 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI in Support of Diversity and Inclusion
Jan 16, 2025

In this paper, we elaborate on how AI can support diversity and inclusion and exemplify research projects conducted in that direction. We start by looking at the challenges and progress in making large language models (LLMs) more transparent, inclusive, and aware of social biases. Even though LLMs like ChatGPT have impressive abilities, they struggle to understand different cultural contexts and engage in meaningful, human like conversations. A key issue is that biases in language processing, especially in machine translation, can reinforce inequality. Tackling these biases requires a multidisciplinary approach to ensure AI promotes diversity, fairness, and inclusion. We also highlight AI's role in identifying biased content in media, which is important for improving representation. By detecting unequal portrayals of social groups, AI can help challenge stereotypes and create more inclusive technologies. Transparent AI algorithms, which clearly explain their decisions, are essential for building trust and reducing bias in AI systems. We also stress AI systems need diverse and inclusive training data. Projects like the Child Growth Monitor show how using a wide range of data can help address real world problems like malnutrition and poverty. We present a project that demonstrates how AI can be applied to monitor the role of search engines in spreading disinformation about the LGBTQ+ community. Moreover, we discuss the SignON project as an example of how technology can bridge communication gaps between hearing and deaf people, emphasizing the importance of collaboration and mutual trust in developing inclusive AI. Overall, with this paper, we advocate for AI systems that are not only effective but also socially responsible, promoting fair and inclusive interactions between humans and machines.
ColorwAI: Generative Colorways of Textiles through GAN and Diffusion Disentanglement
Jul 16, 2024Colorway creation is the task of generating textile samples in alternate color variations maintaining an underlying pattern. The individuation of a suitable color palette for a colorway is a complex creative task, responding to client and market needs, stylistic and cultural specifications, and mood. We introduce a modification of this task, the "generative colorway" creation, that includes minimal shape modifications, and propose a framework, "ColorwAI", to tackle this task using color disentanglement on StyleGAN and Diffusion. We introduce a variation of the InterfaceGAN method for supervised disentanglement, ShapleyVec. We use Shapley values to subselect a few dimensions of the detected latent direction. Moreover, we introduce a general framework to adopt common disentanglement methods on any architecture with a semantic latent space and test it on Diffusion and GANs. We interpret the color representations within the models' latent space. We find StyleGAN's W space to be the most aligned with human notions of color. Finally, we suggest that disentanglement can solicit a creative system for colorway creation, and evaluate it through expert questionnaires and creativity theory.
Synthetic images aid the recognition of human-made art forgeries
Dec 28, 2023Previous research has shown that Artificial Intelligence is capable of distinguishing between authentic paintings by a given artist and human-made forgeries with remarkable accuracy, provided sufficient training. However, with the limited amount of existing known forgeries, augmentation methods for forgery detection are highly desirable. In this work, we examine the potential of incorporating synthetic artworks into training datasets to enhance the performance of forgery detection. Our investigation focuses on paintings by Vincent van Gogh, for which we release the first dataset specialized for forgery detection. To reinforce our results, we conduct the same analyses on the artists Amedeo Modigliani and Raphael. We train a classifier to distinguish original artworks from forgeries. For this, we use human-made forgeries and imitations in the style of well-known artists and augment our training sets with images in a similar style generated by Stable Diffusion and StyleGAN. We find that the additional synthetic forgeries consistently improve the detection of human-made forgeries. In addition, we find that, in line with previous research, the inclusion of synthetic forgeries in the training also enables the detection of AI-generated forgeries, especially if created using a similar generator.
Art Authentication with Vision Transformers
Jul 10, 2023In recent years, Transformers, initially developed for language, have been successfully applied to visual tasks. Vision Transformers have been shown to push the state-of-the-art in a wide range of tasks, including image classification, object detection, and semantic segmentation. While ample research has shown promising results in art attribution and art authentication tasks using Convolutional Neural Networks, this paper examines if the superiority of Vision Transformers extends to art authentication, improving, thus, the reliability of computer-based authentication of artworks. Using a carefully compiled dataset of authentic paintings by Vincent van Gogh and two contrast datasets, we compare the art authentication performances of Swin Transformers with those of EfficientNet. Using a standard contrast set containing imitations and proxies (works by painters with styles closely related to van Gogh), we find that EfficientNet achieves the best performance overall. With a contrast set that only consists of imitations, we find the Swin Transformer to be superior to EfficientNet by achieving an authentication accuracy of over 85%. These results lead us to conclude that Vision Transformers represent a strong and promising contender in art authentication, particularly in enhancing the computer-based ability to detect artistic imitations.
A one-armed CNN for exoplanet detection from light curves
May 12, 2021
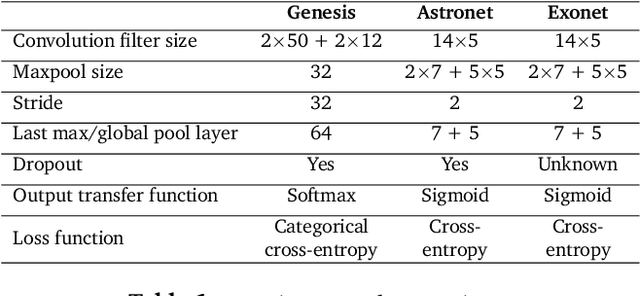
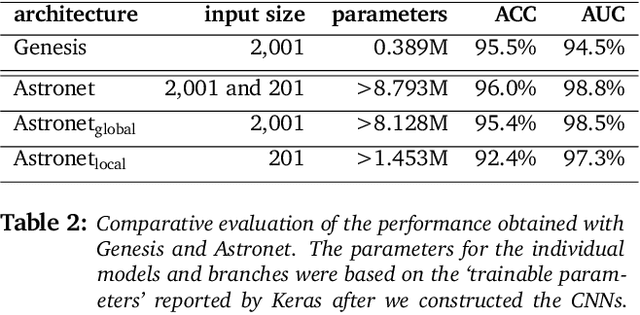

