 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Effective Model Evaluation with Meta-Learning
May 22, 2026The rapid growth of machine learning has produced an ever-expanding ecosystem of models, making it increasingly challenging to verify the reliability of newly released models on unseen, unlabeled data. Conventional evaluation pipelines depend on expensive annotation, repeated fine-tuning, or narrow assumptions that fail to transfer across model families. We present MetaEvaluator, a cost-effective, model-agnostic framework for rapid, label-free assessment of unseen models spanning diverse architectures and modalities. MetaEvaluator leverages meta-learning over a pool of reference models to obtain a transferable initialization, enabling accurate evaluation of new models while amortizing cost across the pool and removing the need for per-model retraining. To the best of our knowledge, this is the first model-agnostic framework capable of evaluating new models on entirely unlabeled datasets. Extensive experiments show that MetaEvaluator produces stable and accurate performance estimates at substantially reduced cost compared to conventional approaches, making scalable benchmarking of emerging models on unlabeled data practical.
Neural Autoregressive Flows for Markov Boundary Learning
Mar 21, 2026Recovering Markov boundary -- the minimal set of variables that maximizes predictive performance for a response variable -- is crucial in many applications. While recent advances improve upon traditional constraint-based techniques by scoring local causal structures, they still rely on nonparametric estimators and heuristic searches, lacking theoretical guarantees for reliability. This paper investigates a framework for efficient Markov boundary discovery by integrating conditional entropy from information theory as a scoring criterion. We design a novel masked autoregressive network to capture complex dependencies. A parallelizable greedy search strategy in polynomial time is proposed, supported by analytical evidence. We also discuss how initializing a graph with learned Markov boundaries accelerates the convergence of causal discovery. Comprehensive evaluations on real-world and synthetic datasets demonstrate the scalability and superior performance of our method in both Markov boundary discovery and causal discovery tasks.
An Efficient and Effective Evaluator for Text2SQL Models on Unseen and Unlabeled Data
Mar 08, 2026Recent advances in large language models has strengthened Text2SQL systems that translate natural language questions into database queries. A persistent deployment challenge is to assess a newly trained Text2SQL system on an unseen and unlabeled dataset when no verified answers are available. This situation arises frequently because database content and structure evolve, privacy policies slow manual review, and carefully written SQL labels are costly and time-consuming. Without timely evaluation, organizations cannot approve releases or detect failures early. FusionSQL addresses this gap by working with any Text2SQL models and estimating accuracy without reference labels, allowing teams to measure quality on unseen and unlabeled datasets. It analyzes patterns in the system's own outputs to characterize how the target dataset differs from the material used during training. FusionSQL supports pre-release checks, continuous monitoring of new databases, and detection of quality decline. Experiments across diverse application settings and question types show that FusionSQL closely follows actual accuracy and reliably signals emerging issues. Our code is available at https://github.com/phkhanhtrinh23/FusionSQL.
Clustering-based Meta Bayesian Optimization with Theoretical Guarantee
Mar 08, 2025Bayesian Optimization (BO) is a well-established method for addressing black-box optimization problems. In many real-world scenarios, optimization often involves multiple functions, emphasizing the importance of leveraging data and learned functions from prior tasks to enhance efficiency in the current task. To expedite convergence to the global optimum, recent studies have introduced meta-learning strategies, collectively referred to as meta-BO, to incorporate knowledge from historical tasks. However, in practical settings, the underlying functions are often heterogeneous, which can adversely affect optimization performance for the current task. Additionally, when the number of historical tasks is large, meta-BO methods face significant scalability challenges. In this work, we propose a scalable and robust meta-BO method designed to address key challenges in heterogeneous and large-scale meta-tasks. Our approach (1) effectively partitions transferred meta-functions into highly homogeneous clusters, (2) learns the geometry-based surrogate prototype that capture the structural patterns within each cluster, and (3) adaptively synthesizes meta-priors during the online phase using statistical distance-based weighting policies. Experimental results on real-world hyperparameter optimization (HPO) tasks, combined with theoretical guarantees, demonstrate the robustness and effectiveness of our method in overcoming these challenges.
