 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Caption, No Problem: Caption-Free Membership Inference via Model-Fitted Embeddings
Feb 26, 2026Latent diffusion models have achieved remarkable success in high-fidelity text-to-image generation, but their tendency to memorize training data raises critical privacy and intellectual property concerns. Membership inference attacks (MIAs) provide a principled way to audit such memorization by determining whether a given sample was included in training. However, existing approaches assume access to ground-truth captions. This assumption fails in realistic scenarios where only images are available and their textual annotations remain undisclosed, rendering prior methods ineffective when substituted with vision-language model (VLM) captions. In this work, we propose MoFit, a caption-free MIA framework that constructs synthetic conditioning inputs that are explicitly overfitted to the target model's generative manifold. Given a query image, MoFit proceeds in two stages: (i) model-fitted surrogate optimization, where a perturbation applied to the image is optimized to construct a surrogate in regions of the model's unconditional prior learned from member samples, and (ii) surrogate-driven embedding extraction, where a model-fitted embedding is derived from the surrogate and then used as a mismatched condition for the query image. This embedding amplifies conditional loss responses for member samples while leaving hold-outs relatively less affected, thereby enhancing separability in the absence of ground-truth captions. Our comprehensive experiments across multiple datasets and diffusion models demonstrate that MoFit consistently outperforms prior VLM-conditioned baselines and achieves performance competitive with caption-dependent methods.
Discovering Universal Activation Directions for PII Leakage in Language Models
Feb 19, 2026Modern language models exhibit rich internal structure, yet little is known about how privacy-sensitive behaviors, such as personally identifiable information (PII) leakage, are represented and modulated within their hidden states. We present UniLeak, a mechanistic-interpretability framework that identifies universal activation directions: latent directions in a model's residual stream whose linear addition at inference time consistently increases the likelihood of generating PII across prompts. These model-specific directions generalize across contexts and amplify PII generation probability, with minimal impact on generation quality. UniLeak recovers such directions without access to training data or groundtruth PII, relying only on self-generated text. Across multiple models and datasets, steering along these universal directions substantially increases PII leakage compared to existing prompt-based extraction methods. Our results offer a new perspective on PII leakage: the superposition of a latent signal in the model's representations, enabling both risk amplification and mitigation.
AdvPaint: Protecting Images from Inpainting Manipulation via Adversarial Attention Disruption
Mar 13, 2025
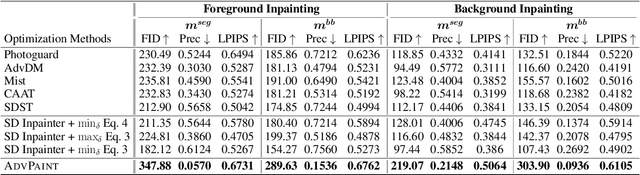
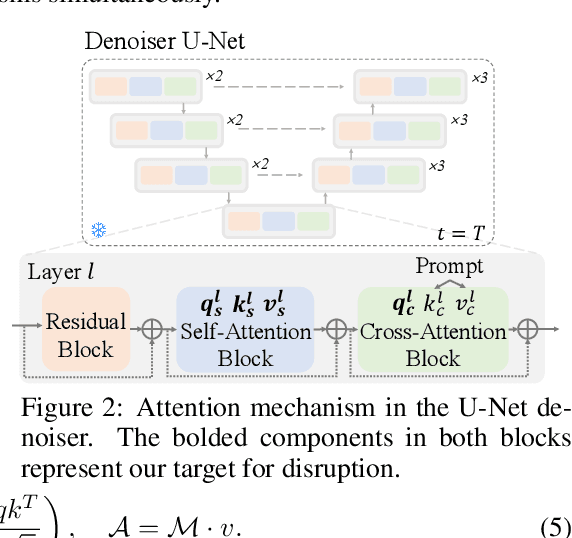

The outstanding capability of diffusion models in generating high-quality images poses significant threats when misused by adversaries. In particular, we assume malicious adversaries exploiting diffusion models for inpainting tasks, such as replacing a specific region with a celebrity. While existing methods for protecting images from manipulation in diffusion-based generative models have primarily focused on image-to-image and text-to-image tasks, the challenge of preventing unauthorized inpainting has been rarely addressed, often resulting in suboptimal protection performance. To mitigate inpainting abuses, we propose ADVPAINT, a novel defensive framework that generates adversarial perturbations that effectively disrupt the adversary's inpainting tasks. ADVPAINT targets the self- and cross-attention blocks in a target diffusion inpainting model to distract semantic understanding and prompt interactions during image generation. ADVPAINT also employs a two-stage perturbation strategy, dividing the perturbation region based on an enlarged bounding box around the object, enhancing robustness across diverse masks of varying shapes and sizes. Our experimental results demonstrate that ADVPAINT's perturbations are highly effective in disrupting the adversary's inpainting tasks, outperforming existing methods; ADVPAINT attains over a 100-point increase in FID and substantial decreases in precision.
