 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompatibility of Fairness Metrics with EU Non-Discrimination Laws: Demographic Parity & Conditional Demographic Disparity
Jun 14, 2023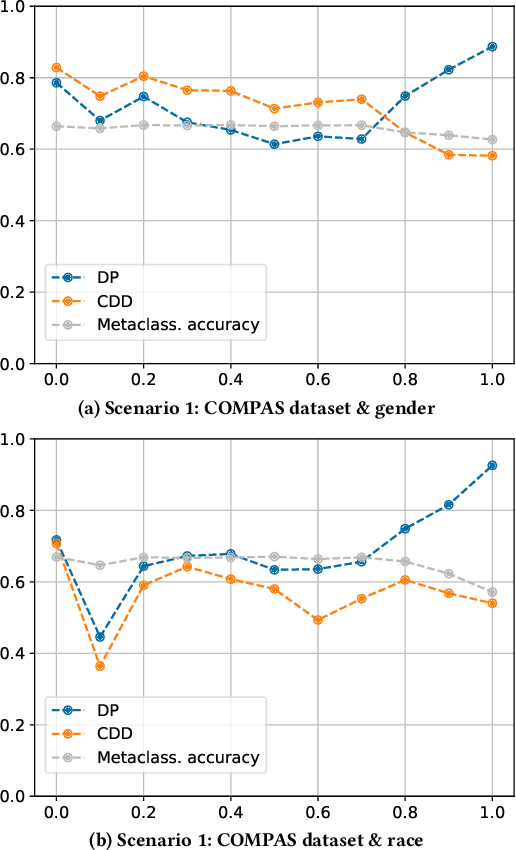
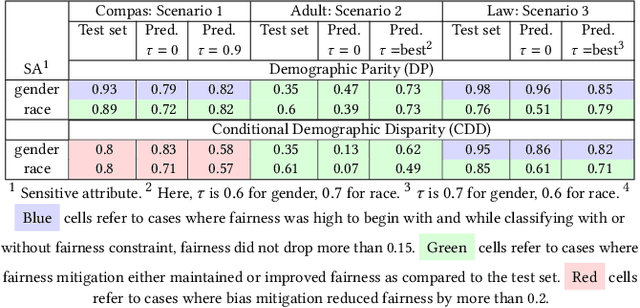
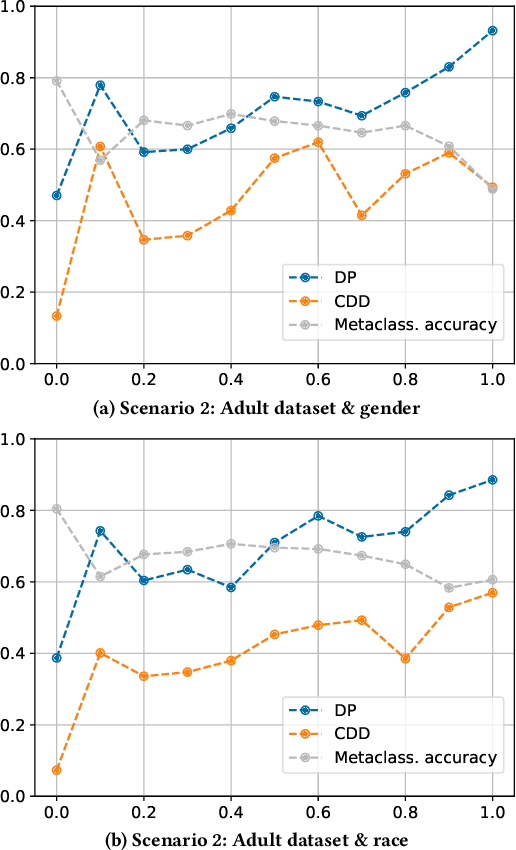
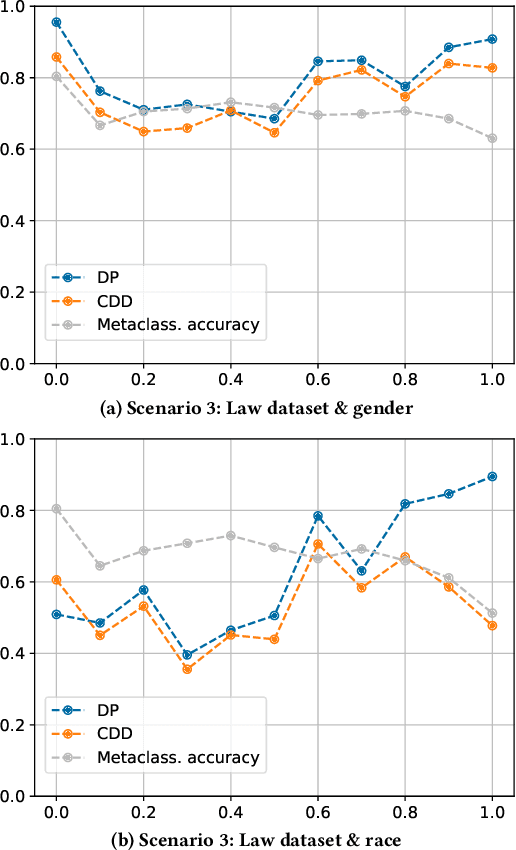
Empirical evidence suggests that algorithmic decisions driven by Machine Learning (ML) techniques threaten to discriminate against legally protected groups or create new sources of unfairness. This work supports the contextual approach to fairness in EU non-discrimination legal framework and aims at assessing up to what point we can assure legal fairness through fairness metrics and under fairness constraints. For that, we analyze the legal notion of non-discrimination and differential treatment with the fairness definition Demographic Parity (DP) through Conditional Demographic Disparity (CDD). We train and compare different classifiers with fairness constraints to assess whether it is possible to reduce bias in the prediction while enabling the contextual approach to judicial interpretation practiced under EU non-discrimination laws. Our experimental results on three scenarios show that the in-processing bias mitigation algorithm