 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning Protein Language Models with Deep Mutational Scanning improves Variant Effect Prediction
May 10, 2024
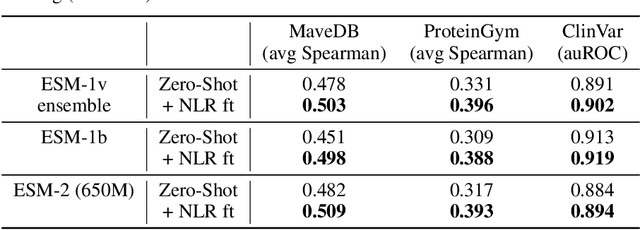

Protein Language Models (PLMs) have emerged as performant and scalable tools for predicting the functional impact and clinical significance of protein-coding variants, but they still lag experimental accuracy. Here, we present a novel fine-tuning approach to improve the performance of PLMs with experimental maps of variant effects from Deep Mutational Scanning (DMS) assays using a Normalised Log-odds Ratio (NLR) head. We find consistent improvements in a held-out protein test set, and on independent DMS and clinical variant annotation benchmarks from ProteinGym and ClinVar. These findings demonstrate that DMS is a promising source of sequence diversity and supervised training data for improving the performance of PLMs for variant effect prediction.
Improved and Efficient Text Adversarial Attacks using Target Information
May 02, 2021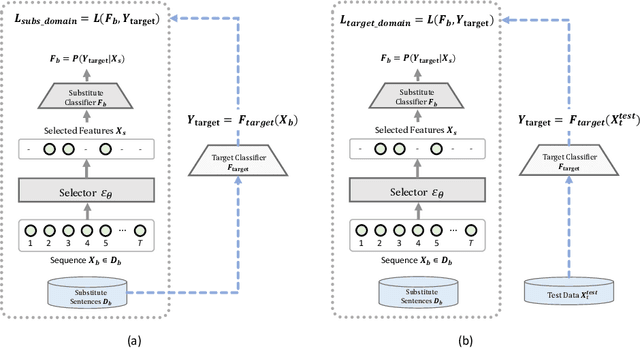
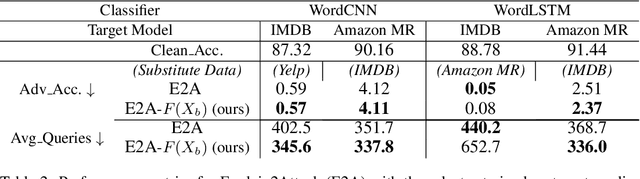
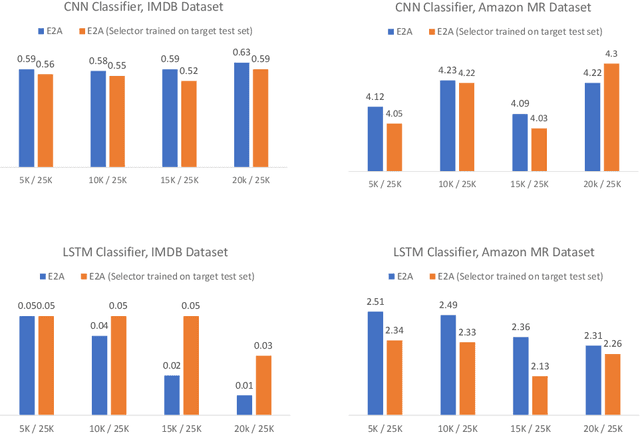
There has been recently a growing interest in studying adversarial examples on natural language models in the black-box setting. These methods attack natural language classifiers by perturbing certain important words until the classifier label is changed. In order to find these important words, these methods rank all words by importance by querying the target model word by word for each input sentence, resulting in high query inefficiency. A new interesting approach was introduced that addresses this problem through interpretable learning to learn the word ranking instead of previous expensive search. The main advantage of using this approach is that it achieves comparable attack rates to the state-of-the-art methods, yet faster and with fewer queries, where fewer queries are desirable to avoid suspicion towards the attacking agent. Nonetheless, this approach sacrificed the useful information that could be leveraged from the target classifier for that sake of query efficiency. In this paper we study the effect of leveraging the target model outputs and data on both attack rates and average number of queries, and we show that both can be improved, with a limited overhead of additional queries.
