 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNearly Minimax Discrete Distribution Estimation in Kullback-Leibler Divergence with High Probability
Jul 23, 2025We consider the problem of estimating a discrete distribution $p$ with support of size $K$ and provide both upper and lower bounds with high probability in KL divergence. We prove that in the worst case, for any estimator $\widehat{p}$, with probability at least $\delta$, $\text{KL}(p \| \widehat{p}) \geq C\max\{K,\ln(K)\ln(1/\delta) \}/n $, where $n$ is the sample size and $C > 0$ is a constant. We introduce a computationally efficient estimator $p^{\text{OTB}}$, based on Online to Batch conversion and suffix averaging, and show that with probability at least $1 - \delta$ $\text{KL}(p \| \widehat{p}) \leq C(K\log(\log(K)) + \ln(K)\ln(1/\delta)) /n$. Furthermore, we also show that with sufficiently many observations relative to $\log(1/\delta)$, the maximum likelihood estimator $\bar{p}$ guarantees that with probability at least $1-\delta$ $$ 1/6 \chi^2(\bar{p}\|p) \leq 1/4 \chi^2(p\|\bar{p}) \leq \text{KL}(p|\bar{p}) \leq C(K + \log(1/\delta))/n\,, $$ where $\chi^2$ denotes the $\chi^2$-divergence.
Sample-efficient Learning of Concepts with Theoretical Guarantees: from Data to Concepts without Interventions
Feb 10, 2025Machine learning is a vital part of many real-world systems, but several concerns remain about the lack of interpretability, explainability and robustness of black-box AI systems. Concept-based models (CBM) address some of these challenges by learning interpretable concepts from high-dimensional data, e.g. images, which are used to predict labels. An important issue in CBMs is concept leakage, i.e., spurious information in the learned concepts, which effectively leads to learning "wrong" concepts. Current mitigating strategies are heuristic, have strong assumptions, e.g., they assume that the concepts are statistically independent of each other, or require substantial human interaction in terms of both interventions and labels provided by annotators. In this paper, we describe a framework that provides theoretical guarantees on the correctness of the learned concepts and on the number of required labels, without requiring any interventions. Our framework leverages causal representation learning (CRL) to learn high-level causal variables from low-level data, and learns to align these variables with interpretable concepts. We propose a linear and a non-parametric estimator for this mapping, providing a finite-sample high probability result in the linear case and an asymptotic consistency result for the non-parametric estimator. We implement our framework with state-of-the-art CRL methods, and show its efficacy in learning the correct concepts in synthetic and image benchmarks.
An Online Feasible Point Method for Benign Generalized Nash Equilibrium Problems
Oct 03, 2024


We consider a repeatedly played generalized Nash equilibrium game. This induces a multi-agent online learning problem with joint constraints. An important challenge in this setting is that the feasible set for each agent depends on the simultaneous moves of the other agents and, therefore, varies over time. As a consequence, the agents face time-varying constraints, which are not adversarial but rather endogenous to the system. Prior work in this setting focused on convergence to a feasible solution in the limit via integrating the constraints in the objective as a penalty function. However, no existing work can guarantee that the constraints are satisfied for all iterations while simultaneously guaranteeing convergence to a generalized Nash equilibrium. This is a problem of fundamental theoretical interest and practical relevance. In this work, we introduce a new online feasible point method. Under the assumption that limited communication between the agents is allowed, this method guarantees feasibility. We identify the class of benign generalized Nash equilibrium problems, for which the convergence of our method to the equilibrium is guaranteed. We set this class of benign generalized Nash equilibrium games in context with existing definitions and illustrate our method with examples.
Generalization Guarantees via Algorithm-dependent Rademacher Complexity
Jul 04, 2023Algorithm- and data-dependent generalization bounds are required to explain the generalization behavior of modern machine learning algorithms. In this context, there exists information theoretic generalization bounds that involve (various forms of) mutual information, as well as bounds based on hypothesis set stability. We propose a conceptually related, but technically distinct complexity measure to control generalization error, which is the empirical Rademacher complexity of an algorithm- and data-dependent hypothesis class. Combining standard properties of Rademacher complexity with the convenient structure of this class, we are able to (i) obtain novel bounds based on the finite fractal dimension, which (a) extend previous fractal dimension-type bounds from continuous to finite hypothesis classes, and (b) avoid a mutual information term that was required in prior work; (ii) we greatly simplify the proof of a recent dimension-independent generalization bound for stochastic gradient descent; and (iii) we easily recover results for VC classes and compression schemes, similar to approaches based on conditional mutual information.
The Risks of Recourse in Binary Classification
Jun 01, 2023Algorithmic recourse provides explanations that help users overturn an unfavorable decision by a machine learning system. But so far very little attention has been paid to whether providing recourse is beneficial or not. We introduce an abstract learning-theoretic framework that compares the risks (i.e. expected losses) for classification with and without algorithmic recourse. This allows us to answer the question of when providing recourse is beneficial or harmful at the population level. Surprisingly, we find that there are many plausible scenarios in which providing recourse turns out to be harmful, because it pushes users to regions of higher class uncertainty and therefore leads to more mistakes. We further study whether the party deploying the classifier has an incentive to strategize in anticipation of having to provide recourse, and we find that sometimes they do, to the detriment of their users. Providing algorithmic recourse may therefore also be harmful at the systemic level. We confirm our theoretical findings in experiments on simulated and real-world data. All in all, we conclude that the current concept of algorithmic recourse is not reliably beneficial, and therefore requires rethinking.
