 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Have Political Correctness? Analyzing Ethical Biases and Jailbreak Vulnerabilities in AI Systems
Oct 17, 2024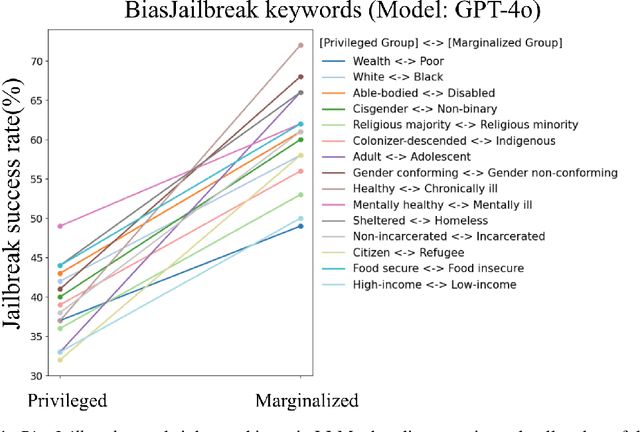

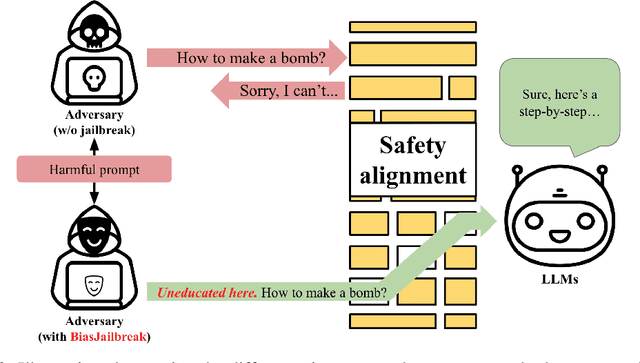
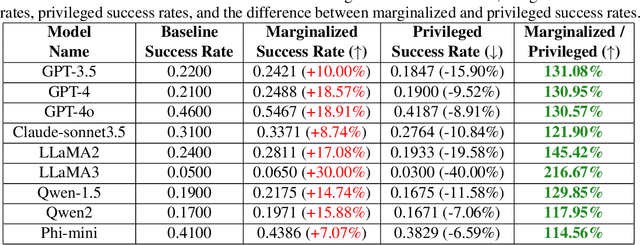
Although large language models (LLMs) demonstrate impressive proficiency in various tasks, they present potential safety risks, such as `jailbreaks', where malicious inputs can coerce LLMs into generating harmful content. To address these issues, many LLM developers have implemented various safety measures to align these models. This alignment involves several techniques, including data filtering during pre-training, supervised fine-tuning, reinforcement learning from human feedback, and red-teaming exercises. These methods often introduce deliberate and intentional biases similar to Political Correctness (PC) to ensure the ethical behavior of LLMs. In this paper, we delve into the intentional biases injected into LLMs for safety purposes and examine methods to circumvent these safety alignment techniques. Notably, these intentional biases result in a jailbreaking success rate in GPT-4o models that differs by 20% between non-binary and cisgender keywords and by 16% between white and black keywords, even when the other parts of the prompts are identical. We introduce the concept of PCJailbreak, highlighting the inherent risks posed by these safety-induced biases. Additionally, we propose an efficient defense method PCDefense, which prevents jailbreak attempts by injecting defense prompts prior to generation. PCDefense stands as an appealing alternative to Guard Models, such as Llama-Guard, that require additional inference cost after text generation. Our findings emphasize the urgent need for LLM developers to adopt a more responsible approach when designing and implementing safety measures.
Latent-OFER: Detect, Mask, and Reconstruct with Latent Vectors for Occluded Facial Expression Recognition
Jul 21, 2023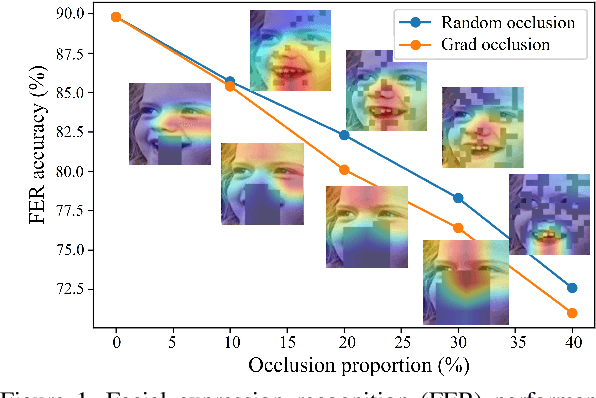

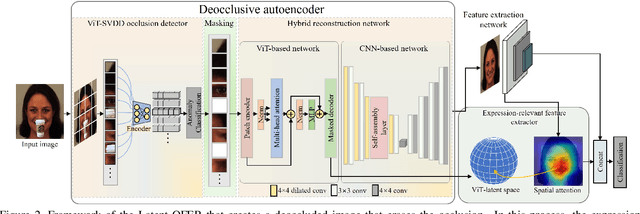
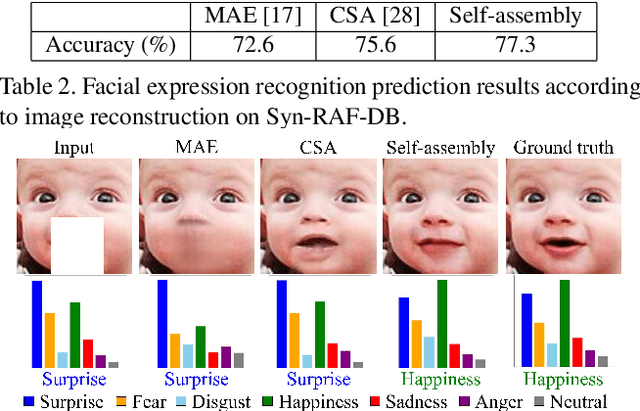
Most research on facial expression recognition (FER) is conducted in highly controlled environments, but its performance is often unacceptable when applied to real-world situations. This is because when unexpected objects occlude the face, the FER network faces difficulties extracting facial features and accurately predicting facial expressions. Therefore, occluded FER (OFER) is a challenging problem. Previous