leads to different performances in each of them. Our experiments and analysis suggest that AI-assisted decision-making can be fair from a legal perspective depending on the case at hand and the legal justification. These preliminary results encourage future work which will involve further case studies, metrics, and fairness notions.
Malware Analysis with Symbolic Execution and Graph Kernel
Apr 12, 2022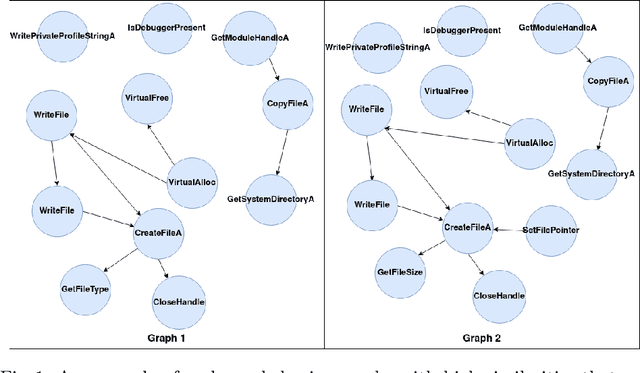

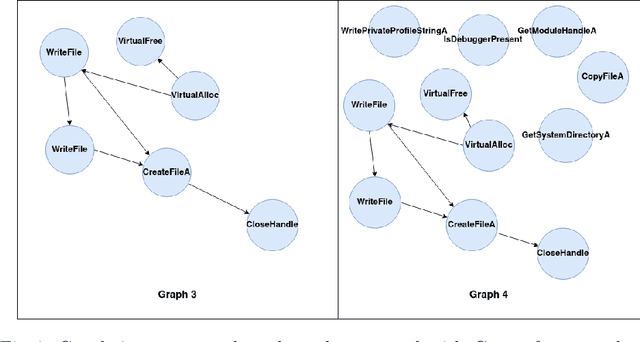
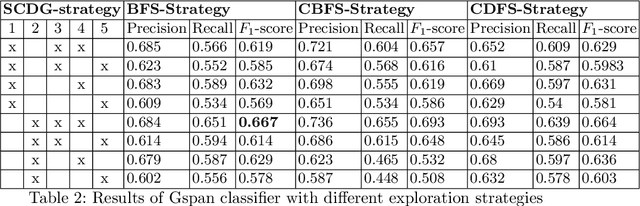
Malware analysis techniques are divided into static and dynamic analysis. Both techniques can be bypassed by circumvention techniques such as obfuscation. In a series of works, the authors have promoted the use of symbolic executions combined with machine learning to avoid such traps. Most of those works rely on natural graph-based representations that can then be plugged into graph-based learning algorithms such as Gspan. There are two main problems with this approach. The first one is in the cost of computing the graph. Indeed, working with graphs requires one to compute and representing the entire state-space of the file under analysis. As such computation is too cumbersome, the techniques often rely on developing strategies to compute a representative