 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization and Informativeness of Conformal Prediction
Jan 22, 2024The safe integration of machine learning modules in decision-making processes hinges on their ability to quantify uncertainty. A popular technique to achieve this goal is conformal prediction (CP), which transforms an arbitrary base predictor into a set predictor with coverage guarantees. While CP certifies the predicted set to contain the target quantity with a user-defined tolerance, it does not provide control over the average size of the predicted sets, i.e., over the informativeness of the prediction. In this work, a theoretical connection is established between the generalization properties of the base predictor and the informativeness of the resulting CP prediction sets. To this end, an upper bound is derived on the expected size of the CP set predictor that builds on generalization error bounds for the base predictor. The derived upper bound provides insights into the dependence of the average size of the CP set predictor on the amount of calibration data, the target reliability, and the generalization performance of the base predictor. The theoretical insights are validated using simple numerical regression and classification tasks.
Comparing Comparators in Generalization Bounds
Oct 16, 2023We derive generic information-theoretic and PAC-Bayesian generalization bounds involving an arbitrary convex comparator function, which measures the discrepancy between the training and population loss. The bounds hold under the assumption that the cumulant-generating function (CGF) of the comparator is upper-bounded by the corresponding CGF within a family of bounding distributions. We show that the tightest possible bound is obtained with the comparator being the convex conjugate of the CGF of the bounding distribution, also known as the Cram\'er function. This conclusion applies more broadly to generalization bounds with a similar structure. This confirms the near-optimality of known bounds for bounded and sub-Gaussian losses and leads to novel bounds under other bounding distributions.
Generalization Bounds: Perspectives from Information Theory and PAC-Bayes
Sep 08, 2023A fundamental question in theoretical machine learning is generalization. Over the past decades, the PAC-Bayesian approach has been established as a flexible framework to address the generalization capabilities of machine learning algorithms, and design new ones. Recently, it has garnered increased interest due to its potential applicability for a variety of learning algorithms, including deep neural networks. In parallel, an information-theoretic view of generalization has developed, wherein the relation between generalization and various information measures has been established. This framework is intimately connected to the PAC-Bayesian approach, and a number of results have been independently discovered in both strands. In this monograph, we highlight this strong connection and present a unified treatment of generalization. We present techniques and results that the two perspectives have in common, and discuss the approaches and interpretations that differ. In particular, we demonstrate how many proofs in the area share a modular structure, through which the underlying ideas can be intuited. We pay special attention to the conditional mutual information (CMI) framework; analytical studies of the information complexity of learning algorithms; and the application of the proposed methods to deep learning. This monograph is intended to provide a comprehensive introduction to information-theoretic generalization bounds and their connection to PAC-Bayes, serving as a foundation from which the most recent developments are accessible. It is aimed broadly towards researchers with an interest in generalization and theoretical machine learning.
Adaptive Selective Sampling for Online Prediction with Experts
Feb 16, 2023


We consider online prediction of a binary sequence with expert advice. For this setting, we devise label-efficient forecasting algorithms, which use a selective sampling scheme that enables collecting much fewer labels than standard procedures, while still retaining optimal worst-case regret guarantees. These algorithms are based on exponentially weighted forecasters, suitable for settings with and without a perfect expert. For a scenario where one expert is strictly better than the others in expectation, we show that the label complexity of the label-efficient forecaster scales roughly as the square root of the number of rounds. Finally, we present numerical experiments empirically showing that the normalized regret of the label-efficient forecaster can asymptotically match known minimax rates for pool-based active learning, suggesting it can optimally adapt to benign settings.
