 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLINT: Modeling Scene-Scale Transparency via Gaussian Radiance Transport
Mar 27, 2026While 3D Gaussian splatting has emerged as a powerful paradigm, it fundamentally fails to model transparency such as glass panels. The core challenge lies in decoupling the intertwined radiance contributions from transparent interfaces and the transmitted geometry observed through the glass. We present GLINT, a framework that models scene-scale transparency through explicit decomposed Gaussian representation. GLINT reconstructs the primary interface and models reflected and transmitted radiance separately, enabling consistent radiance transport. During optimization, GLINT bootstraps transparency localization from geometry-separation cues induced by the decomposition, together with geometry and material priors from a pre-trained video relighting model. Extensive experiments demonstrate consistent improvements over prior methods for reconstructing complex transparent scenes.
CAMO: Category-Agnostic 3D Motion Transfer from Monocular 2D Videos
Jan 06, 2026Motion transfer from 2D videos to 3D assets is a challenging problem, due to inherent pose ambiguities and diverse object shapes, often requiring category-specific parametric templates. We propose CAMO, a category-agnostic framework that transfers motion to diverse target meshes directly from monocular 2D videos without relying on predefined templates or explicit 3D supervision. The core of CAMO is a morphology-parameterized articulated 3D Gaussian splatting model combined with dense semantic correspondences to jointly adapt shape and pose through optimization. This approach effectively alleviates shape-pose ambiguities, enabling visually faithful motion transfer for diverse categories. Experimental results demonstrate superior motion accuracy, efficiency, and visual coherence compared to existing methods, significantly advancing motion transfer in varied object categories and casual video scenarios.
Pose-free 3D Gaussian splatting via shape-ray estimation
May 29, 2025



While generalizable 3D Gaussian splatting enables efficient, high-quality rendering of unseen scenes, it heavily depends on precise camera poses for accurate geometry. In real-world scenarios, obtaining accurate poses is challenging, leading to noisy pose estimates and geometric misalignments. To address this, we introduce SHARE, a pose-free, feed-forward Gaussian splatting framework that overcomes these ambiguities by joint shape and camera rays estimation. Instead of relying on explicit 3D transformations, SHARE builds a pose-aware canonical volume representation that seamlessly integrates multi-view information, reducing misalignment caused by inaccurate pose estimates. Additionally, anchor-aligned Gaussian prediction enhances scene reconstruction by refining local geometry around coarse anchors, allowing for more precise Gaussian placement. Extensive experiments on diverse real-world datasets show that our method achieves robust performance in pose-free generalizable Gaussian splatting.