Improved and Efficient Text Adversarial Attacks using Target Information
May 02, 2021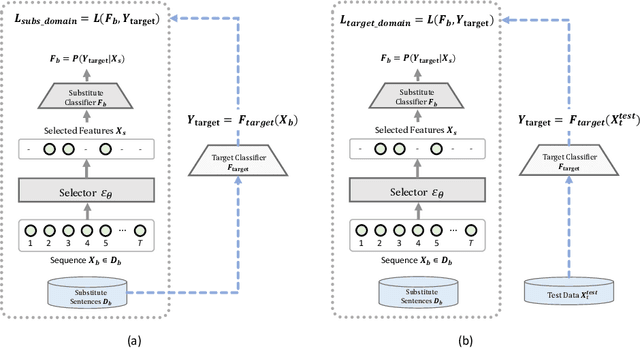
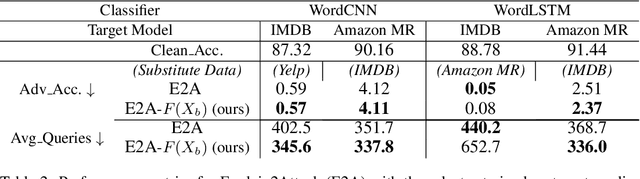
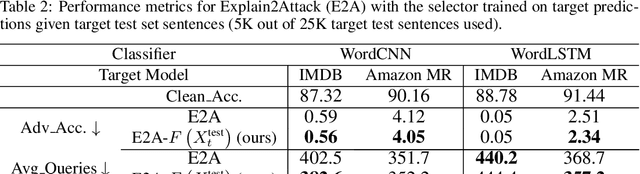
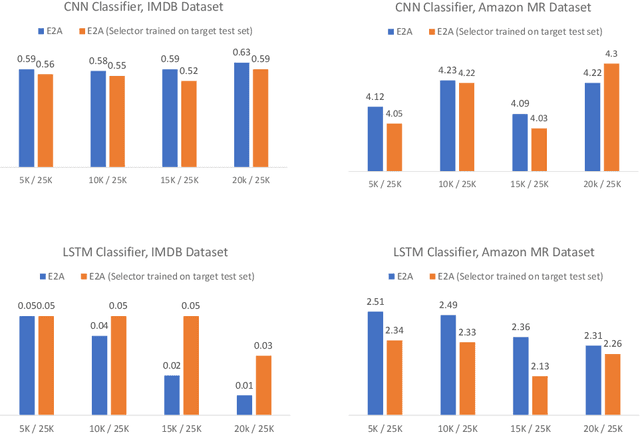
There has been recently a growing interest in studying adversarial examples on natural language models in the black-box setting. These methods attack natural language classifiers by perturbing certain important words until the classifier label is changed. In order to find these important words, these methods rank all words by importance by querying the target model word by word for each input sentence, resulting in high query inefficiency. A new interesting approach was introduced that addresses this problem through interpretable learning to learn the word ranking instead of previous expensive search. The main advantage of using this approach is that it achieves comparable attack rates to the state-of-the-art methods, yet faster and with fewer queries, where fewer queries are desirable to avoid suspicion towards the attacking agent. Nonetheless, this approach sacrificed the useful information that could be leveraged from the target classifier for that sake of query efficiency. In this paper we study the effect of leveraging the target model outputs and data on both attack rates and average number of queries, and we show that both can be improved, with a limited overhead of additional queries.
Text Generation with Deep Variational GAN
Apr 27, 2021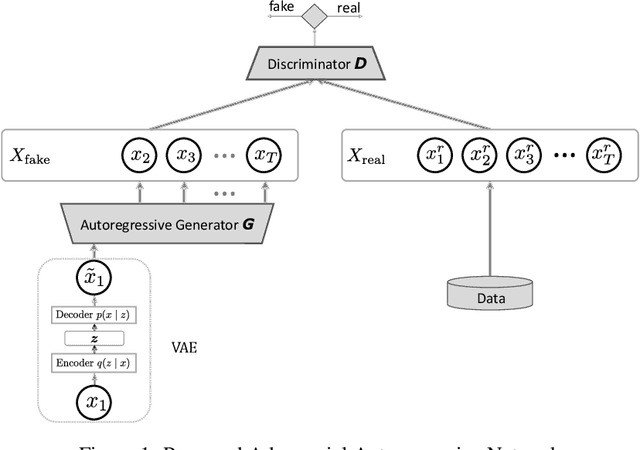


Generating realistic sequences is a central task in many machine learning applications. There has been considerable recent progress on building deep generative models for sequence generation tasks. However, the issue of mode-collapsing remains a main issue for the current models. In this paper we propose a GAN-based generic framework to address the problem of mode-collapse in a principled approach. We change the standard GAN objective to maximize a variational lower-bound of the log-likelihood while minimizing the Jensen-Shanon divergence between data and model distributions. We experiment our model with text generation task and show that it can generate realistic text with high diversity.