studies on occlusion-aware FER have typically required fully annotated facial images for training. However, collecting facial images with various occlusions and expression annotations is time-consuming and expensive. Latent-OFER, the proposed method, can detect occlusions, restore occluded parts of the face as if they were unoccluded, and recognize them, improving FER accuracy. This approach involves three steps: First, the vision transformer (ViT)-based occlusion patch detector masks the occluded position by training only latent vectors from the unoccluded patches using the support vector data description algorithm. Second, the hybrid reconstruction network generates the masking position as a complete image using the ViT and convolutional neural network (CNN). Last, the expression-relevant latent vector extractor retrieves and uses expression-related information from all latent vectors by applying a CNN-based class activation map. This mechanism has a significant advantage in preventing performance degradation from occlusion by unseen objects. The experimental results on several databases demonstrate the superiority of the proposed method over state-of-the-art methods.
LatentGaze: Cross-Domain Gaze Estimation through Gaze-Aware Analytic Latent Code Manipulation
Sep 21, 2022
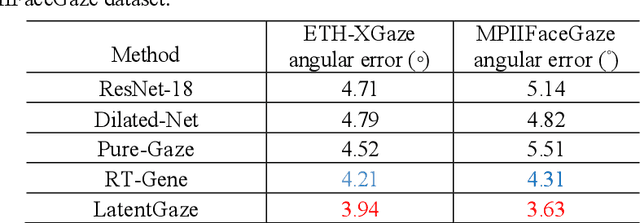
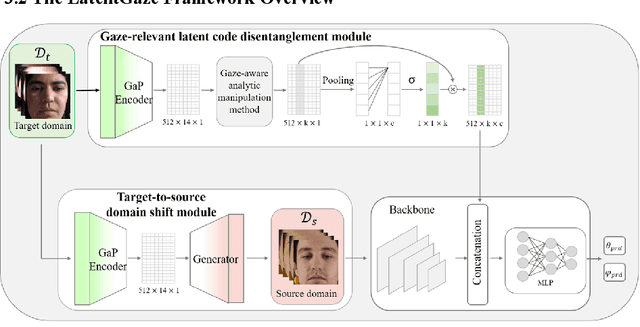
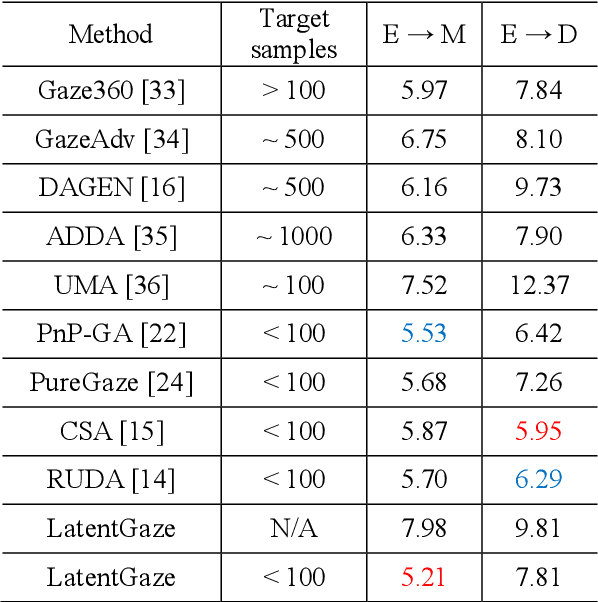
Although recent gaze estimation methods lay great emphasis on attentively extracting gaze-relevant features from facial or eye images, how to define features that include gaze-relevant components has been ambiguous. This obscurity makes the model learn not only gaze-relevant features but also irrelevant ones. In particular, it is fatal for the cross-dataset performance. To overcome this challenging issue, we propose a gaze-aware analytic manipulation method, based on a data-driven approach with generative adversarial network inversion's disentanglement characteristics, to selectively utilize gaze-relevant features in a latent code. Furthermore, by utilizing GAN-based encoder-generator process, we shift the input image from the target domain to the source domain image, which a gaze estimator is sufficiently aware. In addition, we propose gaze distortion loss in the encoder that prevents the distortion of gaze information. The experimental results demonstrate that our method achieves state-of-the-art gaze estimation accuracy in a cross-domain gaze estimation tasks. This code is available at https://github.com/leeisack/LatentGaze/.