 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse, Top-k, and Top-Quality Planning Over Simulators
Aug 25, 2023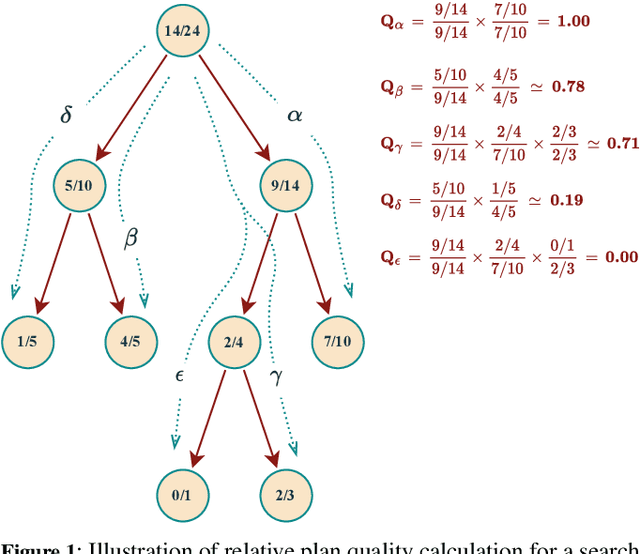
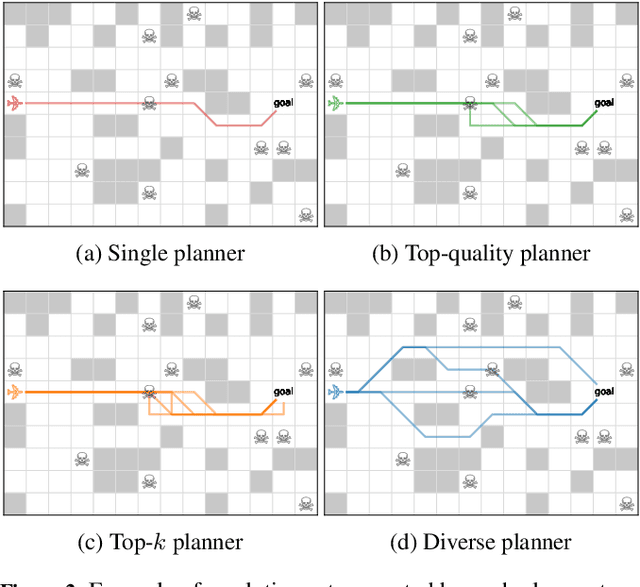

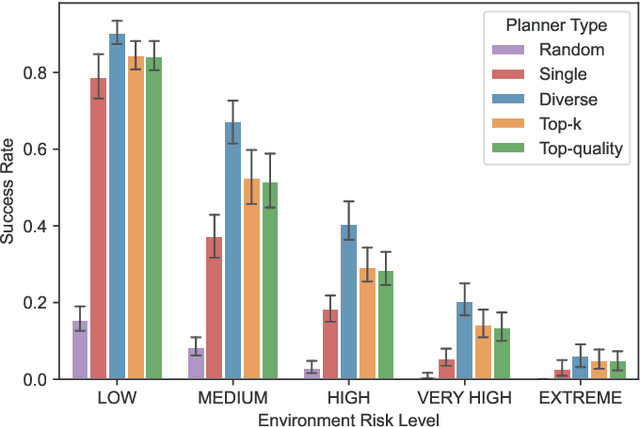
Diverse, top-k, and top-quality planning are concerned with the generation of sets of solutions to sequential decision problems. Previously this area has been the domain of classical planners that require a symbolic model of the problem instance. This paper proposes a novel alternative approach that uses Monte Carlo Tree Search (MCTS), enabling application to problems for which only a black-box simulation model is available. We present a procedure for extracting bounded sets of plans from pre-generated search trees in best-first order, and a metric for evaluating the relative quality of paths through a search tree. We demonstrate this approach on a path-planning problem with hidden information, and suggest adaptations to the MCTS algorithm to increase the diversity of generated plans. Our results show that our method can generate diverse and high-quality plan sets in domains where classical planners are not applicable.