Topic Modelling Meets Deep Neural Networks: A Survey
Feb 28, 2021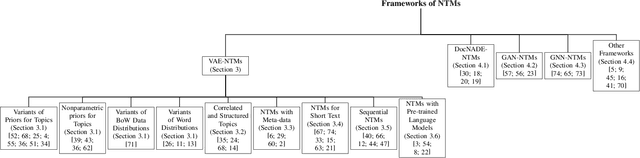
Topic modelling has been a successful technique for text analysis for almost twenty years. When topic modelling met deep neural networks, there emerged a new and increasingly popular research area, neural topic models, with over a hundred models developed and a wide range of applications in neural language understanding such as text generation, summarisation and language models. There is a need to summarise research developments and discuss open problems and future directions. In this paper, we provide a focused yet comprehensive overview of neural topic models for interested researchers in the AI community, so as to facilitate them to navigate and innovate in this fast-growing research area. To the best of our knowledge, ours is the first review focusing on this specific topic.
Neural Sinkhorn Topic Model
Aug 12, 2020
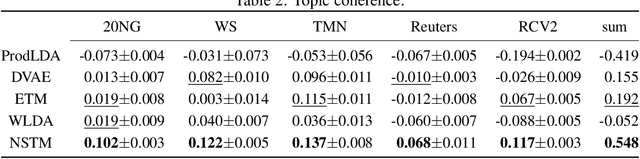
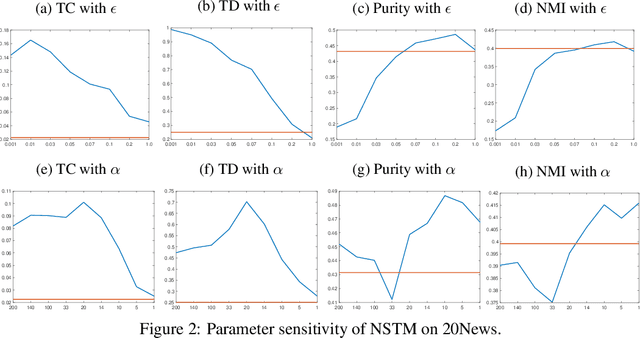
In this paper, we present a new topic modelling approach via the theory of optimal transport (OT). Specifically, we present a document with two distributions: a distribution over the words (doc-word distribution) and a distribution over the topics (doc-topic distribution). For one document, the doc-word distribution is the observed, sparse, low-level representation of the content, while the doc-topic distribution is the latent, dense, high-level one of the same content. Learning a topic model can then be viewed as a process of minimising the transportation of the semantic information from one distribution to the other. This new viewpoint leads to a novel OT-based topic modelling framework, which enjoys appealing simplicity, effectiveness, and efficiency. Extensive experiments show that our framework significantly outperforms several state-of-the-art models in terms of both topic quality and document representations.
