 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the Value Systems of Societies with Preference-based Multi-objective Reinforcement Learning
Feb 09, 2026Value-aware AI should recognise human values and adapt to the value systems (value-based preferences) of different users. This requires operationalization of values, which can be prone to misspecification. The social nature of values demands their representation to adhere to multiple users while value systems are diverse, yet exhibit patterns among groups. In sequential decision making, efforts have been made towards personalization for different goals or values from demonstrations of diverse agents. However, these approaches demand manually designed features or lack value-based interpretability and/or adaptability to diverse user preferences. We propose algorithms for learning models of value alignment and value systems for a society of agents in Markov Decision Processes (MDPs), based on clustering and preference-based multi-objective reinforcement learning (PbMORL). We jointly learn socially-derived value alignment models (groundings) and a set of value systems that concisely represent different groups of users (clusters) in a society. Each cluster consists of a value system representing the value-based preferences of its members and an approximately Pareto-optimal policy that reflects behaviours aligned with this value system. We evaluate our method against a state-of-the-art PbMORL algorithm and baselines on two MDPs with human values.
Ensemble Elastic DQN: A novel multi-step ensemble approach to address overestimation in deep value-based reinforcement learning
Jun 06, 2025While many algorithmic extensions to Deep Q-Networks (DQN) have been proposed, there remains limited understanding of how different improvements interact. In particular, multi-step and ensemble style extensions have shown promise in reducing overestimation bias, thereby improving sample efficiency and algorithmic stability. In this paper, we introduce a novel algorithm called Ensemble Elastic Step DQN (EEDQN), which unifies ensembles with elastic step updates to stabilise algorithmic performance. EEDQN is designed to address two major challenges in deep reinforcement learning: overestimation bias and sample efficiency. We evaluated EEDQN against standard and ensemble DQN variants across the MinAtar benchmark, a set of environments that emphasise behavioral learning while reducing representational complexity. Our results show that EEDQN achieves consistently robust performance across all tested environments, outperforming baseline DQN methods and matching or exceeding state-of-the-art ensemble DQNs in final returns on most of the MinAtar environments. These findings highlight the potential of systematically combining algorithmic improvements and provide evidence that ensemble and multi-step methods, when carefully integrated, can yield substantial gains.
Adaptive Alignment: Dynamic Preference Adjustments via Multi-Objective Reinforcement Learning for Pluralistic AI
Oct 31, 2024
Emerging research in Pluralistic Artificial Intelligence (AI) alignment seeks to address how intelligent systems can be designed and deployed in accordance with diverse human needs and values. We contribute to this pursuit with a dynamic approach for aligning AI with diverse and shifting user preferences through Multi Objective Reinforcement Learning (MORL), via post-learning policy selection adjustment. In this paper, we introduce the proposed framework for this approach, outline its anticipated advantages and assumptions, and discuss technical details about the implementation. We also examine the broader implications of adopting a retroactive alignment approach through the sociotechnical systems perspective.
Multi-objective Reinforcement Learning: A Tool for Pluralistic Alignment
Oct 15, 2024Reinforcement learning (RL) is a valuable tool for the creation of AI systems. However it may be problematic to adequately align RL based on scalar rewards if there are multiple conflicting values or stakeholders to be considered. Over the last decade multi-objective reinforcement learning (MORL) using vector rewards has emerged as an alternative to standard, scalar RL. This paper provides an overview of the role which MORL can play in creating pluralistically-aligned AI.
Value function interference and greedy action selection in value-based multi-objective reinforcement learning
Feb 09, 2024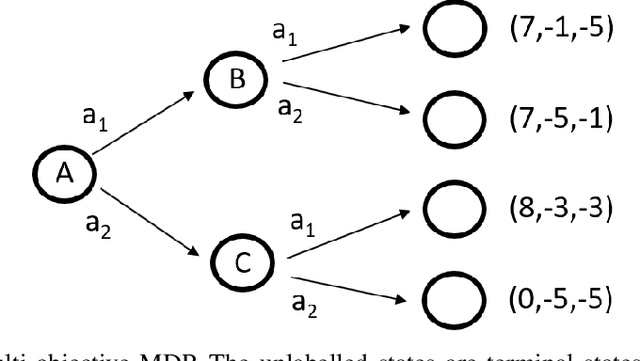

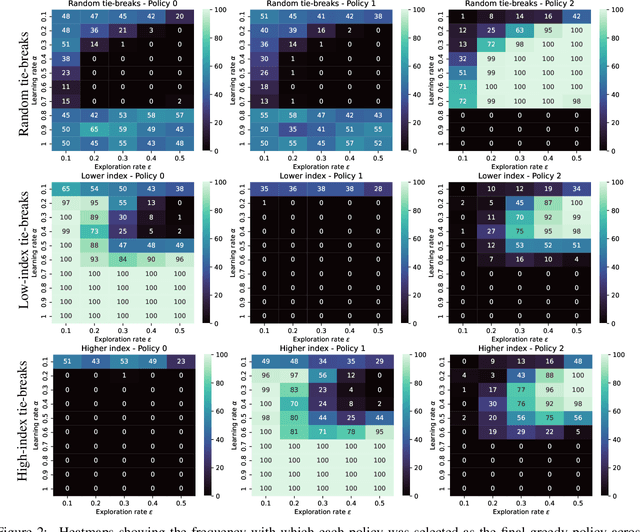

Multi-objective reinforcement learning (MORL) algorithms extend conventional reinforcement learning (RL) to the more general case of problems with multiple, conflicting objectives, represented by vector-valued rewards. Widely-used scalar RL methods such as Q-learning can be modified to handle multiple objectives by (1) learning vector-valued value functions, and (2) performing action selection using a scalarisation or ordering operator which reflects the user's utility with respect to the different objectives. However, as we demonstrate here, if the user's utility function maps widely varying vector-values to similar levels of utility, this can lead to interference in the value-function learned by the agent, leading to convergence to sub-optimal policies. This will be most prevalent in stochastic environments when optimising for the Expected Scalarised Return criterion, but we present a simple example showing that interference can also arise in deterministic environments. We demonstrate empirically that avoiding the use of random tie-breaking when identifying greedy actions can ameliorate, but not fully overcome, the problems caused by value function interference.
