 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniRetrieval: Unified Retrieval across Heterogeneous Knowledge Sources
May 28, 2026Real-world information needs require access to structurally diverse knowledge sources, from unstructured text and relational tables to knowledge graphs and property graphs. Existing retrievers, however, operate over one source at a time under a fixed query language, leaving the broader landscape of available knowledge fragmented behind incompatible interfaces. A natural attempt at unification would collapse these sources into a shared space, but this erases the structural affordances (such as schemas, ontologies, compositional operators) that give each source its expressive power. Effective retrieval over diverse knowledge, therefore, requires not homogenization but an overarching layer that meets each source on its own terms. To achieve this, we present OmniRetrieval, a framework that takes any natural-language query, identifies appropriate knowledge sources, and dispatches source-native queries to their native execution engines. Across an extensive benchmark spanning 13 datasets and 309 distinct knowledge bases over text, relational, and graph-structured sources, OmniRetrieval exceeds single-source baselines, demonstrating that it can serve as a general-purpose interface to the heterogeneous sources while preserving the structural distinctions that make each source valuable.
It Takes Two: Complementary Self-Distillation for Contextual Integrity in LLMs
May 18, 2026Contextual Integrity (CI) defines privacy not merely as keeping information hidden, but as governing information flows according to the norms of a given context. As large language models are increasingly deployed as personal agents handling sensitive workflows, adhering to CI becomes critical. However, even frontier models remain unreliable in making disclosure decisions, and existing mitigation strategies often degrade underlying task performance. To overcome this privacy-utility trade-off, we propose SELFCI, a complementary self-distillation framework that decouples information suppression from task resolution. SELFCI jointly optimizes two independent reverse KL divergences over distinct teacher distributions derived from feedback: one encourages preserving task-relevant information for utility, while the other enforces minimal and appropriate disclosure. This complementary formulation induces a Product-of-Experts (PoE) target, aligning the policy with the intersection of capability and privacy requirements. Empirical evaluations demonstrate that SELFCI, without relying on costly external supervision, consistently outperforms competitive baselines such as online reinforcement learning algorithms (e.g., GRPO). These trends further extend to out-of-domain settings involving agentic workflows and accumulated private context, suggesting that SELFCI provides a practical path toward CI alignment.
Adaptive Selection of LoRA Components in Privacy-Preserving Federated Learning
May 07, 2026Differentially private federated fine-tuning of large models with LoRA suffers from aggregation error caused by LoRA's multiplicative structure, which is further amplified by DP noise and degrades both stability and accuracy. Existing remedies apply a single update mode uniformly across all layers and all communication rounds (or alternate them on a fixed schedule), ignoring both the structural asymmetry between the two LoRA factors and the round-wise dynamics of training. We propose AS-LoRA, an adaptive framework defined by three axes (i) layer-wise freedom, in which each layer independently selects its active component, (ii) round-wise adaptivity, in which the selection updates over communication rounds, and (iii) a curvature-aware score derived from a second-order approximation of the loss. Theoretically, AS-LoRA eliminates the reconstruction-error floor of layer-tied schedules, accelerates convergence, implicitly biases solutions toward flatter minima, and incurs no additional privacy cost. Across GLUE, SQuAD, CIFAR-100, and Tiny-ImageNet under strict DP budgets and non-IID partitions, AS-LoRA improves over the federated LoRA baselines by up to $+7.5$ pp on GLUE and $+12.5$ pp on MNLI-mm for example, while matching or exceeding SVD-based aggregation methods at $33\text{--}180 \times$ lower aggregation cost and with negligible communication overhead. Code for the proposed method is available at https://anonymous.4open.science/r/as_lora-F75F/.
