 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-objective Reinforcement Learning: A Tool for Pluralistic Alignment
Oct 15, 2024Reinforcement learning (RL) is a valuable tool for the creation of AI systems. However it may be problematic to adequately align RL based on scalar rewards if there are multiple conflicting values or stakeholders to be considered. Over the last decade multi-objective reinforcement learning (MORL) using vector rewards has emerged as an alternative to standard, scalar RL. This paper provides an overview of the role which MORL can play in creating pluralistically-aligned AI.
Value function interference and greedy action selection in value-based multi-objective reinforcement learning
Feb 09, 2024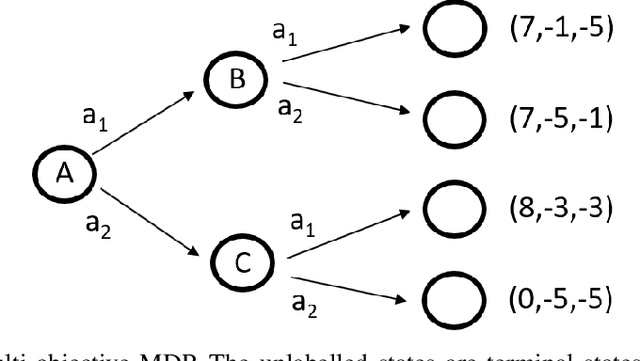

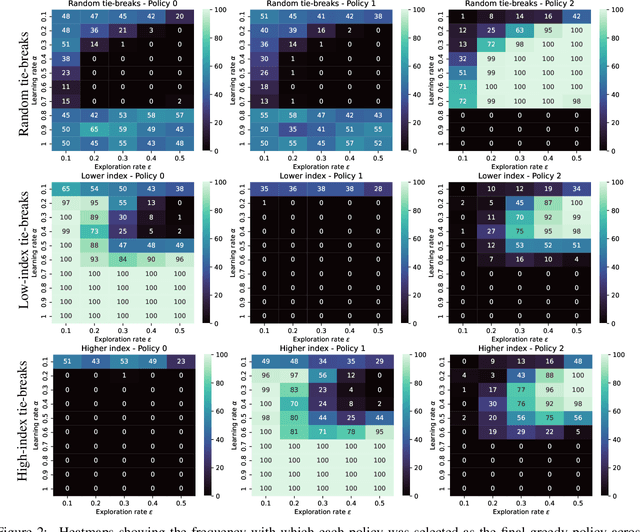

Multi-objective reinforcement learning (MORL) algorithms extend conventional reinforcement learning (RL) to the more general case of problems with multiple, conflicting objectives, represented by vector-valued rewards. Widely-used scalar RL methods such as Q-learning can be modified to handle multiple objectives by (1) learning vector-valued value functions, and (2) performing action selection using a scalarisation or ordering operator which reflects the user's utility with respect to the different objectives. However, as we demonstrate here, if the user's utility function maps widely varying vector-values to similar levels of utility, this can lead to interference in the value-function learned by the agent, leading to convergence to sub-optimal policies. This will be most prevalent in stochastic environments when optimising for the Expected Scalarised Return criterion, but we present a simple example showing that interference can also arise in deterministic environments. We demonstrate empirically that avoiding the use of random tie-breaking when identifying greedy actions can ameliorate, but not fully overcome, the problems caused by value function interference.
Utility-Based Reinforcement Learning: Unifying Single-objective and Multi-objective Reinforcement Learning
Feb 05, 2024Research in multi-objective reinforcement learning (MORL) has introduced the utility-based paradigm, which makes use of both environmental rewards and a function that defines the utility derived by the user from those rewards. In this paper we extend this paradigm to the context of single-objective reinforcement learning (RL), and outline multiple potential benefits including the ability to perform multi-policy learning across tasks relating to uncertain objectives, risk-aware RL, discounting, and safe RL. We also examine the algorithmic implications of adopting a utility-based approach.
An Empirical Investigation of Value-Based Multi-objective Reinforcement Learning for Stochastic Environments
Jan 06, 2024One common approach to solve multi-objective reinforcement learning (MORL) problems is to extend conventional Q-learning by using vector Q-values in combination with a utility function. However issues can arise with this approach in the context of stochastic environments, particularly when optimising for the Scalarised Expected Reward (SER) criterion. This paper extends prior research, providing a detailed examination of the factors influencing the frequency with which value-based MORL Q-learning algorithms learn the SER-optimal policy for an environment with stochastic state transitions. We empirically examine several variations of the core multi-objective Q-learning algorithm as well as reward engineering approaches, and demonstrate the limitations of these methods. In particular, we highlight the critical impact of the noisy Q-value estimates issue on the stability and convergence of these algorithms.