Multi-Agent Simulation for AI Behaviour Discovery in Operations Research
Aug 30, 2021
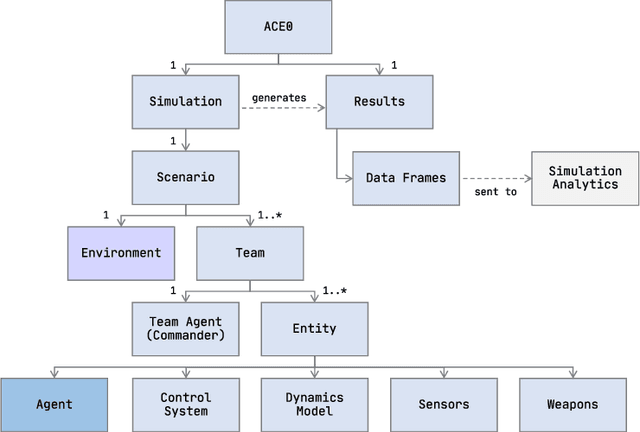
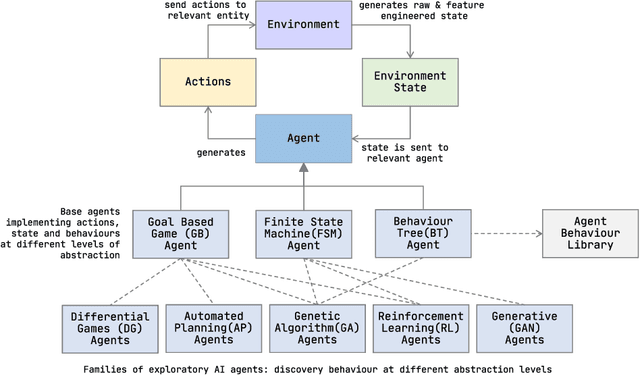
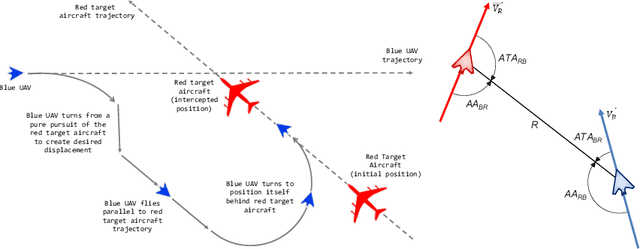
We describe ACE0, a lightweight platform for evaluating the suitability and viability of AI methods for behaviour discovery in multiagent simulations. Specifically, ACE0 was designed to explore AI methods for multi-agent simulations used in operations research studies related to new technologies such as autonomous aircraft. Simulation environments used in production are often high-fidelity, complex, require significant domain knowledge and as a result have high R&D costs. Minimal and lightweight simulation environments can help researchers and engineers evaluate the viability of new AI technologies for behaviour discovery in a more agile and potentially cost effective manner. In this paper we describe the motivation for the development of ACE0.We provide a technical overview of the system architecture, describe a case study of behaviour discovery in the aerospace domain, and provide a qualitative evaluation of the system. The evaluation includes a brief description of collaborative research projects with academic partners, exploring different AI behaviour discovery methods.
Text Generation with Deep Variational GAN
Apr 27, 2021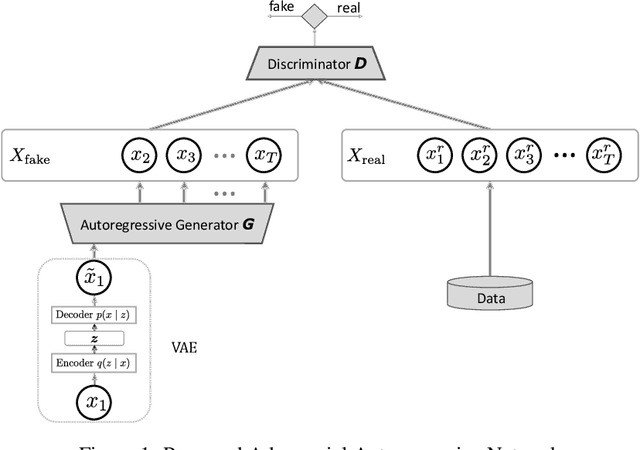


Generating realistic sequences is a central task in many machine learning applications. There has been considerable recent progress on building deep generative models for sequence generation tasks. However, the issue of mode-collapsing remains a main issue for the current models. In this paper we propose a GAN-based generic framework to address the problem of mode-collapse in a principled approach. We change the standard GAN objective to maximize a variational lower-bound of the log-likelihood while minimizing the Jensen-Shanon divergence between data and model distributions. We experiment our model with text generation task and show that it can generate realistic text with high diversity.
