 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadiometrically Consistent Gaussian Surfels for Inverse Rendering
Mar 02, 2026Inverse rendering with Gaussian Splatting has advanced rapidly, but accurately disentangling material properties from complex global illumination effects, particularly indirect illumination, remains a major challenge. Existing methods often query indirect radiance from Gaussian primitives pre-trained for novel-view synthesis. However, these pre-trained Gaussian primitives are supervised only towards limited training viewpoints, thus lack supervision for modeling indirect radiances from unobserved views. To address this issue, we introduce radiometric consistency, a novel physically-based constraint that provides supervision towards unobserved views by minimizing the residual between each Gaussian primitive's learned radiance and its physically-based rendered counterpart. Minimizing the residual for unobserved views establishes a self-correcting feedback loop that provides supervision from both physically-based rendering and novel-view synthesis, enabling accurate modeling of inter-reflection. We then propose Radiometrically Consistent Gaussian Surfels (RadioGS), an inverse rendering framework built upon our principle by efficiently integrating radiometric consistency by utilizing Gaussian surfels and 2D Gaussian ray tracing. We further propose a finetuning-based relighting strategy that adapts Gaussian surfel radiances to new illuminations within minutes, achieving low rendering cost (<10ms). Extensive experiments on existing inverse rendering benchmarks show that RadioGS outperforms existing Gaussian-based methods in inverse rendering, while retaining the computational efficiency.
No Caption, No Problem: Caption-Free Membership Inference via Model-Fitted Embeddings
Feb 26, 2026Latent diffusion models have achieved remarkable success in high-fidelity text-to-image generation, but their tendency to memorize training data raises critical privacy and intellectual property concerns. Membership inference attacks (MIAs) provide a principled way to audit such memorization by determining whether a given sample was included in training. However, existing approaches assume access to ground-truth captions. This assumption fails in realistic scenarios where only images are available and their textual annotations remain undisclosed, rendering prior methods ineffective when substituted with vision-language model (VLM) captions. In this work, we propose MoFit, a caption-free MIA framework that constructs synthetic conditioning inputs that are explicitly overfitted to the target model's generative manifold. Given a query image, MoFit proceeds in two stages: (i) model-fitted surrogate optimization, where a perturbation applied to the image is optimized to construct a surrogate in regions of the model's unconditional prior learned from member samples, and (ii) surrogate-driven embedding extraction, where a model-fitted embedding is derived from the surrogate and then used as a mismatched condition for the query image. This embedding amplifies conditional loss responses for member samples while leaving hold-outs relatively less affected, thereby enhancing separability in the absence of ground-truth captions. Our comprehensive experiments across multiple datasets and diffusion models demonstrate that MoFit consistently outperforms prior VLM-conditioned baselines and achieves performance competitive with caption-dependent methods.
Learning Event-guided Exposure-agnostic Video Frame Interpolation via Adaptive Feature Blending
Oct 26, 2025Exposure-agnostic video frame interpolation (VFI) is a challenging task that aims to recover sharp, high-frame-rate videos from blurry, low-frame-rate inputs captured under unknown and dynamic exposure conditions. Event cameras are sensors with high temporal resolution, making them especially advantageous for this task. However, existing event-guided methods struggle to produce satisfactory results on severely low-frame-rate blurry videos due to the lack of temporal constraints. In this paper, we introduce a novel event-guided framework for exposure-agnostic VFI, addressing this limitation through two key components: a Target-adaptive Event Sampling (TES) and a Target-adaptive Importance Mapping (TIM). Specifically, TES samples events around the target timestamp and the unknown exposure time to better align them with the corresponding blurry frames. TIM then generates an importance map that considers the temporal proximity and spatial relevance of consecutive features to the target. Guided by this map, our framework adaptively blends consecutive features, allowing temporally aligned features to serve as the primary cues while spatially relevant ones offer complementary support. Extensive experiments on both synthetic and real-world datasets demonstrate the effectiveness of our approach in exposure-agnostic VFI scenarios.
Pose-free 3D Gaussian splatting via shape-ray estimation
May 29, 2025



While generalizable 3D Gaussian splatting enables efficient, high-quality rendering of unseen scenes, it heavily depends on precise camera poses for accurate geometry. In real-world scenarios, obtaining accurate poses is challenging, leading to noisy pose estimates and geometric misalignments. To address this, we introduce SHARE, a pose-free, feed-forward Gaussian splatting framework that overcomes these ambiguities by joint shape and camera rays estimation. Instead of relying on explicit 3D transformations, SHARE builds a pose-aware canonical volume representation that seamlessly integrates multi-view information, reducing misalignment caused by inaccurate pose estimates. Additionally, anchor-aligned Gaussian prediction enhances scene reconstruction by refining local geometry around coarse anchors, allowing for more precise Gaussian placement. Extensive experiments on diverse real-world datasets show that our method achieves robust performance in pose-free generalizable Gaussian splatting.