Levels of explainable artificial intelligence for human-aligned conversational explanations
Jul 07, 2021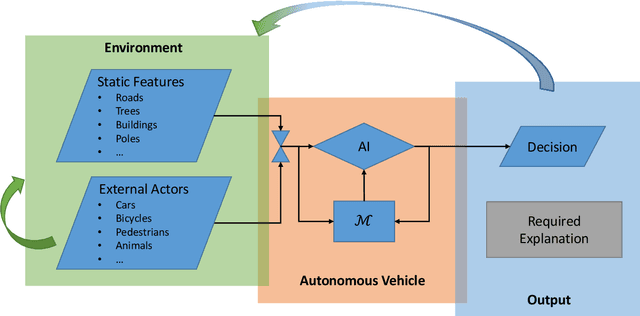
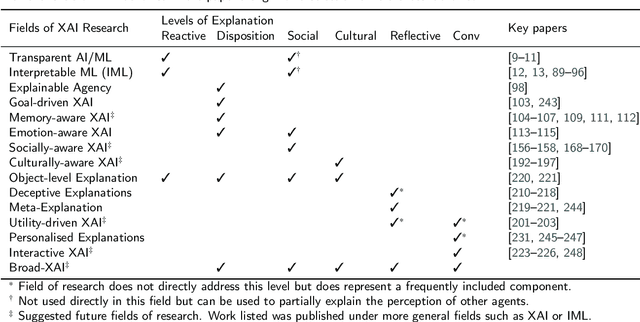
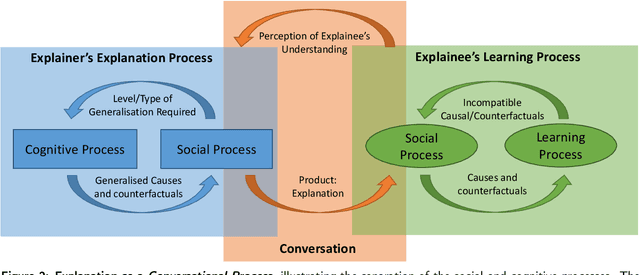
Over the last few years there has been rapid research growth into eXplainable Artificial Intelligence (XAI) and the closely aligned Interpretable Machine Learning (IML). Drivers for this growth include recent legislative changes and increased investments by industry and governments, along with increased concern from the general public. People are affected by autonomous decisions every day and the public need to understand the decision-making process to accept the outcomes. However, the vast majority of the applications of XAI/IML are focused on providing low-level `narrow' explanations of how an individual decision was reached based on a particular datum. While important, these explanations rarely provide insights into an agent's: beliefs and motivations; hypotheses of other (human, animal or AI) agents' intentions; interpretation of external cultural expectations; or, processes used to generate its own explanation. Yet all of these factors, we propose, are essential to providing the explanatory depth that people require to accept and trust the AI's decision-making. This paper aims to define levels of explanation and describe how they can be integrated to create a human-aligned conversational explanation system. In so doing, this paper will survey current approaches and discuss the integration of different technologies to achieve these levels with Broad eXplainable Artificial Intelligence (Broad-XAI), and thereby move towards high-level `strong' explanations.
