 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonvacuous Loss Bounds with Fast Rates for Neural Networks via Conditional Information Measures
Paper and Code
Oct 22, 2020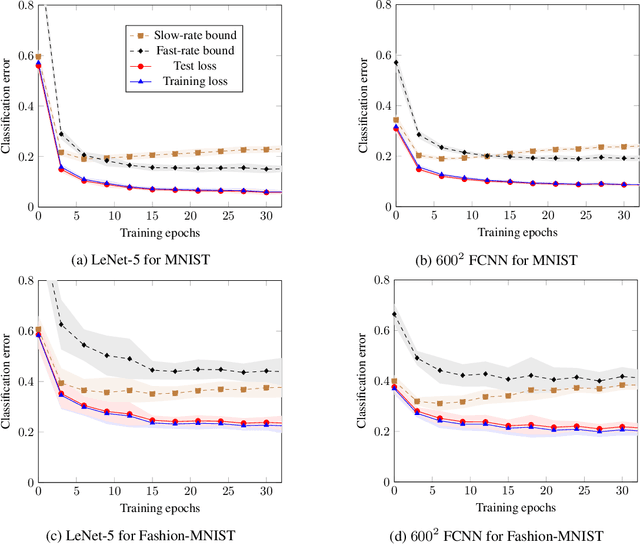

We present a framework to derive bounds on the test loss of randomized learning algorithms for the case of bounded loss functions. This framework leads to bounds that depend on the conditional information density between the the output hypothesis and the choice of the training set, given a larger set of data samples from which the training set is formed. Furthermore, the bounds pertain to the average test loss as well as to its tail probability, both for the PAC-Bayesian and the single-draw settings. If the conditional information density is bounded uniformly in the size $n$ of the training set, our bounds decay as $1/n$, which is referred to as a fast rate. This is in contrast with the tail bounds involving conditional information measures available in the literature, which have a less benign $1/\sqrt{n}$ dependence. We demonstrate the usefulness of our tail bounds by showing that they lead to estimates of the test loss achievable with several neural network architectures trained on MNIST and Fashion-MNIST that match the state-of-the-art bounds available in the literature.