UFORecon: Generalizable Sparse-View Surface Reconstruction from Arbitrary and UnFavOrable Sets
Mar 11, 2024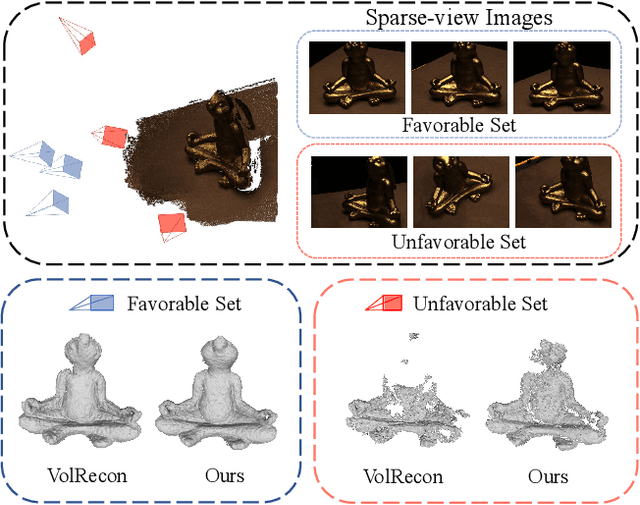
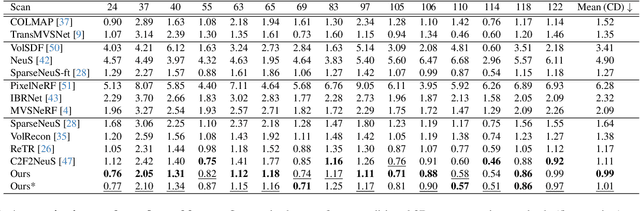
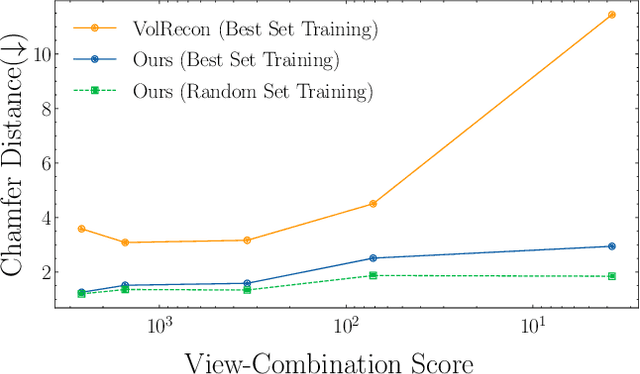

Generalizable neural implicit surface reconstruction aims to obtain an accurate underlying geometry given a limited number of multi-view images from unseen scenes. However, existing methods select only informative and relevant views using predefined scores for training and testing phases. This constraint renders the model impractical in real-world scenarios, where the availability of favorable combinations cannot always be ensured. We introduce and validate a view-combination score to indicate the effectiveness of the input view combination. We observe that previous methods output degenerate solutions under arbitrary and unfavorable sets. Building upon this finding, we propose UFORecon, a robust view-combination generalizable surface reconstruction framework. To achieve this, we apply cross-view matching transformers to model interactions between source images and build correlation frustums to capture global correlations. Additionally, we explicitly encode pairwise feature similarities as view-consistent priors. Our proposed framework significantly outperforms previous methods in terms of view-combination generalizability and also in the conventional generalizable protocol trained with favorable view-combinations. The code is available at https://github.com/Youngju-Na/UFORecon.
LatentGaze: Cross-Domain Gaze Estimation through Gaze-Aware Analytic Latent Code Manipulation
Sep 21, 2022
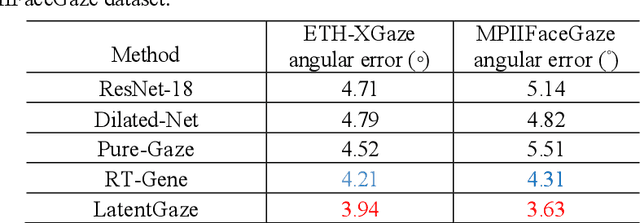
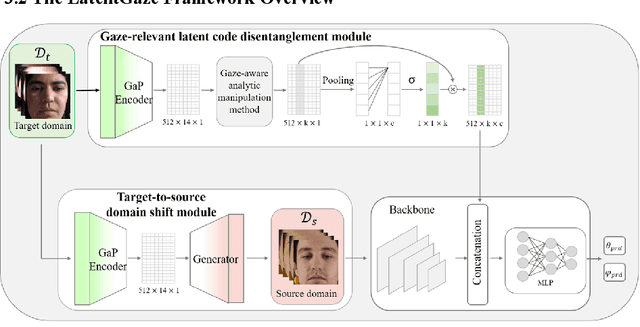
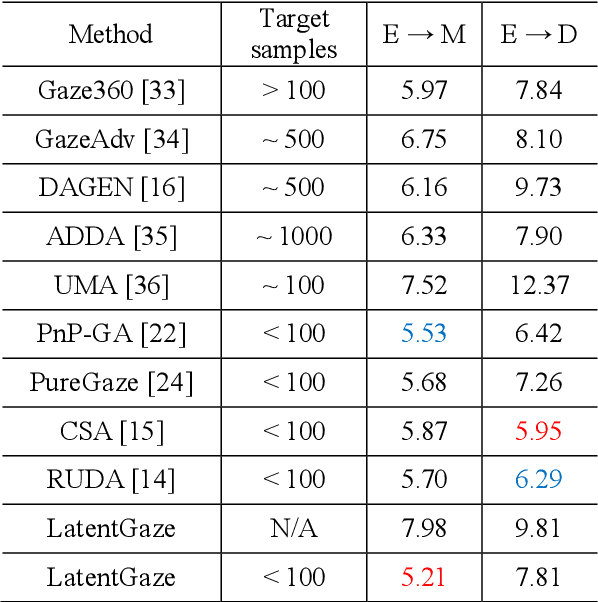
Although recent gaze estimation methods lay great emphasis on attentively extracting gaze-relevant features from facial or eye images, how to define features that include gaze-relevant components has been ambiguous. This obscurity makes the model learn not only gaze-relevant features but also irrelevant ones. In particular, it is fatal for the cross-dataset performance. To overcome this challenging issue, we propose a gaze-aware analytic manipulation method, based on a data-driven approach with generative adversarial network inversion's disentanglement characteristics, to selectively utilize gaze-relevant features in a latent code. Furthermore, by utilizing GAN-based encoder-generator process, we shift the input image from the target domain to the source domain image, which a gaze estimator is sufficiently aware. In addition, we propose gaze distortion loss in the encoder that prevents the distortion of gaze information. The experimental results demonstrate that our method achieves state-of-the-art gaze estimation accuracy in a cross-domain gaze estimation tasks. This code is available at https://github.com/leeisack/LatentGaze/.