* 35 pages, 13 figures
Persistent Rule-based Interactive Reinforcement Learning
Feb 04, 2021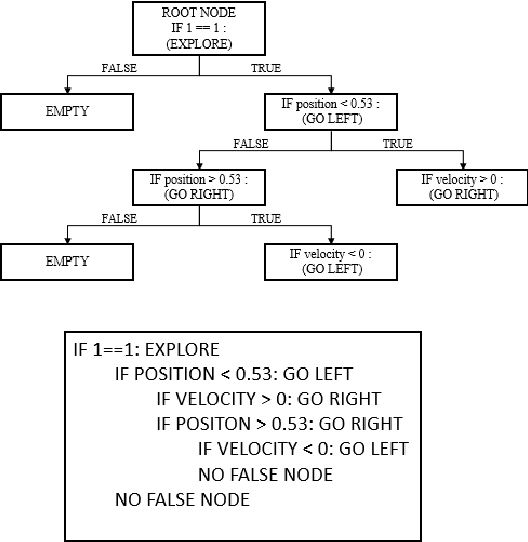
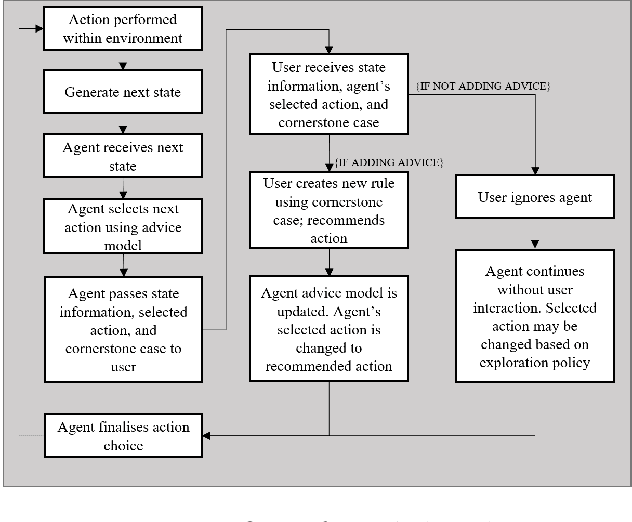
Interactive reinforcement learning has allowed speeding up the learning process in autonomous agents by including a human trainer providing extra information to the agent in real-time. Current interactive reinforcement learning research has been limited to interactions that offer relevant advice to the current state only. Additionally, the information provided by each interaction is not retained and instead discarded by the agent after a single-use. In this work, we propose a persistent rule-based interactive reinforcement learning approach, i.e., a method for retaining and reusing provided knowledge, allowing trainers to give general advice relevant to more than just the current state. Our experimental results show persistent advice substantially improves the performance of the agent while reducing the number of interactions required for the trainer. Moreover, rule-based advice shows similar performance impact as state-based advice, but with a substantially reduced interaction count.
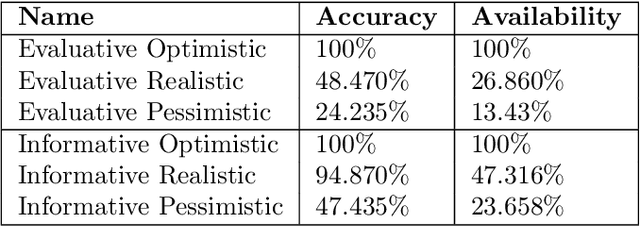
Human Engagement Providing Evaluative and Informative Advice for Interactive Reinforcement Learning
Sep 21, 2020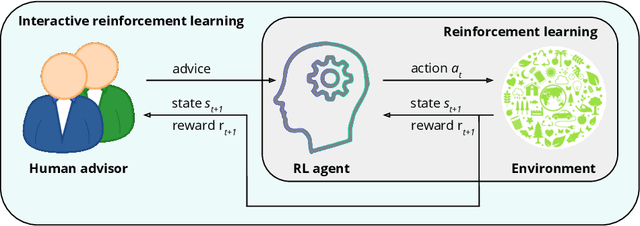

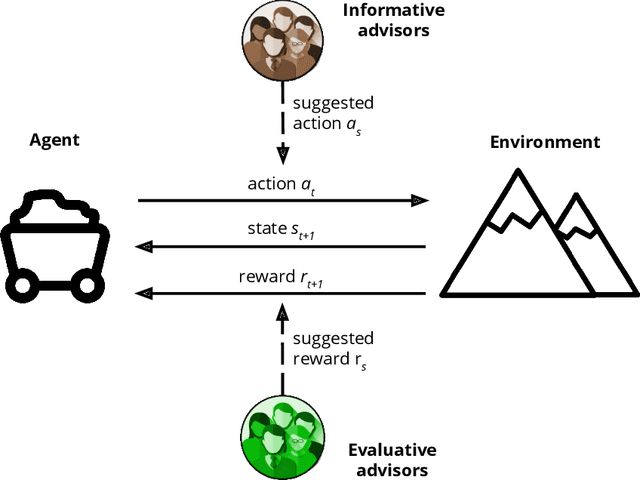
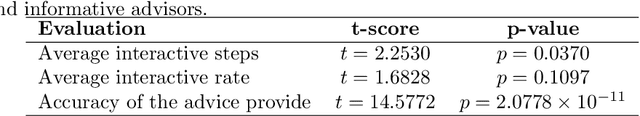
Reinforcement learning is an approach used by intelligent agents to autonomously learn new skills. Although reinforcement learning has been demonstrated to be an effective learning approach in several different contexts, a common drawback exhibited is the time needed in order to satisfactorily learn a task, especially in large state-action spaces. To address this issue, interactive reinforcement learning proposes the use of externally-sourced information in order to speed up the learning process. Up to now, different information sources have been used to give advice to the learner agent, among them human-sourced advice. When interacting with a learner agent, humans may provide either evaluative or informative advice. From the agent's perspective these styles of interaction are commonly referred to as reward-shaping and policy-shaping respectively. Evaluation requires the human to provide feedback on the prior action performed, while informative advice they provide advice on the best action to select for a given situation. Prior research has focused on the effect of human-sourced advice on the interactive reinforcement learning process, specifically aiming to improve the learning speed of the agent, while reducing the engagement with the human. This work presents an experimental setup for a human-trial designed to compare the methods people use to deliver advice in term of human engagement. Obtained results show that users giving informative advice to the learner agents provide more accurate advice, are willing to assist the learner agent for a longer time, and provide more advice per episode. Additionally, self-evaluation from participants using the informative approach has indicated that the agent's ability to follow the advice is higher, and therefore, they feel their own advice to be of higher accuracy when compared to people providing evaluative advice.