OptiGAN: Generative Adversarial Networks for Goal Optimized Sequence Generation
May 22, 2020
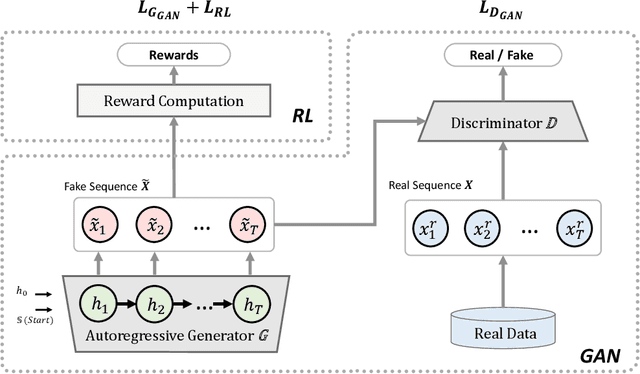
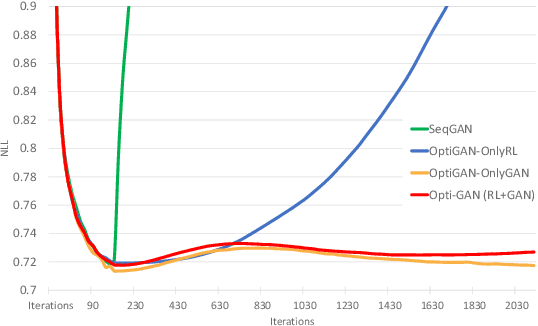
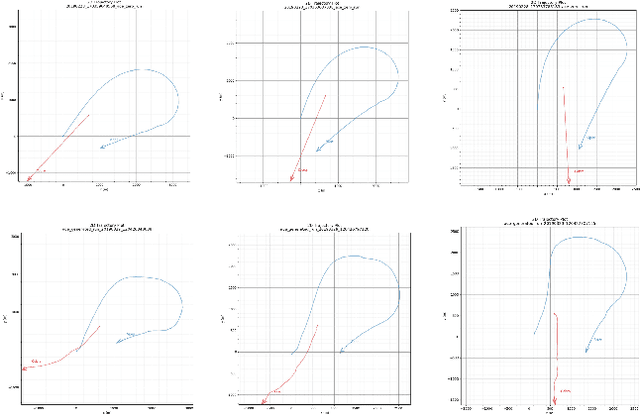
One of the challenging problems in sequence generation tasks is the optimized generation of sequences with specific desired goals. Current sequential generative models mainly generate sequences to closely mimic the training data, without direct optimization of desired goals or properties specific to the task. We introduce OptiGAN, a generative model that incorporates both Generative Adversarial Networks (GAN) and Reinforcement Learning (RL) to optimize desired goal scores using policy gradients. We apply our model to text and real-valued sequence generation, where our model is able to achieve higher desired scores out-performing GAN and RL baselines, while not sacrificing output sample diversity.
On Scalable Variant of Wasserstein Barycenter
Oct 10, 2019
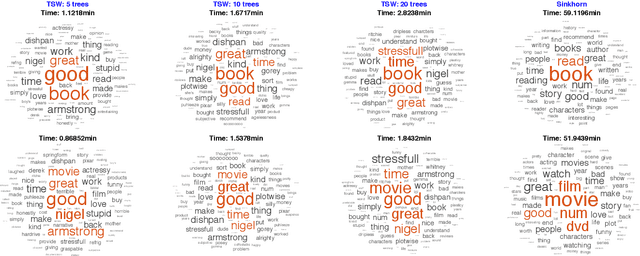
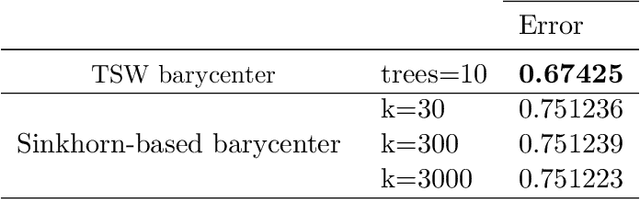
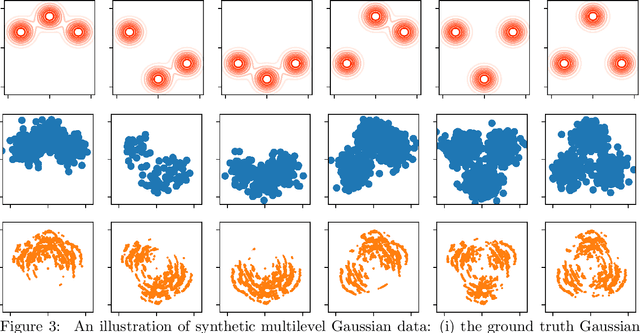
We study a variant of Wasserstein barycenter problem, which we refer to as \emph{tree-sliced Wasserstein barycenter}, by leveraging the structure of tree metrics for the ground metrics in the formulation of Wasserstein distance. Drawing on the tree structure, we propose efficient algorithms for solving the unconstrained and constrained versions of tree-sliced Wasserstein barycenter. The algorithms have fast computational time and efficient memory usage, especially for high dimensional settings while demonstrating favorable results when the tree metrics are appropriately constructed. Experimental results on large-scale synthetic and real datasets from Wasserstein barycenter for documents with word embedding, multilevel clustering, and scalable Bayes problems show the advantages of tree-sliced Wasserstein barycenter over (Sinkhorn) Wasserstein barycenter.