AdvPaint: Protecting Images from Inpainting Manipulation via Adversarial Attention Disruption
Mar 13, 2025
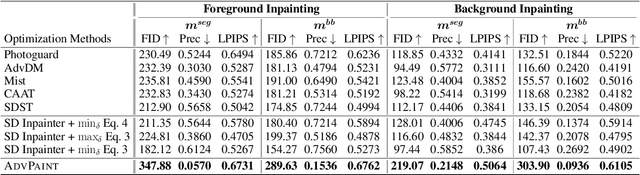
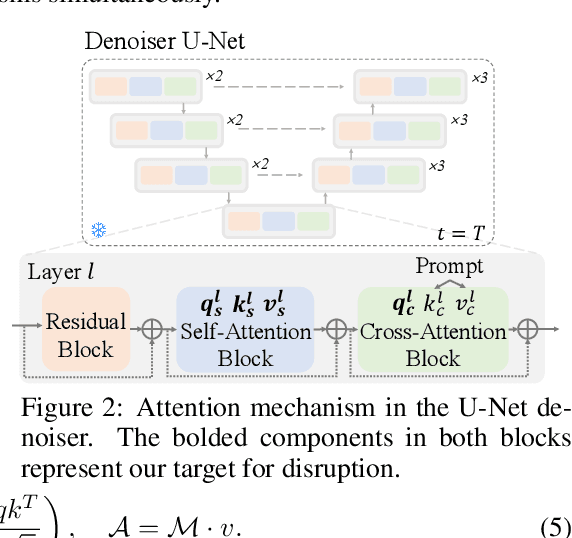

The outstanding capability of diffusion models in generating high-quality images poses significant threats when misused by adversaries. In particular, we assume malicious adversaries exploiting diffusion models for inpainting tasks, such as replacing a specific region with a celebrity. While existing methods for protecting images from manipulation in diffusion-based generative models have primarily focused on image-to-image and text-to-image tasks, the challenge of preventing unauthorized inpainting has been rarely addressed, often resulting in suboptimal protection performance. To mitigate inpainting abuses, we propose ADVPAINT, a novel defensive framework that generates adversarial perturbations that effectively disrupt the adversary's inpainting tasks. ADVPAINT targets the self- and cross-attention blocks in a target diffusion inpainting model to distract semantic understanding and prompt interactions during image generation. ADVPAINT also employs a two-stage perturbation strategy, dividing the perturbation region based on an enlarged bounding box around the object, enhancing robustness across diverse masks of varying shapes and sizes. Our experimental results demonstrate that ADVPAINT's perturbations are highly effective in disrupting the adversary's inpainting tasks, outperforming existing methods; ADVPAINT attains over a 100-point increase in FID and substantial decreases in precision.
UFORecon: Generalizable Sparse-View Surface Reconstruction from Arbitrary and UnFavOrable Sets
Mar 11, 2024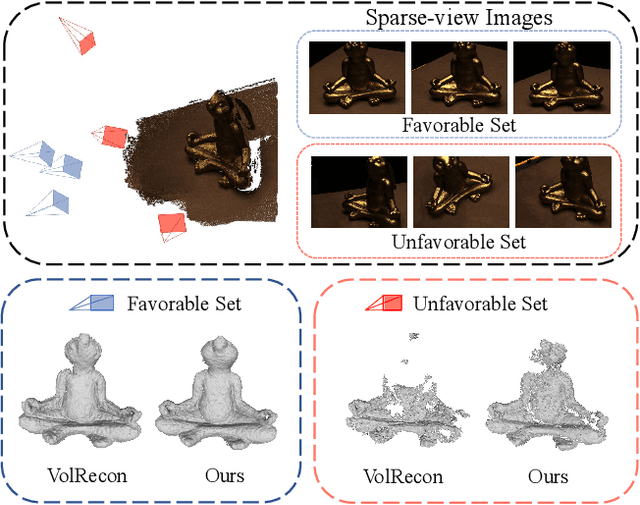
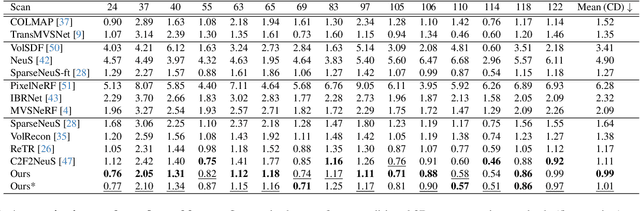
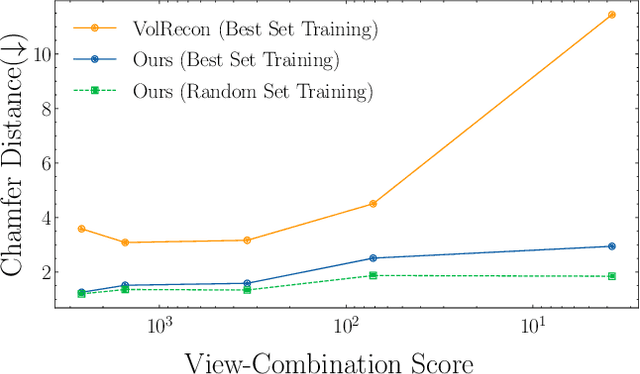

Generalizable neural implicit surface reconstruction aims to obtain an accurate underlying geometry given a limited number of multi-view images from unseen scenes. However, existing methods select only informative and relevant views using predefined scores for training and testing phases. This constraint renders the model impractical in real-world