A Conceptual Framework for Externally-influenced Agents: An Assisted Reinforcement Learning Review
Jul 03, 2020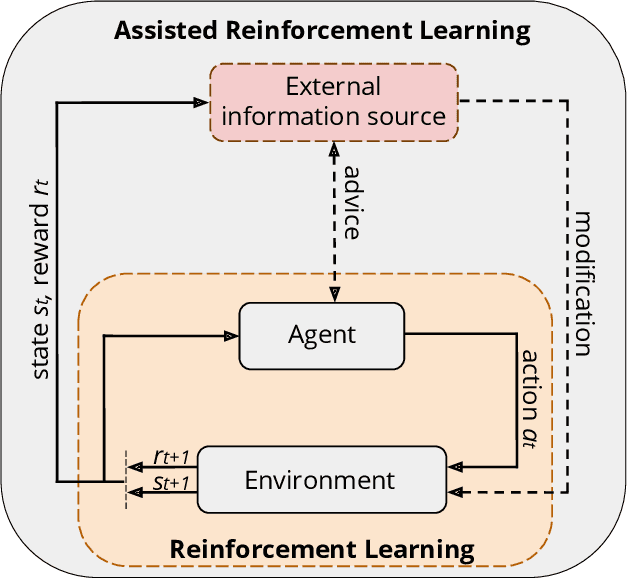
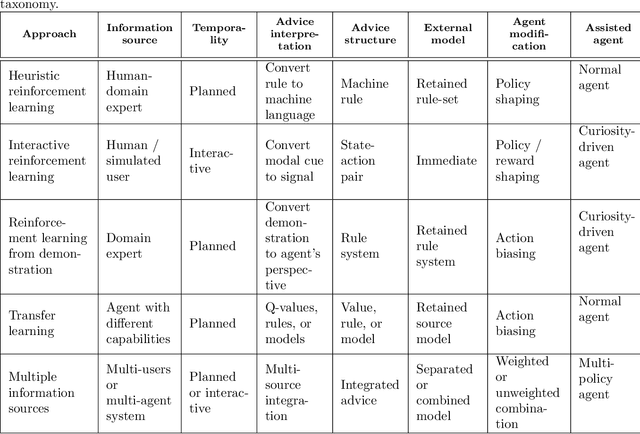
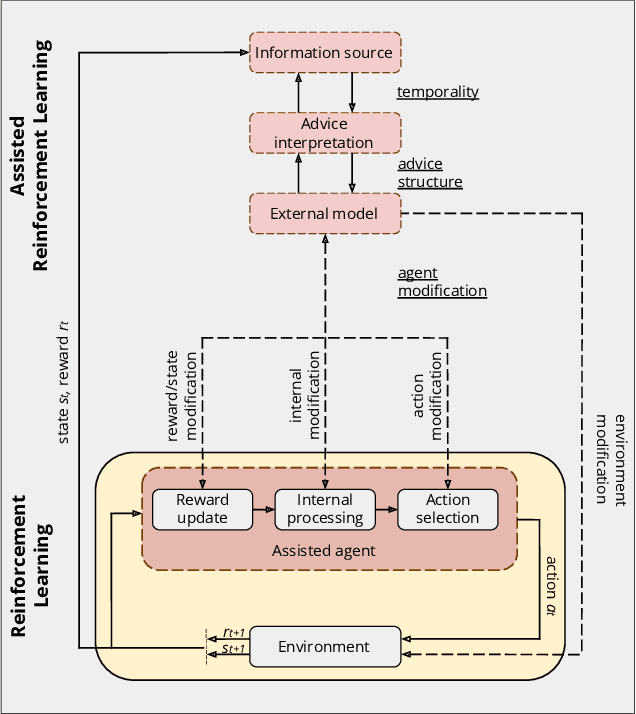
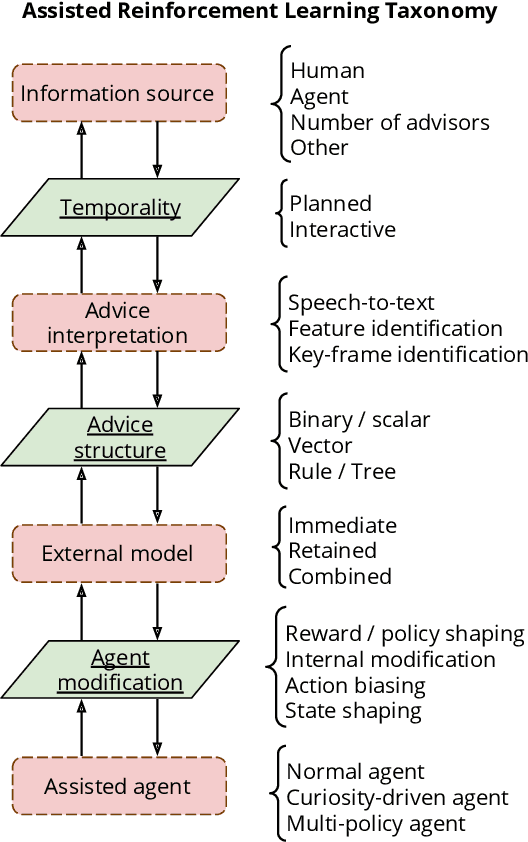
A long-term goal of reinforcement learning agents is to be able to perform tasks in complex real-world scenarios. The use of external information is one way of scaling agents to more complex problems. However, there is a general lack of collaboration or interoperability between different approaches using external information. In this work, we propose a conceptual framework and taxonomy for assisted reinforcement learning, aimed at fostering such collaboration by classifying and comparing various methods that use external information in the learning process. The proposed taxonomy details the relationship between the external information source and the learner agent, highlighting the process of information decomposition, structure, retention, and how it can be used to influence agent learning. As well as reviewing state-of-the-art methods, we identify current streams of reinforcement learning that use external information in order to improve the agent's performance and its decision-making process. These include heuristic reinforcement learning, interactive reinforcement learning, learning from