Evaluated CMI Bounds for Meta Learning: Tightness and Expressiveness
Oct 12, 2022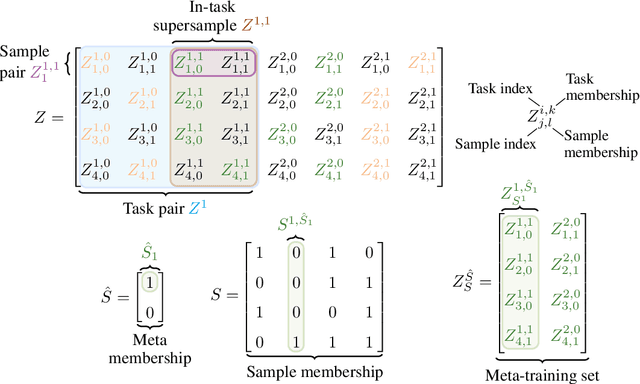
Recent work has established that the conditional mutual information (CMI) framework of Steinke and Zakynthinou (2020) is expressive enough to capture generalization guarantees in terms of algorithmic stability, VC dimension, and related complexity measures for conventional learning (Harutyunyan et al., 2021, Haghifam et al., 2021). Hence, it provides a unified method for establishing generalization bounds. In meta learning, there has so far been a divide between information-theoretic results and results from classical learning theory. In this work, we take a first step toward bridging this divide. Specifically, we present novel generalization bounds for meta learning in terms of the evaluated CMI (e-CMI). To demonstrate the expressiveness of the e-CMI framework, we apply our bounds to a representation learning setting, with $n$ samples from $\hat n$ tasks parameterized by functions of the form $f_i \circ h$. Here, each $f_i \in \mathcal F$ is a task-specific function, and $h \in \mathcal H$ is the shared representation. For this setup, we show that the e-CMI framework yields a bound that scales as $\sqrt{ \mathcal C(\mathcal H)/(n\hat n) + \mathcal C(\mathcal F)/n} $, where $\mathcal C(\cdot)$ denotes a complexity measure of the hypothesis class. This scaling behavior coincides with the one reported in Tripuraneni et al. (2020) using Gaussian complexity.
A New Family of Generalization Bounds Using Samplewise Evaluated CMI
Oct 12, 2022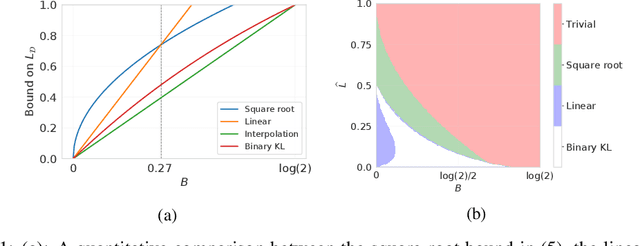

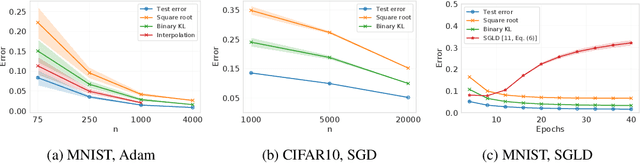
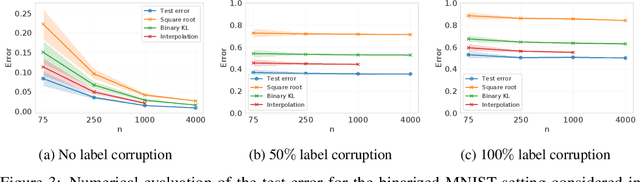
We present a new family of information-theoretic generalization bounds, in which the training loss and the population loss are compared through a jointly convex function. This function is upper-bounded in terms of the disintegrated, samplewise, evaluated conditional mutual information (CMI), an information measure that depends on the losses incurred by the selected hypothesis, rather than on the hypothesis itself, as is common in probably approximately correct (PAC)-Bayesian results. We demonstrate the generality of this framework by recovering and extending previously known information-theoretic bounds. Furthermore, using the evaluated CMI, we derive a samplewise, average version of Seeger's PAC-Bayesian bound, where the convex function is the binary KL divergence. In some scenarios, this novel bound results in a tighter characterization of the population loss of deep neural networks than previous bounds. Finally, we derive high-probability versions of some of these average bounds. We demonstrate the unifying nature of the evaluated CMI bounds by using them to recover average and high-probability generalization bounds for multiclass classification with finite Natarajan dimension.