scenarios, where the availability of favorable combinations cannot always be ensured. We introduce and validate a view-combination score to indicate the effectiveness of the input view combination. We observe that previous methods output degenerate solutions under arbitrary and unfavorable sets. Building upon this finding, we propose UFORecon, a robust view-combination generalizable surface reconstruction framework. To achieve this, we apply cross-view matching transformers to model interactions between source images and build correlation frustums to capture global correlations. Additionally, we explicitly encode pairwise feature similarities as view-consistent priors. Our proposed framework significantly outperforms previous methods in terms of view-combination generalizability and also in the conventional generalizable protocol trained with favorable view-combinations. The code is available at https://github.com/Youngju-Na/UFORecon.
Deep Video Inpainting Guided by Audio-Visual Self-Supervision
Oct 11, 2023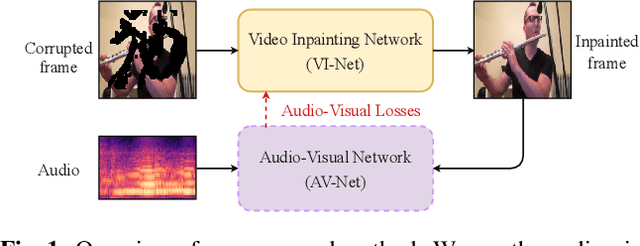
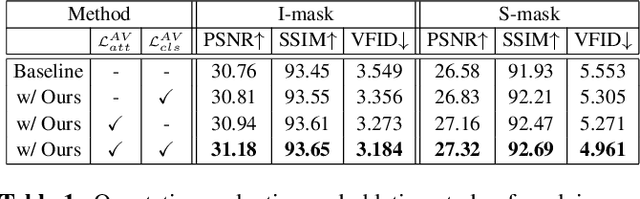
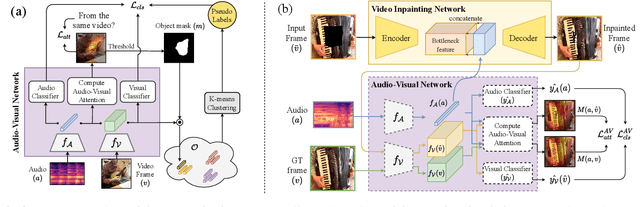
Humans can easily imagine a scene from auditory information based on their prior knowledge of audio-visual events. In this paper, we mimic this innate human ability in deep learning models to improve the quality of video inpainting. To implement the prior knowledge, we first train the audio-visual network, which learns the correspondence between auditory and visual information. Then, the audio-visual network is employed as a guider that conveys the prior knowledge of audio-visual correspondence to the video inpainting network. This prior knowledge is transferred through our proposed two novel losses: audio-visual attention loss and audio-visual pseudo-class consistency loss. These two losses further improve the performance of the video inpainting by encouraging the inpainting result to have a high correspondence to its synchronized audio. Experimental results demonstrate that our proposed method can restore a wider domain of video scenes and is particularly effective when the sounding object in the scene is partially blinded.