Targeted Adversarial Self-Supervised Learning
Oct 19, 2022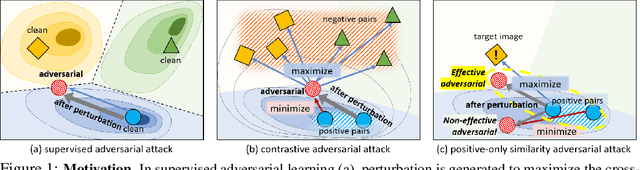
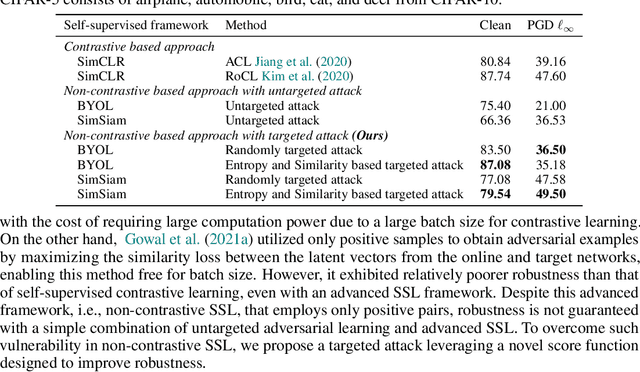
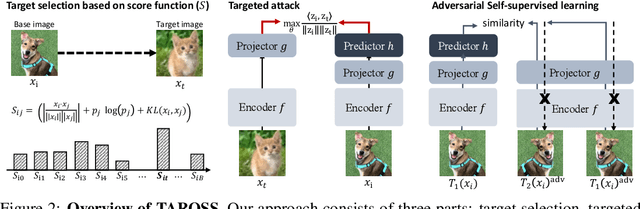

Recently, unsupervised adversarial training (AT) has been extensively studied to attain robustness with the models trained upon unlabeled data. To this end, previous studies have applied existing supervised adversarial training techniques to self-supervised learning (SSL) frameworks. However, all have resorted to untargeted adversarial learning as obtaining targeted adversarial examples is unclear in the SSL setting lacking of label information. In this paper, we propose a novel targeted adversarial training method for the SSL frameworks. Specifically, we propose a target selection algorithm for the adversarial SSL frameworks; it is designed to select the most confusing sample for each given instance based on similarity and entropy, and perturb the given instance toward the selected target sample. Our method significantly enhances the robustness of an SSL model without requiring large batches of images or additional models, unlike existing works aimed at achieving the same goal. Moreover, our method is readily applicable to general SSL frameworks that only uses positive pairs. We validate our method on benchmark datasets, on which it obtains superior robust accuracies, outperforming existing unsupervised adversarial training methods.