OptiGAN: Generative Adversarial Networks for Goal Optimized Sequence Generation
May 22, 2020
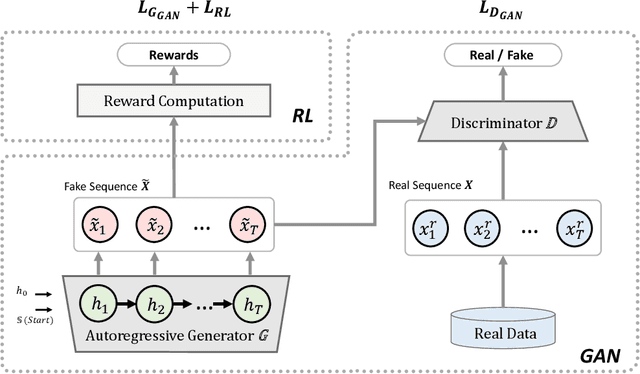
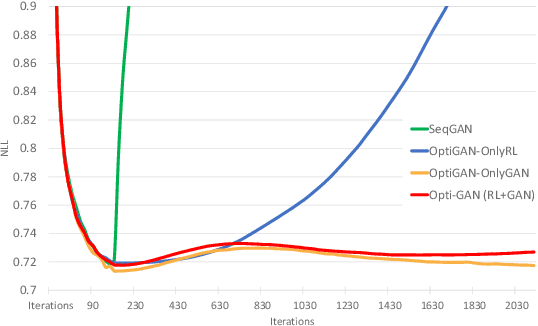
One of the challenging problems in sequence generation tasks is the optimized generation of sequences with specific desired goals. Current sequential generative models mainly generate sequences to closely mimic the training data, without direct optimization of desired goals or properties specific to the task. We introduce OptiGAN, a generative model that incorporates both Generative Adversarial Networks (GAN) and Reinforcement Learning (RL) to optimize desired goal scores using policy gradients. We apply our model to text and real-valued sequence generation, where our model is able to achieve higher desired scores out-performing GAN and RL baselines, while not sacrificing output sample diversity.
Discrete-to-Deep Supervised Policy Learning
May 05, 2020
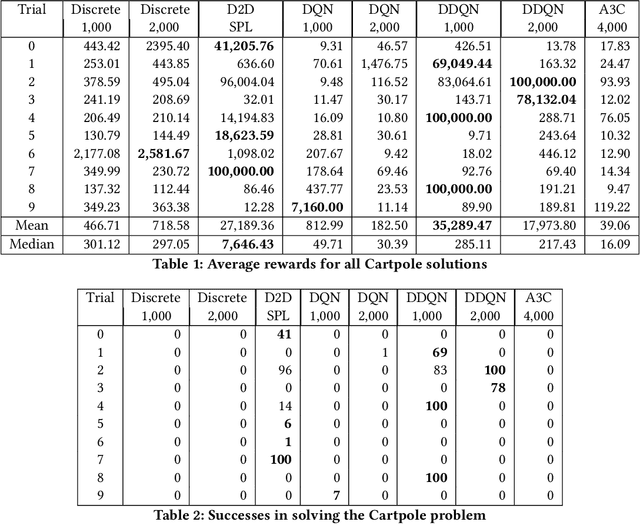
Neural networks are effective function approximators, but hard to train in the reinforcement learning (RL) context mainly because samples are correlated. For years, scholars have got around this by employing experience replay or an asynchronous parallel-agent system. This paper proposes Discrete-to-Deep Supervised Policy Learning (D2D-SPL) for training neural networks in RL. D2D-SPL discretises the continuous state space into discrete states and uses actor-critic to learn a policy. It then selects from each discrete state an input value and the action with the highest numerical preference as an input/target pair. Finally it uses input/target pairs from all discrete states to train a classifier. D2D-SPL uses a single agent, needs no experience replay and learns much faster than state-of-the-art methods. We test our method with two RL environments, the Cartpole and an aircraft manoeuvring simulator.