Towards Content-based Pixel Retrieval in Revisited Oxford and Paris
Sep 11, 2023This paper introduces the first two pixel retrieval benchmarks. Pixel retrieval is segmented instance retrieval. Like semantic segmentation extends classification to the pixel level, pixel retrieval is an extension of image retrieval and offers information about which pixels are related to the query object. In addition to retrieving images for the given query, it helps users quickly identify the query object in true positive images and exclude false positive images by denoting the correlated pixels. Our user study results show pixel-level annotation can significantly improve the user experience. Compared with semantic and instance segmentation, pixel retrieval requires a fine-grained recognition capability for variable-granularity targets. To this end, we propose pixel retrieval benchmarks named PROxford and PRParis, which are based on the widely used image retrieval datasets, ROxford and RParis. Three professional annotators label 5,942 images with two rounds of double-checking and refinement. Furthermore, we conduct extensive experiments and analysis on the SOTA methods in image search, image matching, detection, segmentation, and dense matching using our pixel retrieval benchmarks. Results show that the pixel retrieval task is challenging to these approaches and distinctive from existing problems, suggesting that further research can advance the content-based pixel-retrieval and thus user search experience. The datasets can be downloaded from \href{https://github.com/anguoyuan/Pixel_retrieval-Segmented_instance_retrieval}{this link}.
Pixel-wise Guidance for Utilizing Auxiliary Features in Monte Carlo Denoising
Apr 11, 2023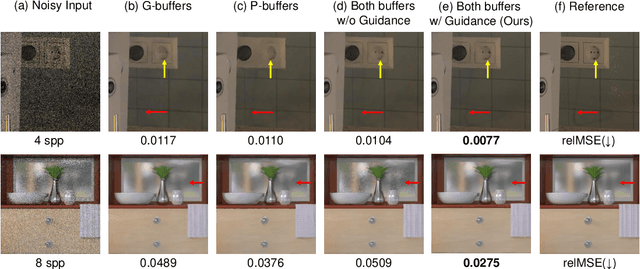

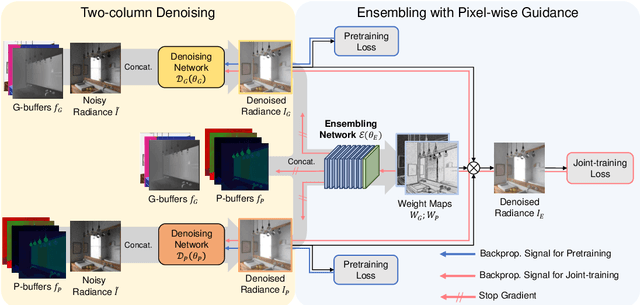

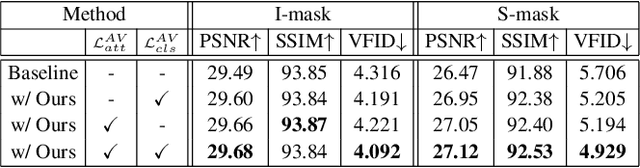
Auxiliary features such as geometric buffers (G-buffers) and path descriptors (P-buffers) have been shown to significantly improve Monte Carlo (MC) denoising. However, recent approaches implicitly learn to exploit auxiliary features for denoising, which could lead to insufficient utilization of each type of auxiliary features. To overcome such an issue, we propose a denoising framework that relies on an explicit pixel-wise guidance for utilizing auxiliary features. First, we train two denoisers, each trained by a different auxiliary feature (i.e., G-buffers or P-buffers). Then we design our ensembling network to obtain per-pixel ensembling weight maps, which represent pixel-wise guidance for which auxiliary feature should be dominant at reconstructing each individual pixel and use them to ensemble the two denoised results of our denosiers. We also propagate our pixel-wise guidance to the denoisers by jointly training the denoisers and the ensembling network, further guiding the denoisers to focus on regions where G-buffers or P-buffers are relatively important for denoising. Our result and show considerable improvement in denoising performance compared to the baseline denoising model using both G-buffers and P-buffers.
Feature Separation and Recalibration for Adversarial Robustness
Mar 24, 2023



Deep neural networks are susceptible to adversarial attacks due to the accumulation of perturbations in the feature level, and numerous works have boosted model robustness by deactivating the non-robust feature activations that cause model mispredictions. However, we claim that these malicious activations still contain discriminative cues and that with recalibration, they can capture additional useful information for correct model predictions. To this end, we propose a novel, easy-to-plugin approach named Feature Separation and Recalibration (FSR) that recalibrates the malicious, non-robust activations for more robust feature maps through Separation and Recalibration. The Separation part disentangles the input feature map into the robust feature with activations that help the model make correct predictions and the non-robust feature with activations that are responsible for model mispredictions upon adversarial attack. The Recalibration part then adjusts the non-robust activations to restore the potentially useful cues for model predictions. Extensive experiments verify the superiority of FSR compared to traditional deactivation techniques and demonstrate that it improves the robustness of existing adversarial training methods by up to 8.57% with small computational overhead. Codes are available at https://github.com/wkim97/FSR.