 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Reliable Neural Specifications
Nov 14, 2022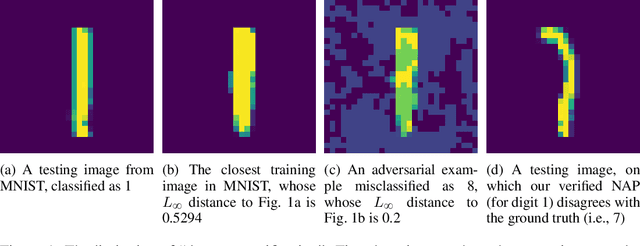

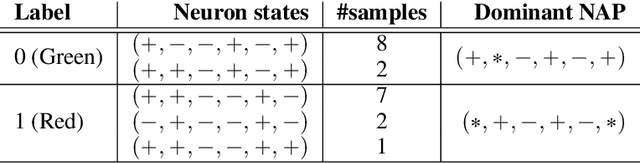
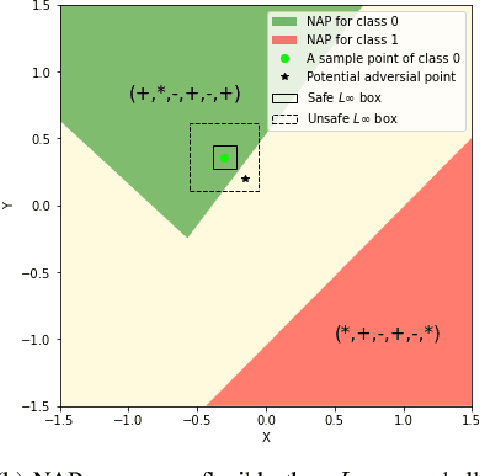
Having reliable specifications is an unavoidable challenge in achieving verifiable correctness, robustness, and interpretability of AI systems. Existing specifications for neural networks are in the paradigm of data as specification. That is, the local neighborhood centering around a reference input is considered to be correct (or robust). However, our empirical study shows that such a specification is extremely overfitted since usually no data points from the testing set lie in the certified region of the reference input, making them impractical for real-world applications. We propose a new family of specifications called neural representation as specification, which uses the intrinsic information of neural networks - neural activation patterns (NAP), rather than input data to specify the correctness and/or robustness of neural network predictions. We present a simple statistical approach to mining dominant neural activation patterns. We analyze NAPs from a statistical point of view and find that a single NAP can cover a large number of training and testing data points whereas ad hoc data-as-specification only covers the given reference data point. To show the effectiveness of discovered NAPs, we formally verify several important properties, such as various types of misclassifications will never happen for a given NAP, and there is no-ambiguity between different NAPs. We show that by using NAP, we can verify the prediction of the entire input space, while still recalling 84% of the data. Thus, we argue that using NAPs is a more reliable and extensible specification for neural network verification.
AutoNLU: An On-demand Cloud-based Natural Language Understanding System for Enterprises
Nov 26, 2020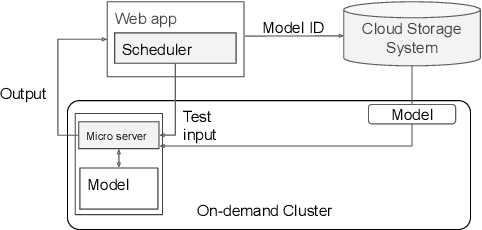
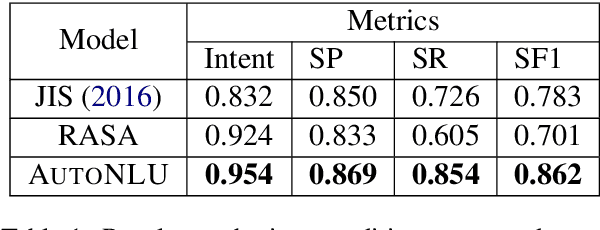
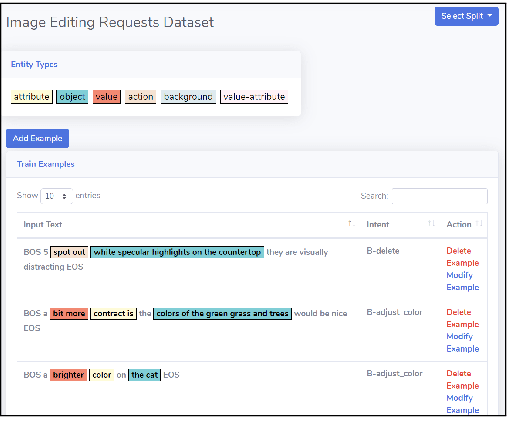
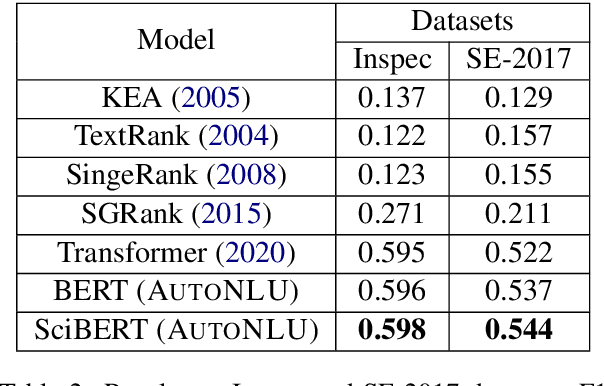
