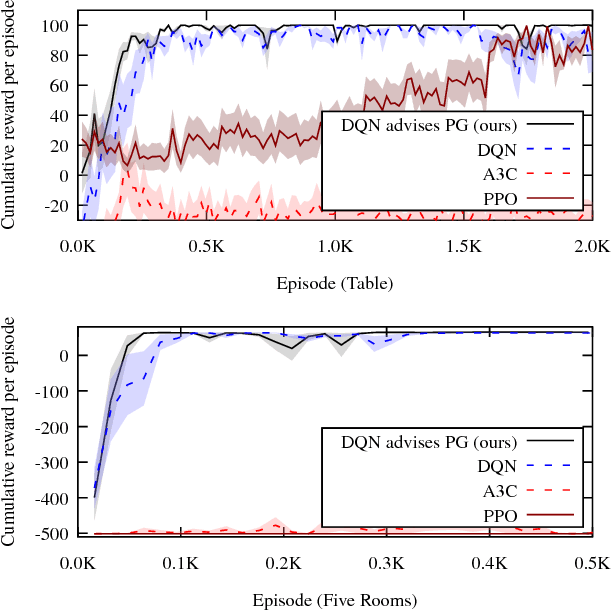
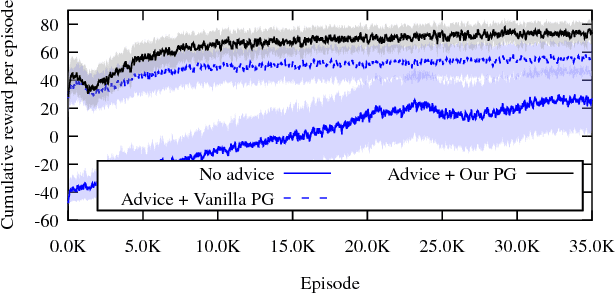
Actor-critic algorithms learn an explicit policy (actor), and an accompanying value function (critic). The actor performs actions in the environment, while the critic evaluates the actor's current policy. However, despite their stability and promising convergence properties, current actor-critic algorithms do not outperform critic-only ones in practice. We believe that the fact that the critic learns Q^pi, instead of the optimal Q-function Q*, prevents state-of-the-art robust and sample-efficient off-policy learning algorithms from being used. In this paper, we propose an elegant solution, the Actor-Advisor architecture, in which a Policy Gradient actor learns from unbiased Monte-Carlo returns, while being shaped (or advised) by the Softmax policy arising from an off-policy critic. The critic can be learned independently from the actor, using any state-of-the-art algorithm. Being advised by a high-quality critic, the actor quickly and robustly learns the task, while its use of the Monte-Carlo return helps overcome any bias the critic may have. In addition to a new Actor-Critic formulation, the Actor-Advisor, a method that allows an external advisory policy to shape a Policy Gradient actor, can be applied to many other domains. By varying the source of advice, we demonstrate the wide applicability of the Actor-Advisor to three other important subfields of RL: safe RL with backup policies, efficient leverage of domain knowledge, and transfer learning in RL. Our experimental results demonstrate the benefits of the Actor-Advisor compared to state-of-the-art actor-critic methods, illustrate its applicability to the three other application scenarios listed above, and show that many important challenges of RL can now be solved using a single elegant solution.