demonstration, transfer learning, and learning from multiple sources, among others. These streams of reinforcement learning operate with the shared objective of scaffolding the learner agent. Lastly, we discuss further possibilities for future work in the field of assisted reinforcement learning systems.
Discrete-to-Deep Supervised Policy Learning
May 05, 2020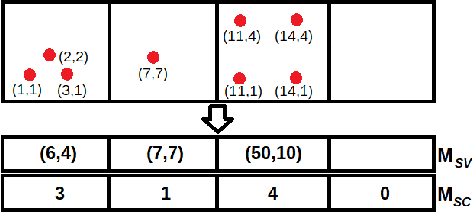
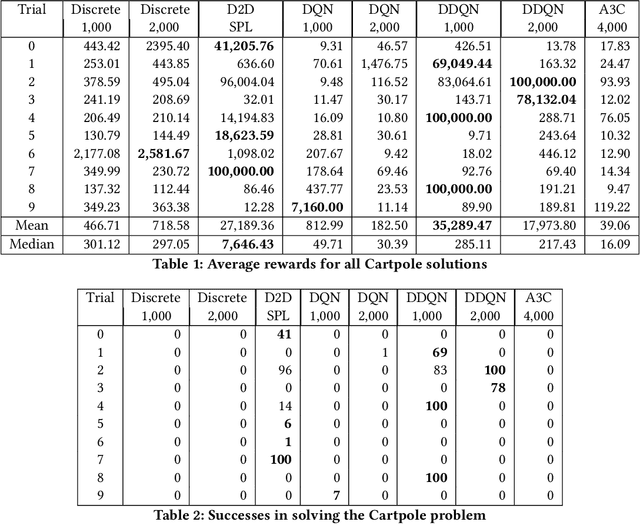
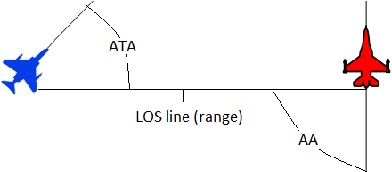
Neural networks are effective function approximators, but hard to train in the reinforcement learning (RL) context mainly because samples are correlated. For years, scholars have got around this by employing experience replay or an asynchronous parallel-agent system. This paper proposes Discrete-to-Deep Supervised Policy Learning (D2D-SPL) for training neural networks in RL. D2D-SPL discretises the continuous state space into discrete states and uses actor-critic to learn a policy. It then selects from each discrete state an input value and the action with the highest numerical preference as an input/target pair. Finally it uses input/target pairs from all discrete states to train a classifier. D2D-SPL uses a single agent, needs no experience replay and learns much faster than state-of-the-art methods. We test our method with two RL environments, the Cartpole and an aircraft manoeuvring simulator.
