 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue function interference and greedy action selection in value-based multi-objective reinforcement learning
Paper and Code
Feb 09, 2024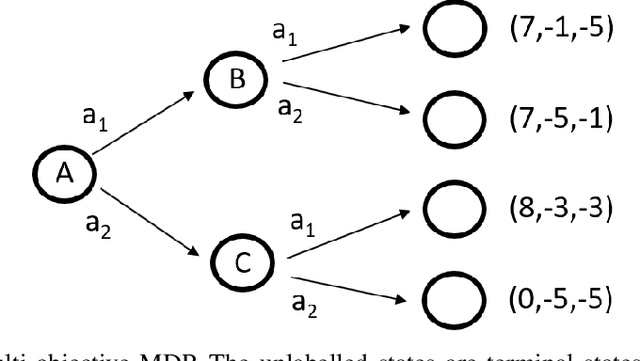

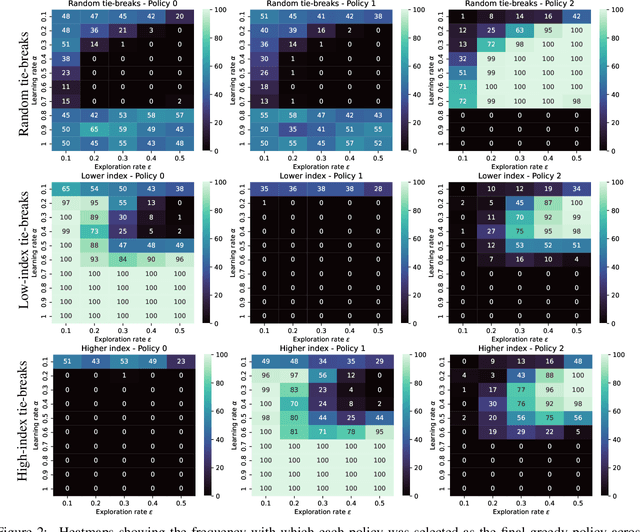

Multi-objective reinforcement learning (MORL) algorithms extend conventional reinforcement learning (RL) to the more general case of problems with multiple, conflicting objectives, represented by vector-valued rewards. Widely-used scalar RL methods such as Q-learning can be modified to handle multiple objectives by (1) learning vector-valued value functions, and (2) performing action selection using a scalarisation or ordering operator which reflects the user's utility with respect to the different objectives. However, as we demonstrate here, if the user's utility function maps widely varying vector-values to similar levels of utility, this can lead to interference in the value-function learned by the agent, leading to convergence to sub-optimal policies. This will be most prevalent in stochastic environments when optimising for the Expected Scalarised Return criterion, but we present a simple example showing that interference can also arise in deterministic environments. We demonstrate empirically that avoiding the use of random tie-breaking when identifying greedy actions can ameliorate, but not fully overcome, the problems caused by value function interference.