With the renaissance of deep learning, neural networks have achieved promising results on many natural language understanding (NLU) tasks. Even though the source codes of many neural network models are publicly available, there is still a large gap from open-sourced models to solving real-world problems in enterprises. Therefore, to fill this gap, we introduce AutoNLU, an on-demand cloud-based system with an easy-to-use interface that covers all common use-cases and steps in developing an NLU model. AutoNLU has supported many product teams within Adobe with different use-cases and datasets, quickly delivering them working models. To demonstrate the effectiveness of AutoNLU, we present two case studies. i) We build a practical NLU model for handling various image-editing requests in Photoshop. ii) We build powerful keyphrase extraction models that achieve state-of-the-art results on two public benchmarks. In both cases, end users only need to write a small amount of code to convert their datasets into a common format used by AutoNLU.
Explain by Evidence: An Explainable Memory-based Neural Network for Question Answering
Nov 05, 2020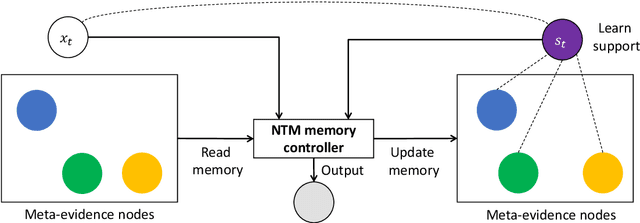
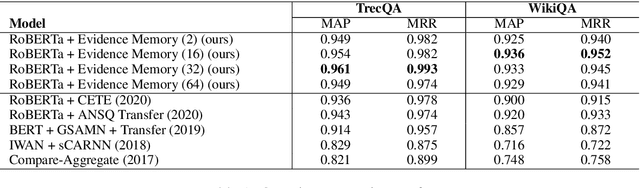

Interpretability and explainability of deep neural networks are challenging due to their scale, complexity, and the agreeable notions on which the explaining process rests. Previous work, in particular, has focused on representing internal components of neural networks through human-friendly visuals and concepts. On the other hand, in real life, when making a decision, human tends to rely on similar situations and/or associations in the past. Hence arguably, a promising approach to make the model transparent is to design it in a way such that the model explicitly connects the current sample with the seen ones, and bases its decision on these samples. Grounded on that principle, we propose in this paper an explainable, evidence-based memory network architecture, which learns to summarize the dataset and extract supporting evidences to make its decision. Our model achieves state-of-the-art performance on two popular question answering datasets (i.e. TrecQA and WikiQA). Via further analysis, we show that this model can reliably trace the errors it has made in the validation step to the training instances that might have caused these errors. We believe that this error-tracing capability provides significant benefit in improving dataset quality in many applications.