Nonvacuous Loss Bounds with Fast Rates for Neural Networks via Conditional Information Measures
Oct 22, 2020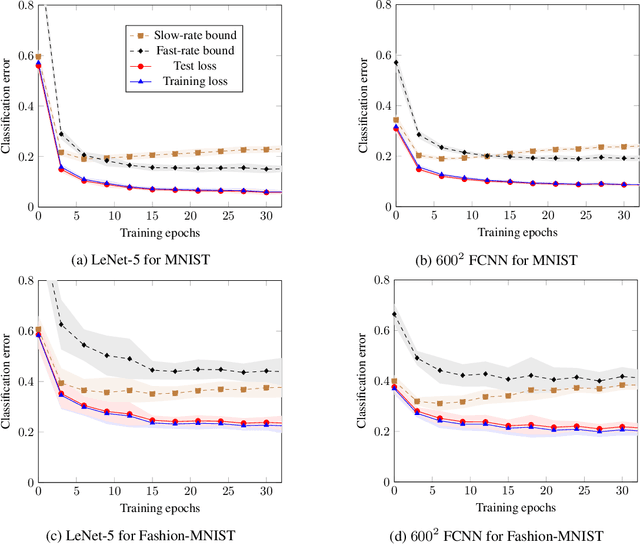

We present a framework to derive bounds on the test loss of randomized learning algorithms for the case of bounded loss functions. This framework leads to bounds that depend on the conditional information density between the the output hypothesis and the choice of the training set, given a larger set of data samples from which the training set is formed. Furthermore, the bounds pertain to the average test loss as well as to its tail probability, both for the PAC-Bayesian and the single-draw settings. If the conditional information density is bounded uniformly in the size $n$ of the training set, our bounds decay as $1/n$, which is referred to as a fast rate. This is in contrast with the tail bounds involving conditional information measures available in the literature, which have a less benign $1/\sqrt{n}$ dependence. We demonstrate the usefulness of our tail bounds by showing that they lead to estimates of the test loss achievable with several neural network architectures trained on MNIST and Fashion-MNIST that match the state-of-the-art bounds available in the literature.
Generalization Bounds via Information Density and Conditional Information Density
May 16, 2020We present a general approach, based on an exponential inequality, to derive bounds on the generalization error of randomized learning algorithms. Using this approach, we provide bounds on the average generalization error as well as bounds on its tail probability, for both the PAC-Bayesian and single-draw scenarios. Specifically, for the case of subgaussian loss functions, we obtain novel bounds that depend on the information density between the training data and the output hypothesis. When suitably weakened, these bounds recover many of the information-theoretic available bounds in the literature. We also extend the proposed exponential-inequality approach to the setting recently introduced by Steinke and Zakynthinou (2020), where the learning algorithm depends on a randomly selected subset of the available training data. For this setup, we present bounds for bounded loss functions in terms of the conditional information density between the output hypothesis and the random variable determining the subset choice, given all training data. Through our approach, we recover the average generalization bound presented by Steinke and Zakynthinou (2020) and extend it to the PAC-Bayesian and single-draw scenarios. For the single-draw scenario, we also obtain novel bounds in terms of the conditional $\alpha$-mutual information and the conditional maximal leakage.
Generalization Error Bounds via $m$th Central Moments of the Information Density
Apr 20, 2020We present a general approach to deriving bounds on the generalization error of randomized learning algorithms. Our approach can be used to obtain bounds on the average generalization error as well as bounds on its tail probabilities, both for the case in which a new hypothesis is randomly generated every time the algorithm is used - as often assumed in the probably approximately correct (PAC)-Bayesian literature - and in the single-draw case, where the hypothesis is extracted only once. For this last scenario, we present a novel bound that is explicit in the central moments of the information density. The bound reveals that the higher the order of the information density moment that can be controlled, the milder the dependence of the generalization bound on the desired confidence level. Furthermore, we use tools from binary hypothesis testing to derive a second bound, which is explicit in the tail of the information density. This bound confirms that a fast decay of the tail of the information density yields a more favorable dependence of the generalization bound on the confidence level.