subgraph of the behaviors. Unfortunately, efficient graph-building strategies remain weakly explored. The second problem is in the classification itself. Graph-based machine learning algorithms rely on comparing the biggest common structures. This sidelines small but specific parts of the malware signature. In addition, it does not allow us to work with efficient algorithms such as support vector machine. We propose a new efficient open source toolchain for machine learning-based classification. We also explore how graph-kernel techniques can be used in the process. We focus on the 1-dimensional Weisfeiler-Lehman kernel, which can capture local similarities between graphs. Our experimental results show that our approach outperforms existing ones by an impressive factor.
Analysis of Machine Learning Approaches to Packing Detection
May 02, 2021

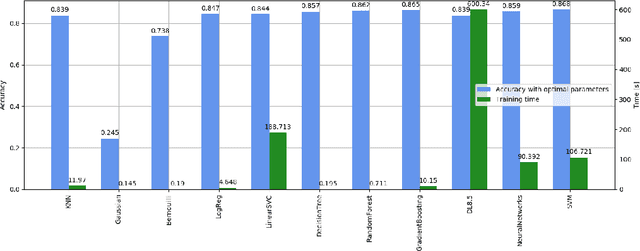

Packing is an obfuscation technique widely used by malware to hide the content and behavior of a program. Much prior research has explored how to detect whether a program is packed. This research includes a broad variety of approaches such as entropy analysis, syntactic signatures and more recently machine learning classifiers using various features. However, no robust results have indicated