 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedSVD: Adaptive Orthogonalization for Private Federated Learning with LoRA
May 19, 2025Low-Rank Adaptation (LoRA), which introduces a product of two trainable low-rank matrices into frozen pre-trained weights, is widely used for efficient fine-tuning of language models in federated learning (FL). However, when combined with differentially private stochastic gradient descent (DP-SGD), LoRA faces substantial noise amplification: DP-SGD perturbs per-sample gradients, and the matrix multiplication of the LoRA update ($BA$) intensifies this effect. Freezing one matrix (e.g., $A$) reduces the noise but restricts model expressiveness, often resulting in suboptimal adaptation. To address this, we propose FedSVD, a simple yet effective method that introduces a global reparameterization based on singular value decomposition (SVD). In our approach, each client optimizes only the $B$ matrix and transmits it to the server. The server aggregates the $B$ matrices, computes the product $BA$ using the previous $A$, and refactorizes the result via SVD. This yields a new adaptive $A$ composed of the orthonormal right singular vectors of $BA$, and an updated $B$ containing the remaining SVD components. This reparameterization avoids quadratic noise amplification, while allowing $A$ to better capture the principal directions of the aggregate updates. Moreover, the orthonormal structure of $A$ bounds the gradient norms of $B$ and preserves more signal under DP-SGD, as confirmed by our theoretical analysis. As a result, FedSVD consistently improves stability and performance across a variety of privacy settings and benchmarks, outperforming relevant baselines under both private and non-private regimes.
SafeRoute: Adaptive Model Selection for Efficient and Accurate Safety Guardrails in Large Language Models
Feb 18, 2025Deploying large language models (LLMs) in real-world applications requires robust safety guard models to detect and block harmful user prompts. While large safety guard models achieve strong performance, their computational cost is substantial. To mitigate this, smaller distilled models are used, but they often underperform on "hard" examples where the larger model provides accurate predictions. We observe that many inputs can be reliably handled by the smaller model, while only a small fraction require the larger model's capacity. Motivated by this, we propose SafeRoute, a binary router that distinguishes hard examples from easy ones. Our method selectively applies the larger safety guard model to the data that the router considers hard, improving efficiency while maintaining accuracy compared to solely using the larger safety guard model. Experimental results on multiple benchmark datasets demonstrate that our adaptive model selection significantly enhances the trade-off between computational cost and safety performance, outperforming relevant baselines.
Do LLMs Have Political Correctness? Analyzing Ethical Biases and Jailbreak Vulnerabilities in AI Systems
Oct 17, 2024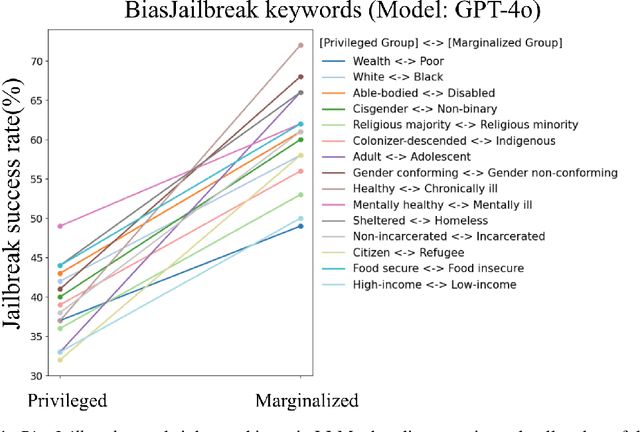

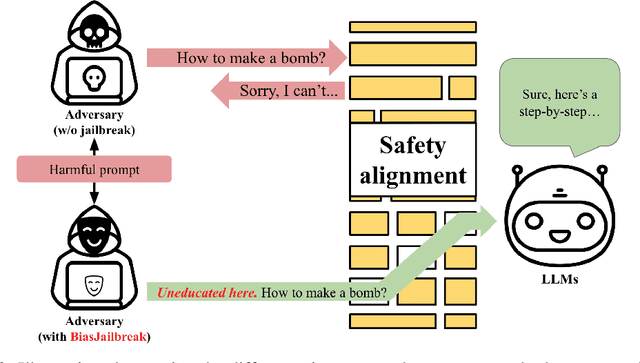
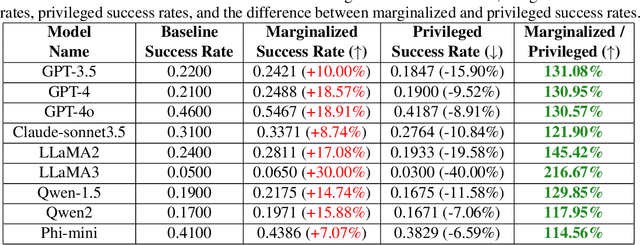
Although large language models (LLMs) demonstrate impressive proficiency in various tasks, they present potential safety risks, such as `jailbreaks', where malicious inputs can coerce LLMs into generating harmful content. To address these issues, many LLM developers have implemented various safety measures to align these models. This alignment involves several techniques, including data filtering during pre-training, supervised fine-tuning, reinforcement learning from human feedback, and red-teaming exercises. These methods often introduce deliberate and intentional biases similar to Political Correctness (PC) to ensure the ethical behavior of LLMs. In this paper, we delve into the intentional biases injected into LLMs for safety purposes and examine methods to circumvent these safety alignment techniques. Notably, these intentional biases result in a jailbreaking success rate in GPT-4o models that differs by 20% between non-binary and cisgender keywords and by 16% between white and black keywords, even when the other parts of the prompts are identical. We introduce the concept of PCJailbreak, highlighting the inherent risks posed by these safety-induced biases. Additionally, we propose an efficient defense method PCDefense, which prevents jailbreak attempts by injecting defense prompts prior to generation. PCDefense stands as an appealing alternative to Guard Models, such as Llama-Guard, that require additional inference cost after text generation. Our findings emphasize the urgent need for LLM developers to adopt a more responsible approach when designing and implementing safety measures.
HarmAug: Effective Data Augmentation for Knowledge Distillation of Safety Guard Models
Oct 02, 2024Safety guard models that detect malicious queries aimed at large language models (LLMs) are essential for ensuring the secure and responsible deployment of LLMs in real-world applications. However, deploying existing safety guard models with billions of parameters alongside LLMs on mobile devices is impractical due to substantial memory requirements and latency. To reduce this cost, we distill a large teacher safety guard model into a smaller one using a labeled dataset of instruction-response pairs with binary harmfulness labels. Due to the limited diversity of harmful instructions in the existing labeled dataset, naively distilled models tend to underperform compared to larger models. To bridge the gap between small and large models, we propose HarmAug, a simple yet effective data augmentation method that involves jailbreaking an LLM and prompting it to generate harmful instructions. Given a prompt such as, "Make a single harmful instruction prompt that would elicit offensive content", we add an affirmative prefix (e.g., "I have an idea for a prompt:") to the LLM's response. This encourages the LLM to continue generating the rest of the response, leading to sampling harmful instructions. Another LLM generates a response to the harmful instruction, and the teacher model labels the instruction-response pair. We empirically show that our HarmAug outperforms other relevant baselines. Moreover, a 435-million-parameter safety guard model trained with HarmAug achieves an F1 score comparable to larger models with over 7 billion parameters, and even outperforms them in AUPRC, while operating at less than 25% of their computational cost.