T-MAP: Red-Teaming LLM Agents with Trajectory-aware Evolutionary Search
Mar 21, 2026While prior red-teaming efforts have focused on eliciting harmful text outputs from large language models (LLMs), such approaches fail to capture agent-specific vulnerabilities that emerge through multi-step tool execution, particularly in rapidly growing ecosystems such as the Model Context Protocol (MCP). To address this gap, we propose a trajectory-aware evolutionary search method, T-MAP, which leverages execution trajectories to guide the discovery of adversarial prompts. Our approach enables the automatic generation of attacks that not only bypass safety guardrails but also reliably realize harmful objectives through actual tool interactions. Empirical evaluations across diverse MCP environments demonstrate that T-MAP substantially outperforms baselines in attack realization rate (ARR) and remains effective against frontier models, including GPT-5.2, Gemini-3-Pro, Qwen3.5, and GLM-5, thereby revealing previously underexplored vulnerabilities in autonomous LLM agents.
THINKSAFE: Self-Generated Safety Alignment for Reasoning Models
Jan 30, 2026Large reasoning models (LRMs) achieve remarkable performance by leveraging reinforcement learning (RL) on reasoning tasks to generate long chain-of-thought (CoT) reasoning. However, this over-optimization often prioritizes compliance, making models vulnerable to harmful prompts. To mitigate this safety degradation, recent approaches rely on external teacher distillation, yet this introduces a distributional discrepancy that degrades native reasoning. We propose ThinkSafe, a self-generated alignment framework that restores safety alignment without external teachers. Our key insight is that while compliance suppresses safety mechanisms, models often retain latent knowledge to identify harm. ThinkSafe unlocks this via lightweight refusal steering, guiding the model to generate in-distribution safety reasoning traces. Fine-tuning on these self-generated responses effectively realigns the model while minimizing distribution shift. Experiments on DeepSeek-R1-Distill and Qwen3 show ThinkSafe significantly improves safety while preserving reasoning proficiency. Notably, it achieves superior safety and comparable reasoning to GRPO, with significantly reduced computational cost. Code, models, and datasets are available at https://github.com/seanie12/ThinkSafe.git.
Reliable LLM-Based Edge-Cloud-Expert Cascades for Telecom Knowledge Systems
Dec 23, 2025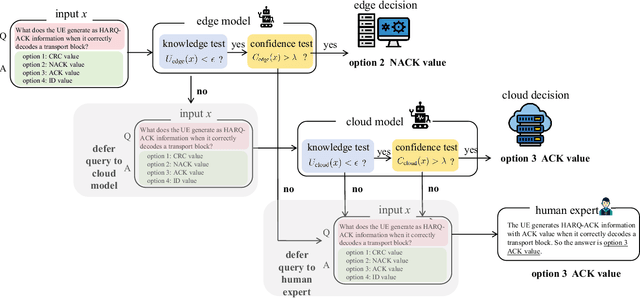
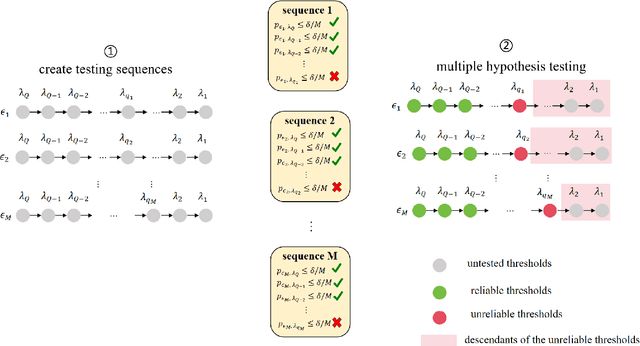