Utility-Based Reinforcement Learning: Unifying Single-objective and Multi-objective Reinforcement Learning
Feb 05, 2024Research in multi-objective reinforcement learning (MORL) has introduced the utility-based paradigm, which makes use of both environmental rewards and a function that defines the utility derived by the user from those rewards. In this paper we extend this paradigm to the context of single-objective reinforcement learning (RL), and outline multiple potential benefits including the ability to perform multi-policy learning across tasks relating to uncertain objectives, risk-aware RL, discounting, and safe RL. We also examine the algorithmic implications of adopting a utility-based approach.
An Empirical Investigation of Value-Based Multi-objective Reinforcement Learning for Stochastic Environments
Jan 06, 2024One common approach to solve multi-objective reinforcement learning (MORL) problems is to extend conventional Q-learning by using vector Q-values in combination with a utility function. However issues can arise with this approach in the context of stochastic environments, particularly when optimising for the Scalarised Expected Reward (SER) criterion. This paper extends prior research, providing a detailed examination of the factors influencing the frequency with which value-based MORL Q-learning algorithms learn the SER-optimal policy for an environment with stochastic state transitions. We empirically examine several variations of the core multi-objective Q-learning algorithm as well as reward engineering approaches, and demonstrate the limitations of these methods. In particular, we highlight the critical impact of the noisy Q-value estimates issue on the stability and convergence of these algorithms.
Intent-aligned AI systems deplete human agency: the need for agency foundations research in AI safety
May 30, 2023The rapid advancement of artificial intelligence (AI) systems suggests that artificial general intelligence (AGI) systems may soon arrive. Many researchers are concerned that AIs and AGIs will harm humans via intentional misuse (AI-misuse) or through accidents (AI-accidents). In respect of AI-accidents, there is an increasing effort focused on developing algorithms and paradigms that ensure AI systems are aligned to what humans intend, e.g. AI systems that yield actions or recommendations that humans might judge as consistent with their intentions and goals. Here we argue that alignment to human intent is insufficient for safe AI systems and that preservation of long-term agency of humans may be a more robust standard, and one that needs to be separated explicitly and a priori during optimization. We argue that AI systems can reshape human intention and discuss the lack of biological and psychological mechanisms that protect humans from loss of agency. We provide the first formal definition of agency-preserving AI-human interactions which focuses on forward-looking agency evaluations and argue that AI systems - not humans - must be increasingly tasked with making these evaluations. We show how agency loss can occur in simple environments containing embedded agents that use temporal-difference learning to make action recommendations. Finally, we propose a new area of research called "agency foundations" and pose four initial topics designed to improve our understanding of agency in AI-human interactions: benevolent game theory, algorithmic foundations of human rights, mechanistic interpretability of agency representation in neural-networks and reinforcement learning from internal states.