We propose Genesis, a one-armed simplified Convolutional Neural Network (CNN)for exoplanet detection, and compare it to the more complex, two-armed CNN called Astronet. Furthermore, we examine how Monte Carlo cross-validation affects the estimation of the exoplanet detection performance. Finally, we increase the input resolution twofold to assess its effect on performance. The experiments reveal that (i)the reduced complexity of Genesis, i.e., a more than 95% reduction in the number of free parameters, incurs a small performance cost of about 0.5% compared to Astronet, (ii) Monte Carlo cross-validation provides a more realistic performance estimate that is almost 0.7% below the original estimate, and (iii) the twofold increase in input resolution decreases the average performance by about 0.5%. We conclude by arguing that further exploration of shallower CNN architectures may be beneficial in order to improve the generalizability of CNN-based exoplanet detection across surveys.
Reducing Artificial Neural Network Complexity: A Case Study on Exoplanet Detection
Feb 27, 2019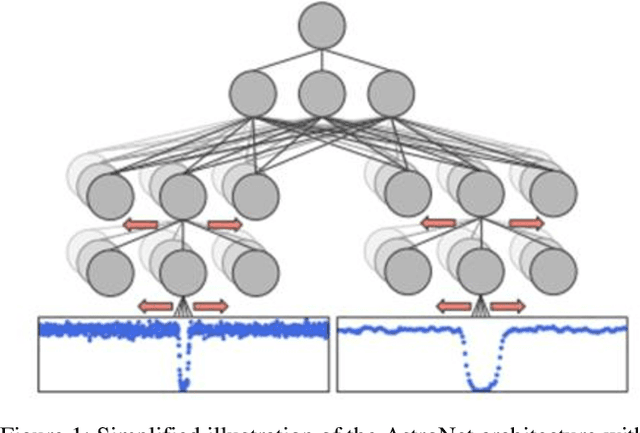
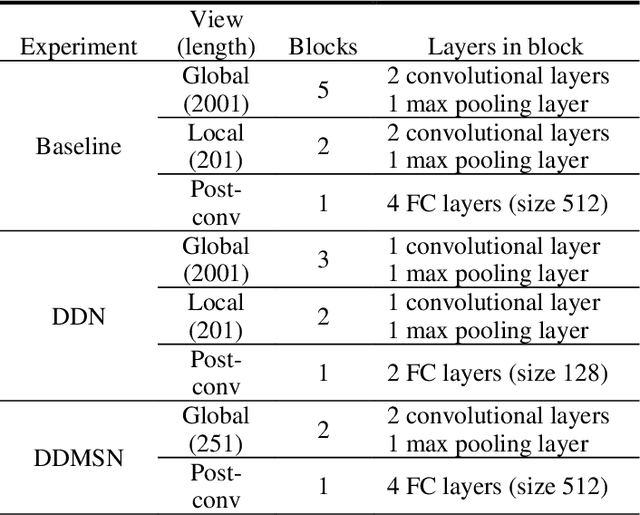
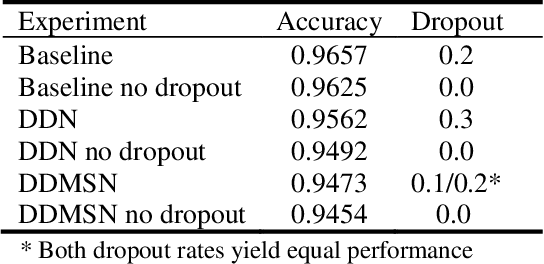