First- and Second-Order Bounds for Adversarial Linear Contextual Bandits
May 01, 2023We consider the adversarial linear contextual bandit setting, which allows for the loss functions associated with each of $K$ arms to change over time without restriction. Assuming the $d$-dimensional contexts are drawn from a fixed known distribution, the worst-case expected regret over the course of $T$ rounds is known to scale as $\tilde O(\sqrt{Kd T})$. Under the additional assumption that the density of the contexts is log-concave, we obtain a second-order bound of order $\tilde O(K\sqrt{d V_T})$ in terms of the cumulative second moment of the learner's losses $V_T$, and a closely related first-order bound of order $\tilde O(K\sqrt{d L_T^*})$ in terms of the cumulative loss of the best policy $L_T^*$. Since $V_T$ or $L_T^*$ may be significantly smaller than $T$, these improve over the worst-case regret whenever the environment is relatively benign. Our results are obtained using a truncated version of the continuous exponential weights algorithm over the probability simplex, which we analyse by exploiting a novel connection to the linear bandit setting without contexts.
Towards Characterizing the First-order Query Complexity of Learning (Approximate) Nash Equilibria in Zero-sum Matrix Games
Apr 25, 2023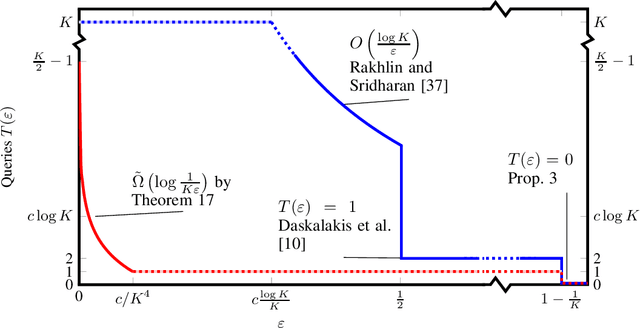
In the first-order query model for zero-sum $K\times K$ matrix games, playersobserve the expected pay-offs for all their possible actions under therandomized action played by their opponent. This is a classical model,which has received renewed interest after the discoveryby Rakhlin and Sridharan that $\epsilon$-approximate Nash equilibria can be computedefficiently from $O(\ln K / \epsilon) $ instead of $O( \ln K / \epsilon^2)$ queries.Surprisingly, the optimal number of such queries, as a function of both$\epsilon$ and $K$, is not known.We make progress on this question on two fronts. First, we fully characterise the query complexity of learning exact equilibria ($\epsilon=0$), by showing that they require a number of queries that is linearin $K$, which means that it is essentially as hard as querying the wholematrix, which can also be done with $K$ queries. Second, for $\epsilon > 0$, the currentquery complexity upper bound stands at $O(\min(\ln(K) / \epsilon , K))$. We argue that, unfortunately, obtaining matchinglower bound is not possible with existing techniques: we prove that nolower bound can be derived by constructing hard matrices whose entriestake values in a known countable set, because such matrices can be fullyidentified by a single query. This rules out, for instance, reducing toa submodular optimization problem over the hypercube by encoding itas a binary matrix. We then introduce a new technique for lower bounds,which allows us to obtain lower bounds of order$\tilde\Omega(\log(1 / (K\epsilon)))$ for any $\epsilon \leq1 / cK^4$, where $c$ is a constant independent of $K$. We furtherdiscuss possible future directions to improve on our techniques in orderto close the gap with the upper bounds.
Accelerated Rates between Stochastic and Adversarial Online Convex Optimization
Mar 06, 2023Stochastic and adversarial data are two widely studied settings in online learning. But many optimization tasks are neither i.i.d. nor fully adversarial, which makes it of fundamental interest to get a better theoretical understanding of the world between these extremes. In this work we establish novel regret bounds for online convex optimization in a setting that interpolates between stochastic i.i.d. and fully adversarial losses. By exploiting smoothness of the expected losses, these bounds replace a dependence on the maximum gradient length by the variance of the gradients, which was previously known only for linear losses. In addition, they weaken the i.i.d. assumption by allowing, for example, adversarially poisoned rounds, which were previously considered in the related expert and bandit settings. In the fully i.i.d. case, our regret bounds match the rates one would expect from results in stochastic acceleration, and we also recover the optimal stochastically accelerated rates via online-to-batch conversion. In the fully adversarial case our bounds gracefully deteriorate to match the minimax regret. We further provide lower bounds showing that our regret upper bounds are tight for all intermediate regimes in terms of the stochastic variance and the adversarial variation of the loss gradients.
Adaptive Selective Sampling for Online Prediction with Experts
Feb 16, 2023


We consider online prediction of a binary sequence with expert advice. For this setting, we devise label-efficient forecasting algorithms, which use a selective sampling scheme that enables collecting much fewer labels than standard procedures, while still retaining optimal worst-case regret guarantees. These algorithms are based on exponentially weighted forecasters, suitable for settings with and without a perfect expert. For a scenario where one expert is strictly better than the others in expectation, we show that the label complexity of the label-efficient forecaster scales roughly as the square root of the number of rounds. Finally, we present numerical experiments empirically showing that the normalized regret of the label-efficient forecaster can asymptotically match known minimax rates for pool-based active learning, suggesting it can optimally adapt to benign settings.
Modifying Squint for Prediction with Expert Advice in a Changing Environment
Sep 14, 2022We provide a new method for online learning, specifically prediction with expert advice, in a changing environment. In a non-changing environment the Squint algorithm has been designed to always function at least as well as other known algorithms and in specific cases it functions much better. However, when using a conventional black-box algorithm to make Squint suitable for a changing environment, it loses its beneficial properties. Hence, we provide a new algorithm, Squint-CE, which is suitable for a changing environment and preserves the properties of Squint.