Text Generation with Deep Variational GAN
Apr 27, 2021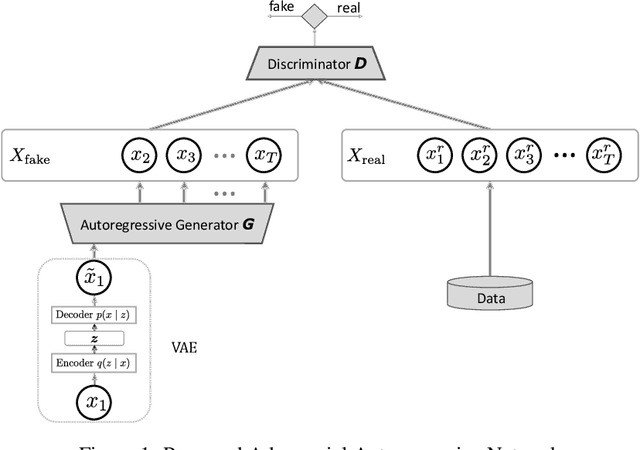


Generating realistic sequences is a central task in many machine learning applications. There has been considerable recent progress on building deep generative models for sequence generation tasks. However, the issue of mode-collapsing remains a main issue for the current models. In this paper we propose a GAN-based generic framework to address the problem of mode-collapse in a principled approach. We change the standard GAN objective to maximize a variational lower-bound of the log-likelihood while minimizing the Jensen-Shanon divergence between data and model distributions. We experiment our model with text generation task and show that it can generate realistic text with high diversity.
Explain2Attack: Text Adversarial Attacks via Cross-Domain Interpretability
Oct 21, 2020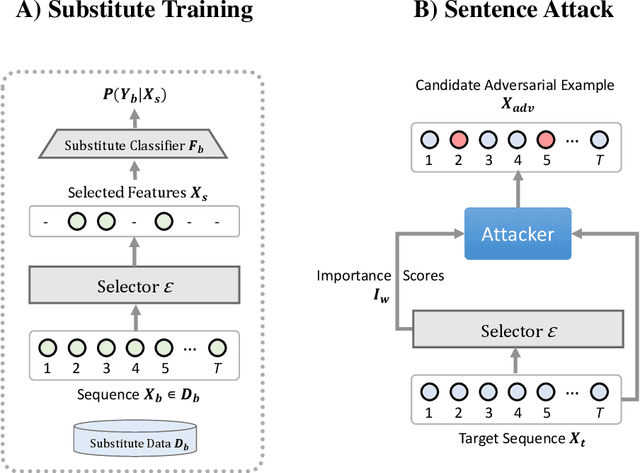
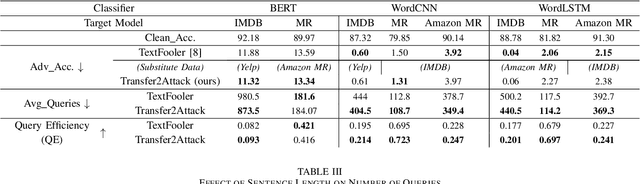
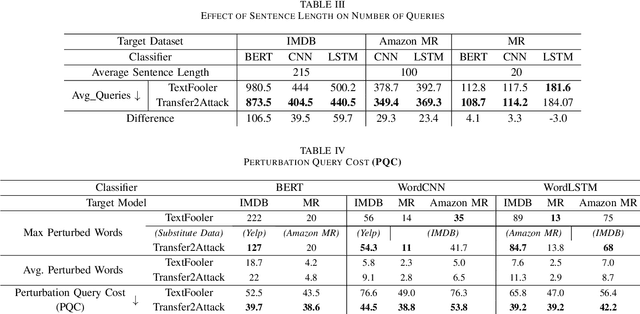

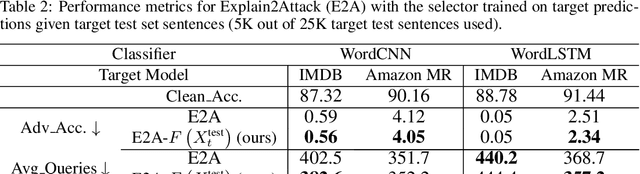
Training robust deep learning models for down-stream tasks is a critical challenge. Research has shown that down-stream models can be easily fooled with adversarial inputs that look like the training data, but slightly perturbed, in a way imperceptible to humans. Understanding the behavior of natural language models under these attacks is crucial to better defend these models against such attacks. In the black-box attack setting, where no access to model parameters is available, the attacker can only query the output information from the targeted model to craft a successful attack. Current black-box state-of-the-art models are costly in both computational complexity and number of queries needed to craft successful adversarial examples. For real world scenarios, the number of queries is critical, where less queries are desired to avoid suspicion towards an attacking agent. In this paper, we propose Explain2Attack, a black-box adversarial attack on text classification task. Instead of searching for important words to be perturbed by querying the target model, Explain2Attack employs an interpretable substitute model from a similar domain to learn word importance scores. We show that our framework either achieves or out-performs attack rates of the state-of-the-art models, yet with lower queries cost and higher efficiency.