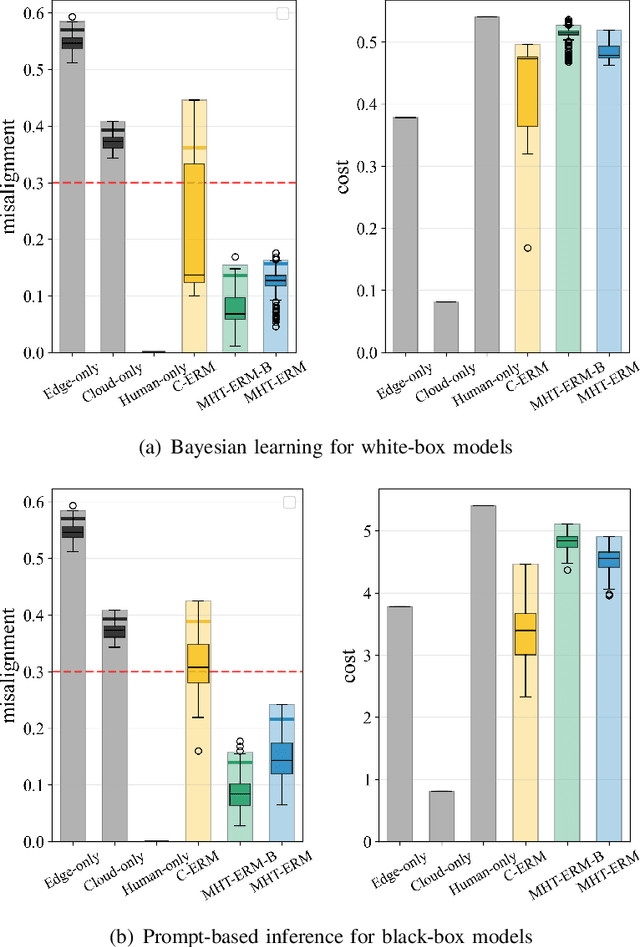
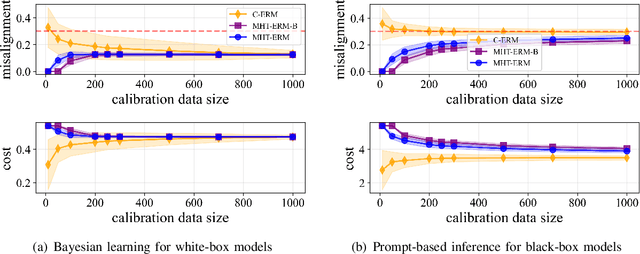
Large language models (LLMs) are emerging as key enablers of automation in domains such as telecommunications, assisting with tasks including troubleshooting, standards interpretation, and network optimization. However, their deployment in practice must balance inference cost, latency, and reliability. In this work, we study an edge-cloud-expert cascaded LLM-based knowledge system that supports decision-making through a question-and-answer pipeline. In it, an efficient edge model handles routine queries, a more capable cloud model addresses complex cases, and human experts are involved only when necessary. We define a misalignment-cost constrained optimization problem, aiming to minimize average processing cost, while guaranteeing alignment of automated answers with expert judgments. We propose a statistically rigorous threshold selection method based on multiple hypothesis testing (MHT) for a query processing mechanism based on knowledge and confidence tests. The approach provides finite-sample guarantees on misalignment risk. Experiments on the TeleQnA dataset -- a telecom-specific benchmark -- demonstrate that the proposed method achieves superior cost-efficiency compared to conventional cascaded baselines, while ensuring reliability at prescribed confidence levels.
On-Device Fine-Tuning via Backprop-Free Zeroth-Order Optimization
Nov 14, 2025On-device fine-tuning is a critical capability for edge AI systems, which must support adaptation to different agentic tasks under stringent memory constraints. Conventional backpropagation (BP)-based training requires storing layer activations and optimizer states, a demand that can be only partially alleviated through checkpointing. In edge deployments in which the model weights must reside entirely in device memory, this overhead severely limits the maximum model size that can be deployed. Memory-efficient zeroth-order optimization (MeZO) alleviates this bottleneck by estimating gradients using forward evaluations alone, eliminating the need for storing intermediate activations or optimizer states. This enables significantly larger models to fit within on-chip memory, albeit at the cost of potentially longer fine-tuning wall-clock time. This paper first provides a theoretical estimate of the relative model sizes that can be accommodated under BP and MeZO training. We then numerically validate the analysis, demonstrating that MeZO exhibits accuracy advantages under on-device memory constraints, provided sufficient wall-clock time is available for fine-tuning.