Despite their successes in the field of self-learning AI, Convolutional Neural Networks (CNNs) suffer from having too many trainable parameters, impacting computational performance. Several approaches have been proposed to reduce the number of parameters in the visual domain, the Inception architecture [Szegedy et al., 2016] being a prominent example. This raises the question whether the number of trainable parameters in CNNs can also be reduced for 1D inputs, such as time-series data, without incurring a substantial loss in classification performance. We propose and examine two methods for complexity reduction in AstroNet [Shallue & Vanderburg, 2018], a CNN for automatic classification of time-varying brightness data of stars to detect exoplanets. The first method makes only a tactical reduction of layers in AstroNet while the second method also modifies the original input data by means of a Gaussian pyramid. We conducted our experiments with various degrees of dropout regularization. Our results show only a non-substantial loss in accuracy compared to the original AstroNet, while reducing training time up to 85 percent. These results show potential for similar reductions in other CNN applications while largely retaining accuracy.
Light-weight pixel context encoders for image inpainting
Jan 17, 2018
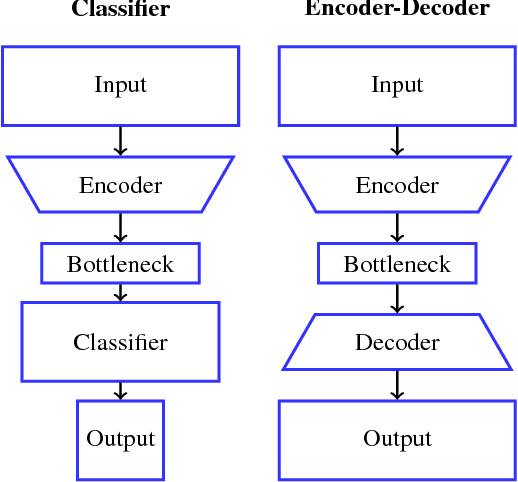

In this work we propose Pixel Content Encoders (PCE), a light-weight image inpainting model, capable of generating novel con-tent for large missing regions in images. Unlike previously presented convolutional neural network based models, our PCE model has an order of magnitude fewer trainable parameters. Moreover, by incorporating dilated convolutions we are able to preserve fine grained spatial information, achieving state-of-the-art performance on benchmark datasets of natural images and paintings. Besides image inpainting, we show that without changing the architecture, PCE can be used for image extrapolation, generating novel content beyond existing image boundaries.
Learning scale-variant and scale-invariant features for deep image classification
May 13, 2016