A Demonstration of Issues with Value-Based Multiobjective Reinforcement Learning Under Stochastic State Transitions
Apr 14, 2020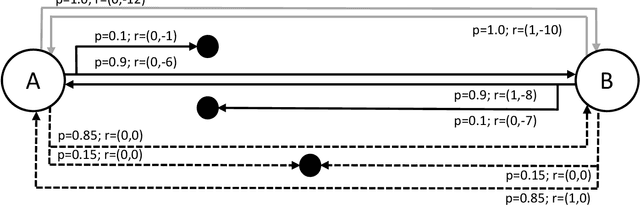

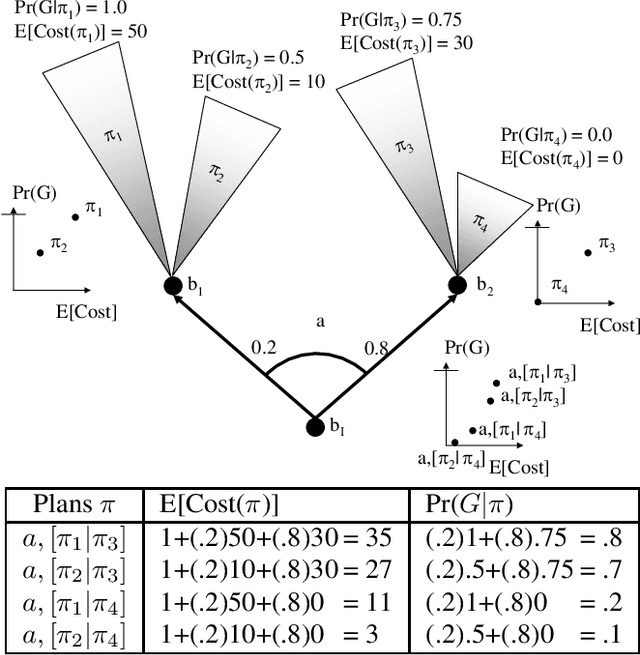
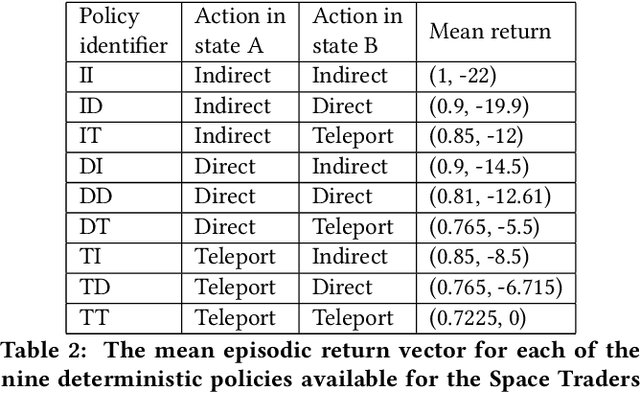
We report a previously unidentified issue with model-free, value-based approaches to multiobjective reinforcement learning in the context of environments with stochastic state transitions. An example multiobjective Markov Decision Process (MOMDP) is used to demonstrate that under such conditions these approaches may be unable to discover the policy which maximises the Scalarised Expected Return, and in fact may converge to a Pareto-dominated solution. We discuss several alternative methods which may be more suitable for maximising SER in MOMDPs with stochastic transitions.