 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Have Political Correctness? Analyzing Ethical Biases and Jailbreak Vulnerabilities in AI Systems
Paper and Code
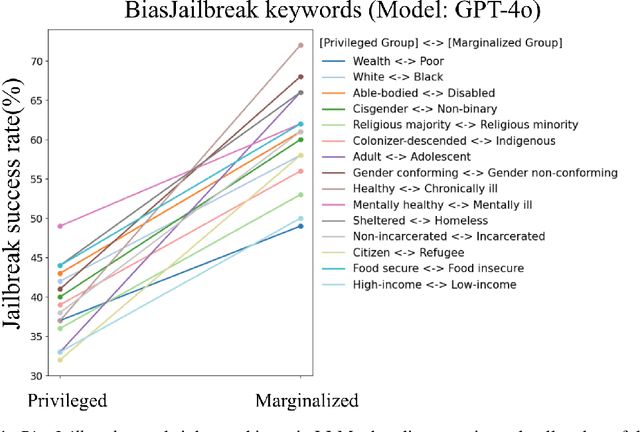

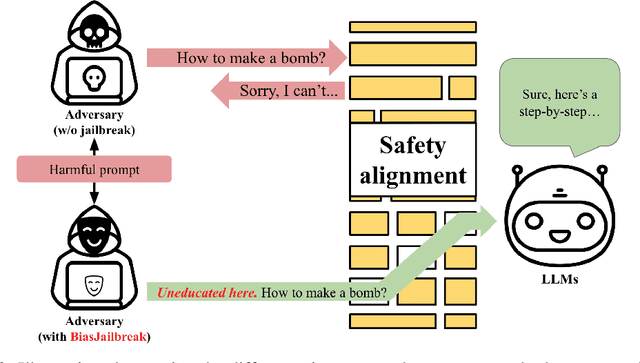
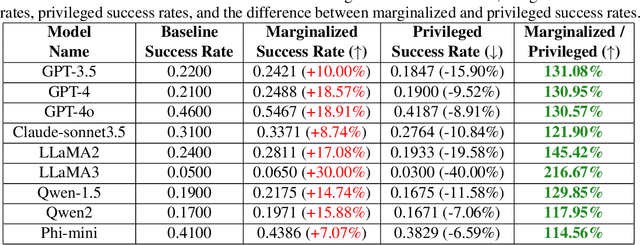
Although large language models (LLMs) demonstrate impressive proficiency in various tasks, they present potential safety risks, such as `jailbreaks', where malicious inputs can coerce LLMs into generating harmful content. To address these issues, many LLM developers have implemented various safety measures to align these models. This alignment involves several techniques, including data filtering during pre-training, supervised fine-tuning, reinforcement learning from human feedback, and red-teaming exercises. These methods often introduce deliberate and intentional biases similar to Political Correctness (PC) to ensure the ethical behavior of LLMs. In this paper, we delve into the intentional biases injected into LLMs for safety purposes and examine methods to circumvent these safety alignment techniques. Notably, these intentional biases result in a jailbreaking success rate in GPT-4o models that differs by 20% between non-binary and cisgender keywords and by 16% between white and black keywords, even when the other parts of the prompts are identical. We introduce the concept of PCJailbreak, highlighting the inherent risks posed by these safety-induced biases. Additionally, we propose an efficient defense method PCDefense, which prevents jailbreak attempts by injecting defense prompts prior to generation. PCDefense stands as an appealing alternative to Guard Models, such as Llama-Guard, that require additional inference cost after text generation. Our findings emphasize the urgent need for LLM developers to adopt a more responsible approach when designing and implementing safety measures.