 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplain by Evidence: An Explainable Memory-based Neural Network for Question Answering
Nov 05, 2020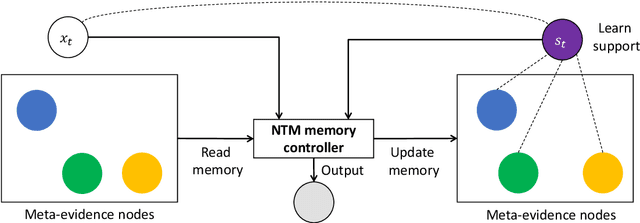
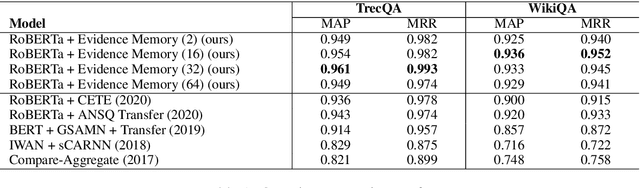

Interpretability and explainability of deep neural networks are challenging due to their scale, complexity, and the agreeable notions on which the explaining process rests. Previous work, in particular, has focused on representing internal components of neural networks through human-friendly visuals and concepts. On the other hand, in real life, when making a decision, human tends to rely on similar situations and/or associations in the past. Hence arguably, a promising approach to make the model transparent is to design it in a way such that the model explicitly connects the current sample with the seen ones, and bases its decision on these samples. Grounded on that principle, we propose in this paper an explainable, evidence-based memory network architecture, which learns to summarize the dataset and extract supporting evidences to make its decision. Our model achieves state-of-the-art performance on two popular question answering datasets (i.e. TrecQA and WikiQA). Via further analysis, we show that this model can reliably trace the errors it has made in the validation step to the training instances that might have caused these errors. We believe that this error-tracing capability provides significant benefit in improving dataset quality in many applications.
Scene Graph Modification Based on Natural Language Commands
Oct 06, 2020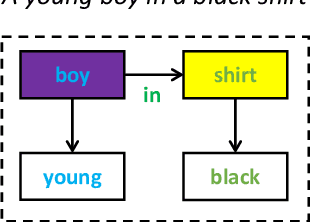
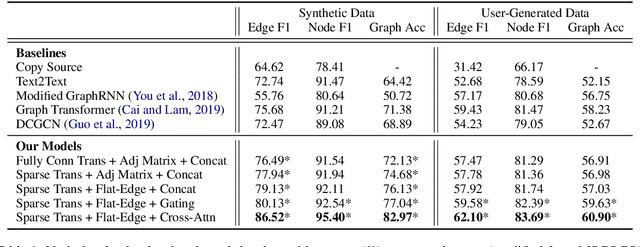
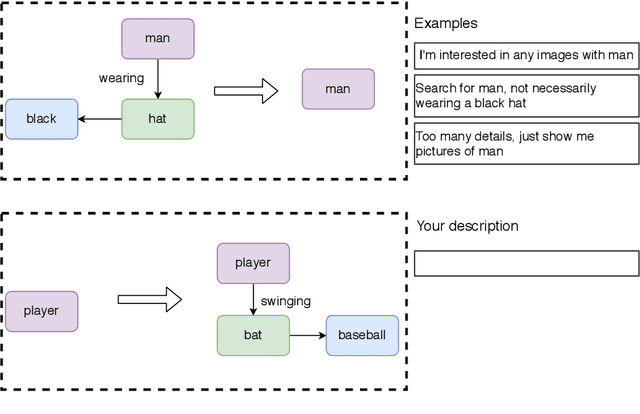
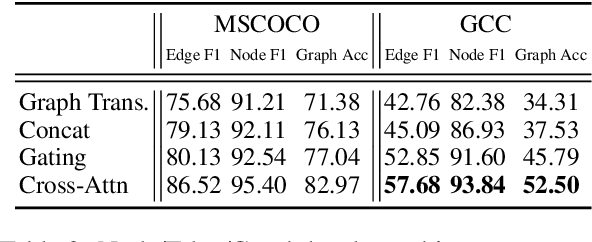
Structured representations like graphs and parse trees play a crucial role in many Natural Language Processing systems. In recent years, the advancements in multi-turn user interfaces necessitate the need for controlling and updating these structured representations given new sources of information. Although there have been many efforts focusing on improving the performance of the parsers that map text to graphs or parse trees, very few have explored the problem of directly manipulating these representations. In this paper, we explore the novel problem of graph modification, where the systems need to learn how to update an existing scene graph given a new user's command. Our novel models based on graph-based sparse transformer and cross attention information fusion outperform previous systems adapted from the machine translation and graph generation literature. We further contribute our large graph modification datasets to the research community to encourage future research for this new problem.
On Efficient Multilevel Clustering via Wasserstein Distances
Sep 19, 2019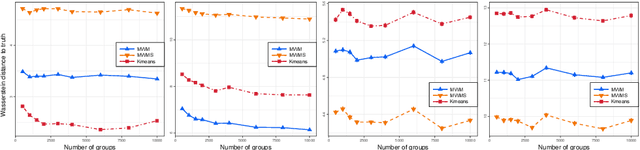
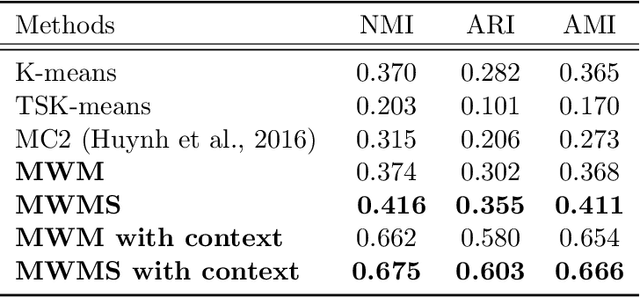
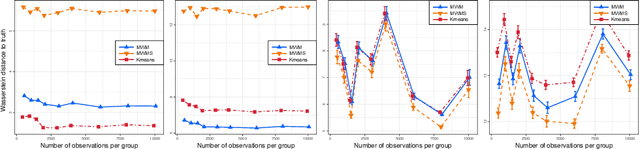

We propose a novel approach to the problem of multilevel clustering, which aims to simultaneously partition data in each group and discover grouping patterns among groups in a potentially large hierarchically structured corpus of data. Our method involves a joint optimization formulation over several spaces of discrete probability measures, which are endowed with Wasserstein distance metrics. We propose several variants of this problem, which admit fast optimization algorithms, by exploiting the connection to the problem of finding Wasserstein barycenters. Consistency properties are established for the estimates of both local and global clusters. Finally, the experimental results with both synthetic and real data are presented to demonstrate the flexibility and scalability of the proposed approach.