 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Event-guided Exposure-agnostic Video Frame Interpolation via Adaptive Feature Blending
Oct 26, 2025Exposure-agnostic video frame interpolation (VFI) is a challenging task that aims to recover sharp, high-frame-rate videos from blurry, low-frame-rate inputs captured under unknown and dynamic exposure conditions. Event cameras are sensors with high temporal resolution, making them especially advantageous for this task. However, existing event-guided methods struggle to produce satisfactory results on severely low-frame-rate blurry videos due to the lack of temporal constraints. In this paper, we introduce a novel event-guided framework for exposure-agnostic VFI, addressing this limitation through two key components: a Target-adaptive Event Sampling (TES) and a Target-adaptive Importance Mapping (TIM). Specifically, TES samples events around the target timestamp and the unknown exposure time to better align them with the corresponding blurry frames. TIM then generates an importance map that considers the temporal proximity and spatial relevance of consecutive features to the target. Guided by this map, our framework adaptively blends consecutive features, allowing temporally aligned features to serve as the primary cues while spatially relevant ones offer complementary support. Extensive experiments on both synthetic and real-world datasets demonstrate the effectiveness of our approach in exposure-agnostic VFI scenarios.
Deep Video Inpainting Guided by Audio-Visual Self-Supervision
Oct 11, 2023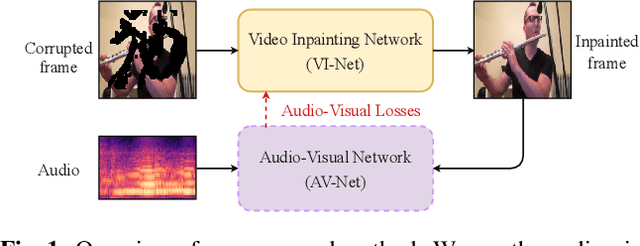
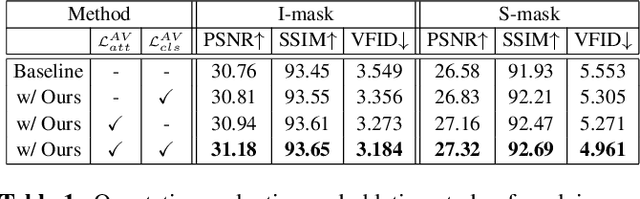
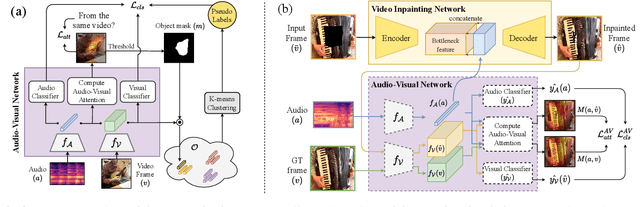
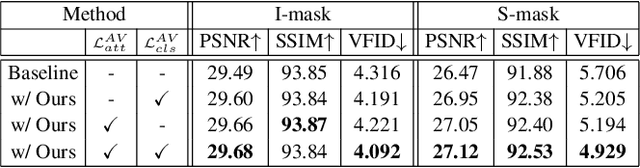
Humans can easily imagine a scene from auditory information based on their prior knowledge of audio-visual events. In this paper, we mimic this innate human ability in deep learning models to improve the quality of video inpainting. To implement the prior knowledge, we first train the audio-visual network, which learns the correspondence between auditory and visual information. Then, the audio-visual network is employed as a guider that conveys the prior knowledge of audio-visual correspondence to the video inpainting network. This prior knowledge is transferred through our proposed two novel losses: audio-visual attention loss and audio-visual pseudo-class consistency loss. These two losses further improve the performance of the video inpainting by encouraging the inpainting result to have a high correspondence to its synchronized audio. Experimental results demonstrate that our proposed method can restore a wider domain of video scenes and is particularly effective when the sounding object in the scene is partially blinded.
Feature Separation and Recalibration for Adversarial Robustness
Mar 24, 2023



Deep neural networks are susceptible to adversarial attacks due to the accumulation of perturbations in the feature level, and numerous works have boosted model robustness by deactivating the non-robust feature activations that cause model mispredictions. However, we claim that these malicious activations still contain discriminative cues and that with recalibration, they can capture additional useful information for correct model predictions. To this end, we propose a novel, easy-to-plugin approach named Feature Separation and Recalibration (FSR) that recalibrates the malicious, non-robust activations for more robust feature maps through Separation and Recalibration. The Separation part disentangles the input feature map into the robust feature with activations that help the model make correct predictions and the non-robust feature with activations that are responsible for model mispredictions upon adversarial attack. The Recalibration part then adjusts the non-robust activations to restore the potentially useful cues for model predictions. Extensive experiments verify the superiority of FSR compared to traditional deactivation techniques and demonstrate that it improves the robustness of existing adversarial training methods by up to 8.57% with small computational overhead. Codes are available at https://github.com/wkim97/FSR.