OptiGAN: Generative Adversarial Networks for Goal Optimized Sequence Generation
May 22, 2020
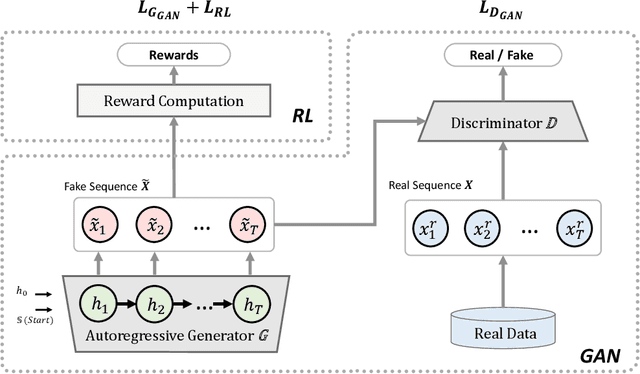
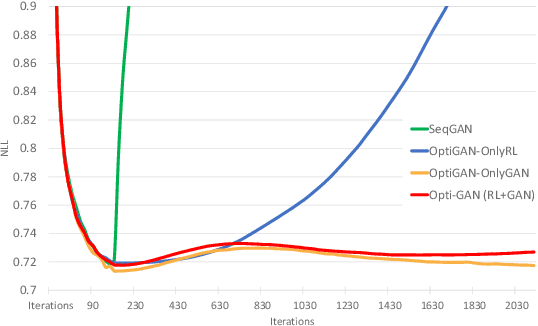
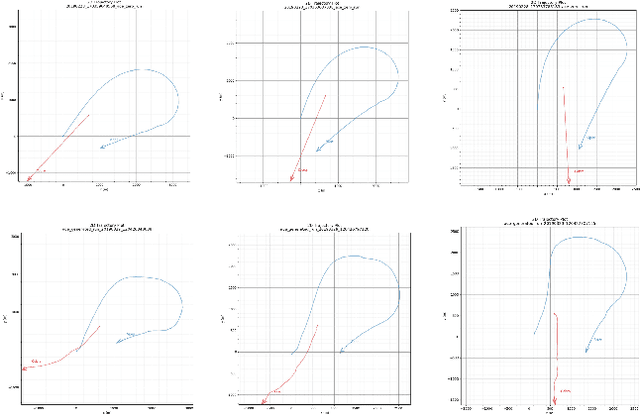
One of the challenging problems in sequence generation tasks is the optimized generation of sequences with specific desired goals. Current sequential generative models mainly generate sequences to closely mimic the training data, without direct optimization of desired goals or properties specific to the task. We introduce OptiGAN, a generative model that incorporates both Generative Adversarial Networks (GAN) and Reinforcement Learning (RL) to optimize desired goal scores using policy gradients. We apply our model to text and real-valued sequence generation, where our model is able to achieve higher desired scores out-performing GAN and RL baselines, while not sacrificing output sample diversity.