Rethinking Reward Models for Multi-Domain Test-Time Scaling
Oct 02, 2025The reliability of large language models (LLMs) during test-time scaling is often assessed with \emph{external verifiers} or \emph{reward models} that distinguish correct reasoning from flawed logic. Prior work generally assumes that process reward models (PRMs), which score every intermediate reasoning step, outperform outcome reward models (ORMs) that assess only the final answer. This view is based mainly on evidence from narrow, math-adjacent domains. We present the first unified evaluation of four reward model variants, discriminative ORM and PRM (\DisORM, \DisPRM) and generative ORM and PRM (\GenORM, \GenPRM), across 14 diverse domains. Contrary to conventional wisdom, we find that (i) \DisORM performs on par with \DisPRM, (ii) \GenPRM is not competitive, and (iii) overall, \GenORM is the most robust, yielding significant and consistent gains across every tested domain. We attribute this to PRM-style stepwise scoring, which inherits label noise from LLM auto-labeling and has difficulty evaluating long reasoning trajectories, including those involving self-correcting reasoning. Our theoretical analysis shows that step-wise aggregation compounds errors as reasoning length grows, and our empirical observations confirm this effect. These findings challenge the prevailing assumption that fine-grained supervision is always better and support generative outcome verification for multi-domain deployment. We publicly release our code, datasets, and checkpoints at \href{https://github.com/db-Lee/Multi-RM}{\underline{\small\texttt{https://github.com/db-Lee/Multi-RM}}} to facilitate future research in multi-domain settings.
Data-Efficient Prediction-Powered Calibration via Cross-Validation
Jul 27, 2025Calibration data are necessary to formally quantify the uncertainty of the decisions produced by an existing artificial intelligence (AI) model. To overcome the common issue of scarce calibration data, a promising approach is to employ synthetic labels produced by a (generally different) predictive model. However, fine-tuning the label-generating predictor on the inference task of interest, as well as estimating the residual bias of the synthetic labels, demand additional data, potentially exacerbating the calibration data scarcity problem. This paper introduces a novel approach that efficiently utilizes limited calibration data to simultaneously fine-tune a predictor and estimate the bias of the synthetic labels. The proposed method yields prediction sets with rigorous coverage guarantees for AI-generated decisions. Experimental results on an indoor localization problem validate the effectiveness and performance gains of our solution.
Adaptive Prediction-Powered AutoEval with Reliability and Efficiency Guarantees
May 24, 2025Selecting artificial intelligence (AI) models, such as large language models (LLMs), from multiple candidates requires accurate performance estimation. This is ideally achieved through empirical evaluations involving abundant real-world data. However, such evaluations are costly and impractical at scale. To address this challenge, autoevaluation methods leverage synthetic data produced by automated evaluators, such as LLMs-as-judges, reducing variance but potentially introducing bias. Recent approaches have employed semi-supervised prediction-powered inference (\texttt{PPI}) to correct for the bias of autoevaluators. However, the use of autoevaluators may lead in practice to a degradation in sample efficiency compared to conventional methods using only real-world data. In this paper, we propose \texttt{R-AutoEval+}, a novel framework that provides finite-sample reliability guarantees on the model evaluation, while also ensuring an enhanced (or at least no worse) sample efficiency compared to conventional methods. The key innovation of \texttt{R-AutoEval+} is an adaptive construction of the model evaluation variable, which dynamically tunes its reliance on synthetic data, reverting to conventional methods when the autoevaluator is insufficiently accurate. Experiments on the use of LLMs-as-judges for the optimization of quantization settings for the weights of an LLM, and for prompt design in LLMs confirm the reliability and efficiency of \texttt{R-AutoEval+}.