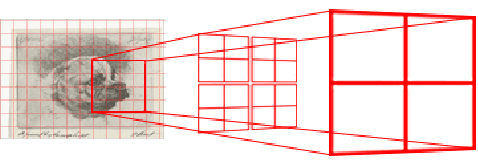

Convolutional Neural Networks (CNNs) require large image corpora to be trained on classification tasks. The variation in image resolutions, sizes of objects and patterns depicted, and image scales, hampers CNN training and performance, because the task-relevant information varies over spatial scales. Previous work attempting to deal with such scale variations focused on encouraging scale-invariant CNN representations. However, scale-invariant representations are incomplete representations of images, because images contain scale-variant information as well. This paper addresses the combined development of scale-invariant and scale-variant representations. We propose a multi- scale CNN method to encourage the recognition of both types of features and evaluate it on a challenging image classification task involving task-relevant characteristics at multiple scales. The results show that our multi-scale CNN outperforms single-scale CNN. This leads to the conclusion that encouraging the combined development of a scale-invariant and scale-variant representation in CNNs is beneficial to image recognition performance.
Circle-based Eye Center Localization (CECL)
Aug 21, 2015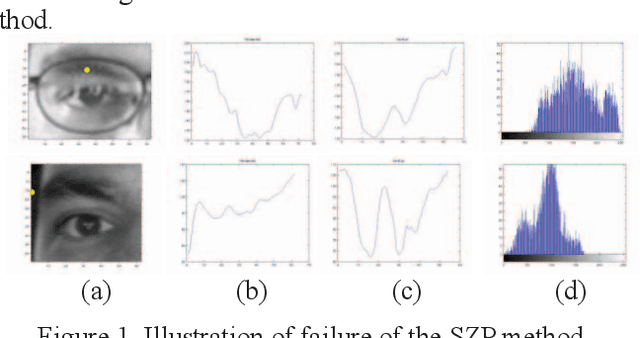

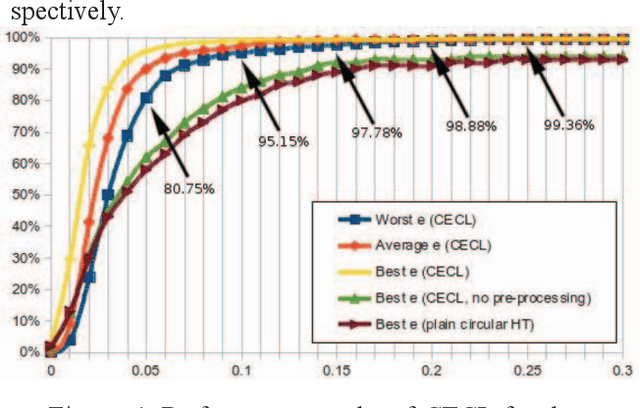

We propose an improved eye center localization method based on the Hough transform, called Circle-based Eye Center Localization (CECL) that is simple, robust, and achieves accuracy on a par with typically more complex state-of-the-art methods. The CECL method relies on color and shape cues that distinguish the iris from other facial structures. The accuracy of the CECL method is demonstrated through a comparison with 15 state-of-the-art eye center localization methods against five error thresholds, as reported in the literature. The CECL method achieved an accuracy of 80.8% to 99.4% and ranked first for 2 of the 5 thresholds. It is concluded that the CECL method offers an attractive alternative to existing methods for automatic eye center localization.
Exploring the influence of scale on artist attribution
Jun 19, 2015


Previous work has shown that the artist of an artwork can be identified by use of computational methods that analyse digital images. However, the digitised artworks are often investigated at a coarse scale discarding many of the important details that may define an artist's style. In recent years high resolution images of artworks have become available, which, combined with increased processing power and new computational techniques, allow us to analyse digital images of artworks at a very fine scale. In this work we train and evaluate a Convolutional Neural Network (CNN) on the task of artist attribution using artwork images of varying resolutions. To this end, we combine two existing methods to enable the application of high resolution images to CNNs. By comparing the attribution performances obtained at different scales, we find that in most cases finer scales are beneficial to the attribution performance, whereas for a minority of the artists, coarser scales appear to be preferable. We conclude that artist attribution would benefit from a multi-scale CNN approach which vastly expands the possibilities for computational art forensics.