Broad-persistent Advice for Interactive Reinforcement Learning Scenarios
Oct 11, 2022
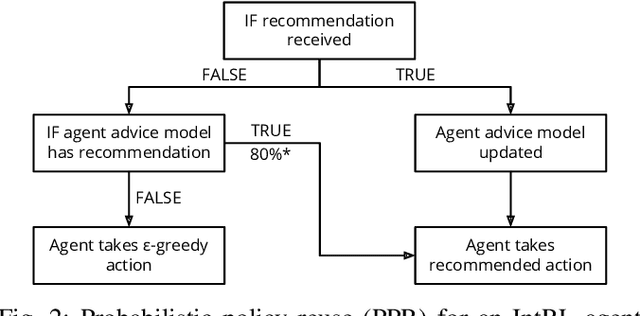


The use of interactive advice in reinforcement learning scenarios allows for speeding up the learning process for autonomous agents. Current interactive reinforcement learning research has been limited to real-time interactions that offer relevant user advice to the current state only. Moreover, the information provided by each interaction is not retained and instead discarded by the agent after a single use. In this paper, we present a method for retaining and reusing provided knowledge, allowing trainers to give general advice relevant to more than just the current state. Results obtained show that the use of broad-persistent advice substantially improves the performance of the agent while reducing the number of interactions required for the trainer.
Elastic Step DQN: A novel multi-step algorithm to alleviate overestimation in Deep QNetworks
Oct 07, 2022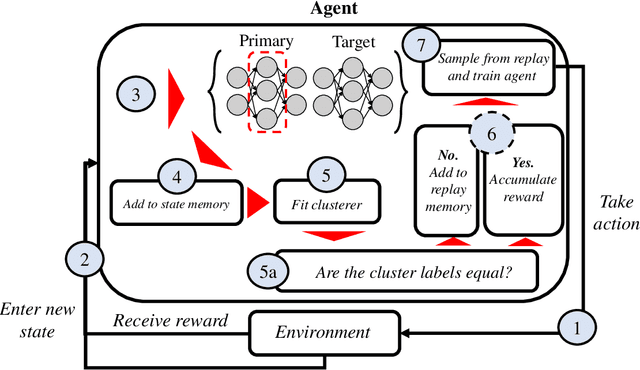
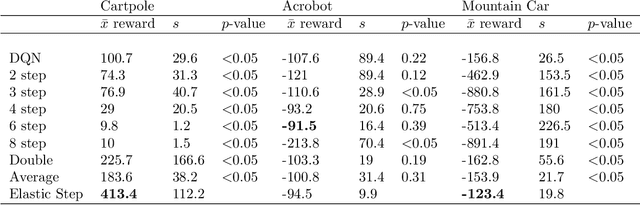
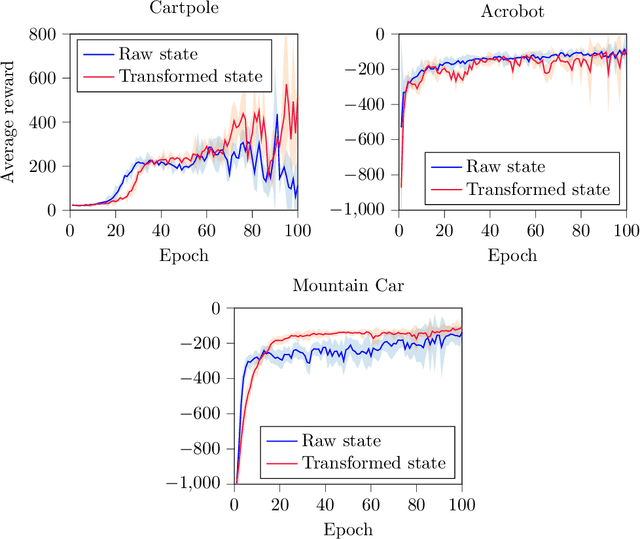
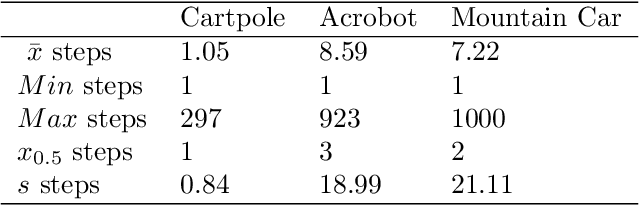
Deep Q-Networks algorithm (DQN) was the first reinforcement learning algorithm using deep neural network to successfully surpass human level performance in a number of Atari learning environments. However, divergent and unstable behaviour have been long standing issues in DQNs. The unstable behaviour is often characterised by overestimation in the $Q$-values, commonly referred to as the overestimation bias. To address the overestimation bias and the divergent behaviour, a number of heuristic extensions have been proposed. Notably, multi-step updates have been shown to drastically reduce unstable behaviour while improving agent's training performance. However, agents are often highly sensitive to the selection of the multi-step update horizon ($n$), and our empirical experiments show that a poorly chosen static value for $n$ can in many cases lead to worse performance than single-step DQN. Inspired by the success of $n$-step DQN and the effects that multi-step updates have on overestimation bias, this paper proposes a new algorithm that we call `Elastic Step DQN' (ES-DQN). It dynamically varies the step size horizon in multi-step updates based on the similarity of states visited. Our empirical evaluation shows that ES-DQN out-performs $n$-step with fixed $n$ updates, Double DQN and Average DQN in several OpenAI Gym environments while at the same time alleviating the overestimation bias.