 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplain2Attack: Text Adversarial Attacks via Cross-Domain Interpretability
Paper and Code
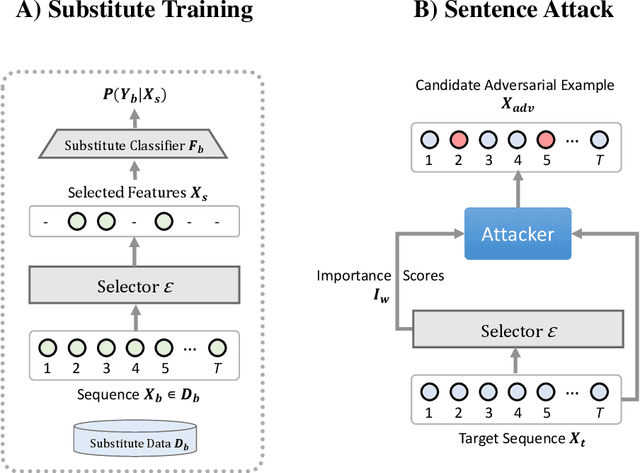
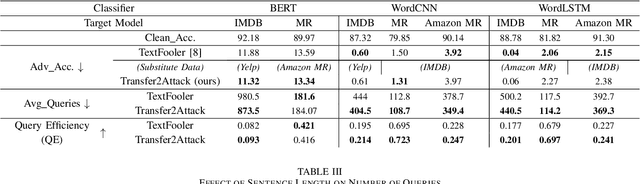
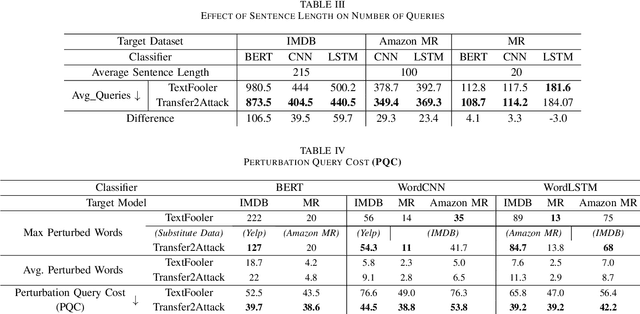

Training robust deep learning models for down-stream tasks is a critical challenge. Research has shown that down-stream models can be easily fooled with adversarial inputs that look like the training data, but slightly perturbed, in a way imperceptible to humans. Understanding the behavior of natural language models under these attacks is crucial to better defend these models against such attacks. In the black-box attack setting, where no access to model parameters is available, the attacker can only query the output information from the targeted model to craft a successful attack. Current black-box state-of-the-art models are costly in both computational complexity and number of queries needed to craft successful adversarial examples. For real world scenarios, the number of queries is critical, where less queries are desired to avoid suspicion towards an attacking agent. In this paper, we propose Explain2Attack, a black-box adversarial attack on text classification task. Instead of searching for important words to be perturbed by querying the target model, Explain2Attack employs an interpretable substitute model from a similar domain to learn word importance scores. We show that our framework either achieves or out-performs attack rates of the state-of-the-art models, yet with lower queries cost and higher efficiency.