which algorithms perform best, or which features are most significant. This is complicated by considering how to evaluate the results since accuracy, cost, generalization capabilities, and other measures are all reasonable. This work explores eleven different machine learning approaches using 119 features to understand: which features are most significant for packing detection; which algorithms offer the best performance; and which algorithms are most economical.
Secure Architectures Implementing Trusted Coalitions for Blockchained Distributed Learning (TCLearn)
Jun 18, 2019
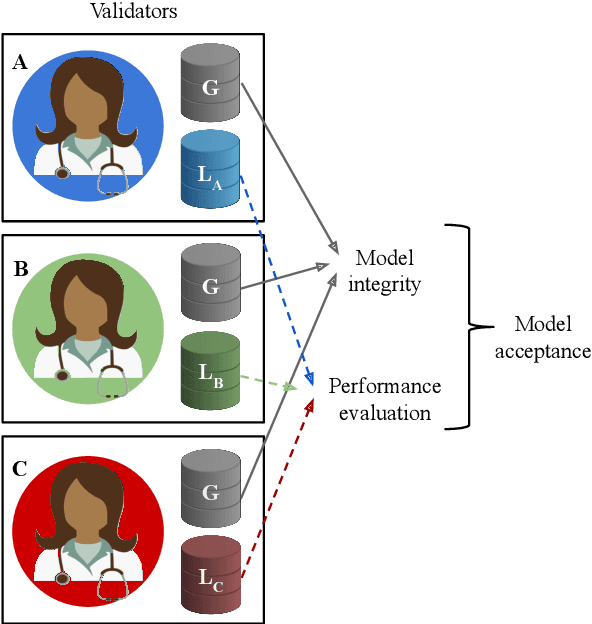
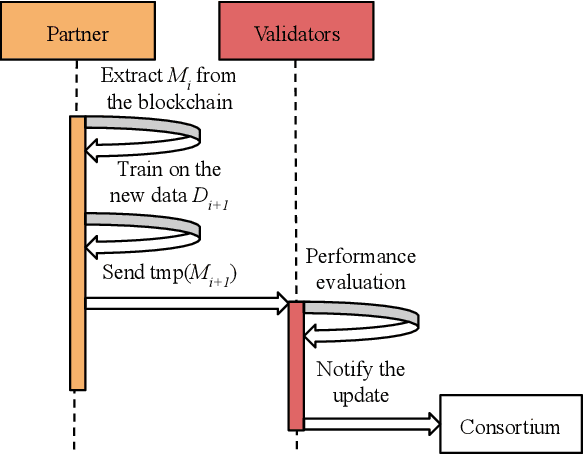
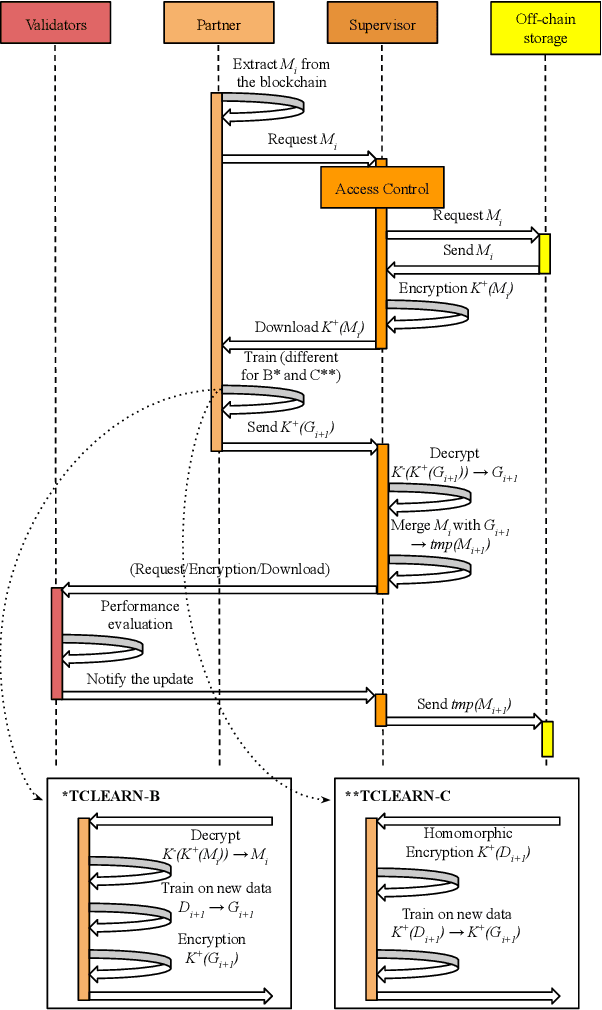
Distributed learning across a coalition of organizations allows the members of the coalition to train and share a model without sharing the data used to optimize this model. In this paper, we propose new secure architectures that guarantee preservation of data privacy, trustworthy sequence of iterative learning and equitable sharing of the learned model among each member of the coalition by using adequate encryption and blockchain mechanisms. We exemplify its deployment in the case of the distributed optimization of a deep learning convolutional neural network trained on medical images.