HAZE-Net: High-Frequency Attentive Super-Resolved Gaze Estimation in Low-Resolution Face Images
Sep 21, 2022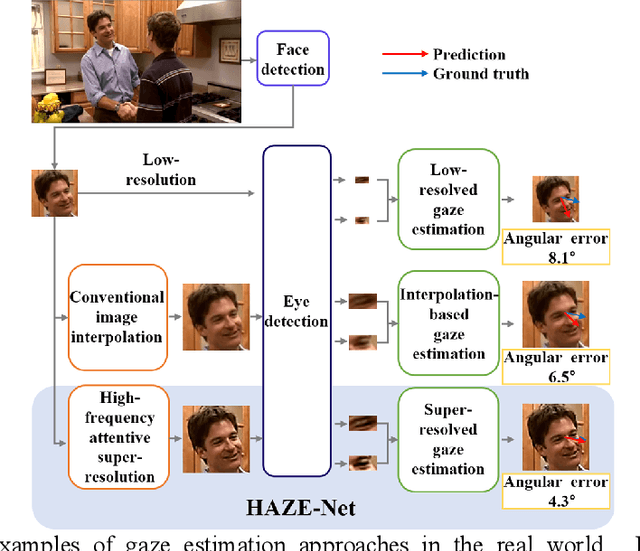

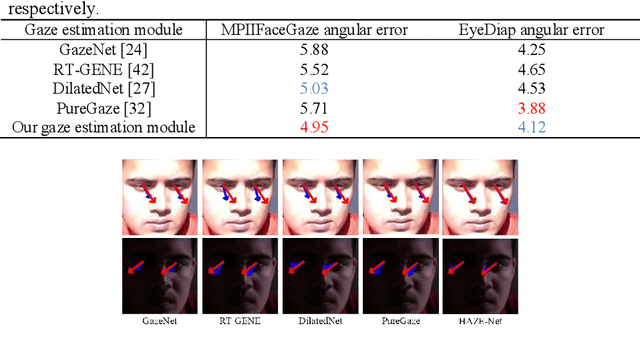
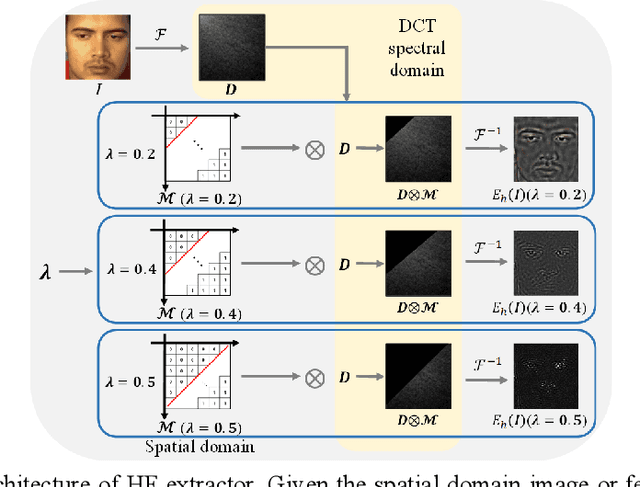
Although gaze estimation methods have been developed with deep learning techniques, there has been no such approach as aim to attain accurate performance in low-resolution face images with a pixel width of 50 pixels or less. To solve a limitation under the challenging low-resolution conditions, we propose a high-frequency attentive super-resolved gaze estimation network, i.e., HAZE-Net. Our network improves the resolution of the input image and enhances the eye features and those boundaries via a proposed super-resolution module based on a high-frequency attention block. In addition, our gaze estimation module utilizes high-frequency components of the eye as well as the global appearance map. We also utilize the structural location information of faces to approximate head pose. The experimental results indicate that the proposed method exhibits robust gaze estimation performance even in low-resolution face images with 28x28 pixels. The source code of this work is available at https://github.com/dbseorms16/HAZE_Net/.