A System for Automated Image Editing from Natural Language Commands
Dec 03, 2018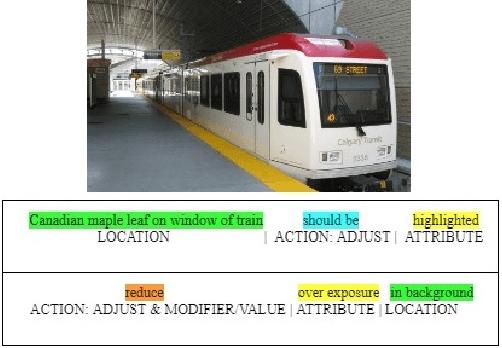
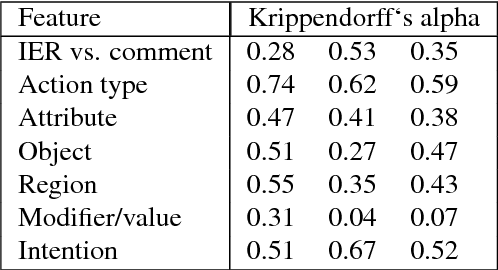
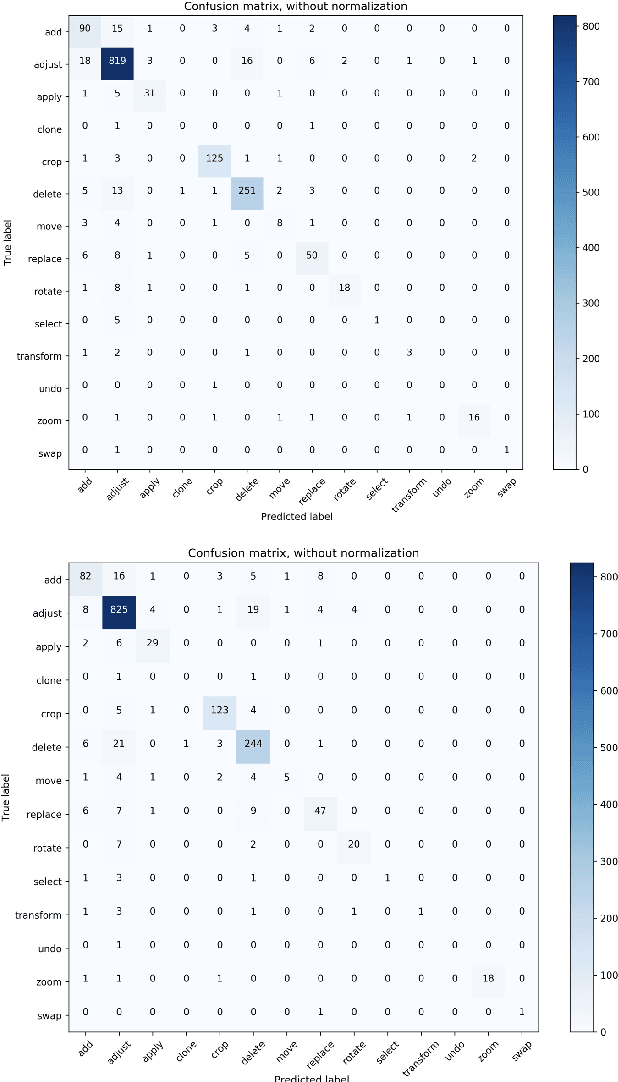
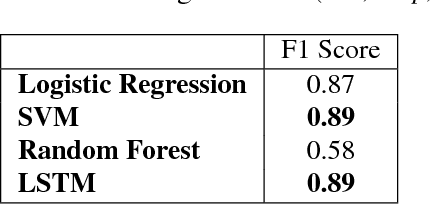
This work presents the task of modifying images in an image editing program using natural language written commands. We utilize a corpus of over 6000 image edit text requests to alter real world images collected via crowdsourcing. A novel framework composed of actions and entities to map a user's natural language request to executable commands in an image editing program is described. We resolve previously labeled annotator disagreement through a voting process and complete annotation of the corpus. We experimented with different machine learning models and found that the LSTM, the SVM, and the bidirectional LSTM-CRF joint models are the best to detect image editing actions and associated entities in a given utterance.