Scalable Verification of Markov Decision Processes
Sep 17, 2014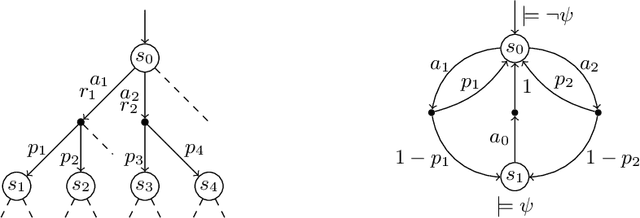
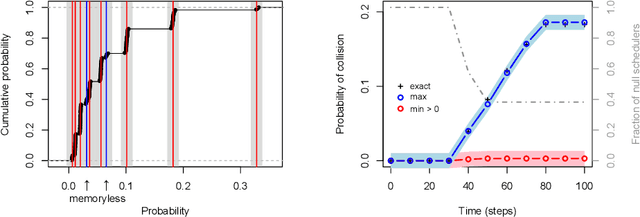
Markov decision processes (MDP) are useful to model concurrent process optimisation problems, but verifying them with numerical methods is often intractable. Existing approximative approaches do not scale well and are limited to memoryless schedulers. Here we present the basis of scalable verification for MDPSs, using an O(1) memory representation of history-dependent schedulers. We thus facilitate scalable learning techniques and the use of massively parallel verification.
Measuring Global Similarity between Texts
May 14, 2014
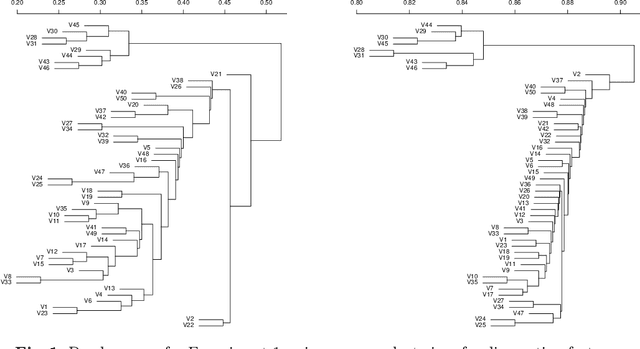
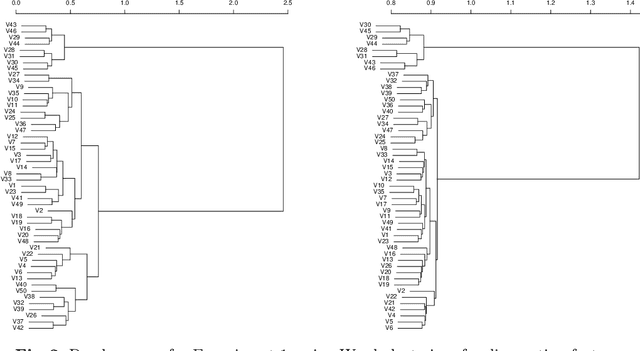
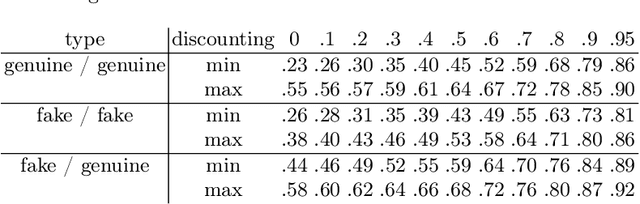
We propose a new similarity measure between texts which, contrary to the current state-of-the-art approaches, takes a global view of the texts to be compared. We have implemented a tool to compute our textual distance and conducted experiments on several corpuses of texts. The experiments show that our methods can reliably identify different global types of texts.
Proceedings Quantities in Formal Methods
Dec 14, 2012This volume contains the proceedings of the Workshop on Quantities in Formal Methods, QFM 2012, held in Paris, France on 28 August 2012. The workshop was affiliated with the 18th Symposium on Formal Methods, FM 2012. The focus of the workshop was on quantities in modeling, verification, and synthesis. Modern applications of formal methods require to reason formally on quantities such as time, resources, or probabilities. Standard formal methods and tools have gotten very good at modeling (and verifying) qualitative properties: whether or not certain events will occur. During the last years, these methods and tools have been extended to also cover quantitative aspects, notably leading to tools like e.g. UPPAAL (for real-time systems), PRISM (for probabilistic systems), and PHAVer (for hybrid systems). A lot of work remains to be done however before these tools can be used in the industrial applications at which they are aiming.