Evaluating the Robustness of Trigger Set-Based Watermarks Embedded in Deep Neural Networks
Jun 18, 2021

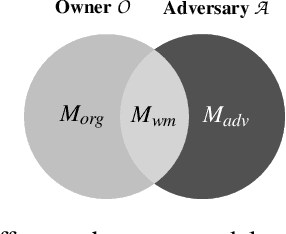
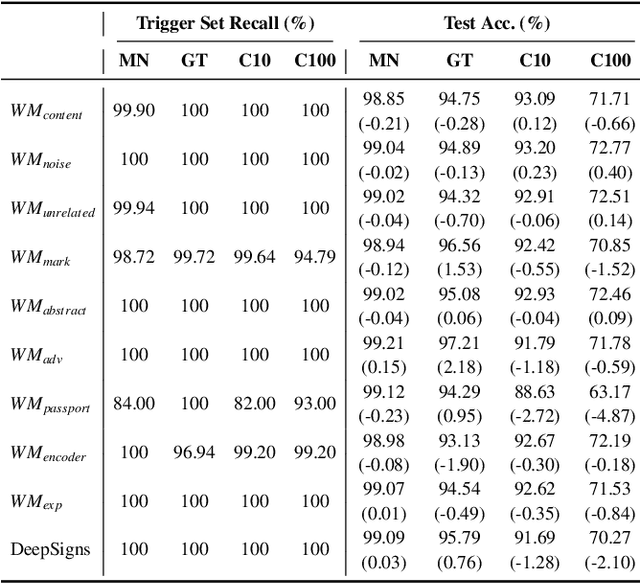
Trigger set-based watermarking schemes have gained emerging attention as they provide a means to prove ownership for deep neural network model owners. In this paper, we argue that state-of-the-art trigger set-based watermarking algorithms do not achieve their designed goal of proving ownership. We posit that this impaired capability stems from two common experimental flaws that the existing research practice has committed when evaluating the robustness of watermarking algorithms: (1) incomplete adversarial evaluation and (2) overlooked adaptive attacks. We conduct a comprehensive adversarial evaluation of 10 representative watermarking schemes against six of the existing attacks and demonstrate that each of these watermarking schemes lacks robustness against at least two attacks. We also propose novel adaptive attacks that harness the adversary's knowledge of the underlying watermarking algorithm of a target model. We demonstrate that the proposed attacks effectively break all of the 10 watermarking schemes, consequently allowing adversaries to obscure the ownership of any watermarked model. We encourage follow-up studies to consider our guidelines when evaluating the robustness of their watermarking schemes via conducting comprehensive adversarial evaluation that include our adaptive attacks to demonstrate a meaningful upper bound of watermark robustness.
Learning to Separate Clusters of Adversarial Representations for Robust Adversarial Detection
Dec 07, 2020
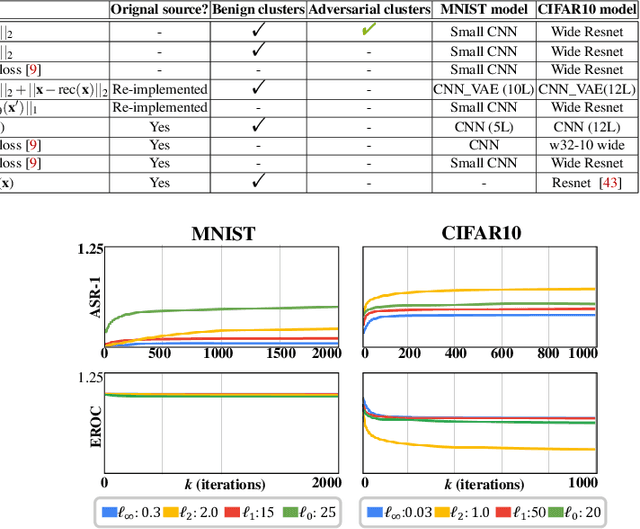
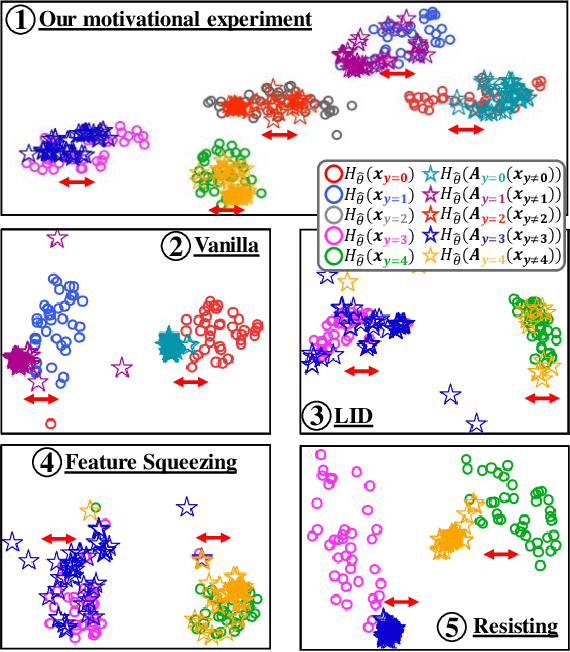
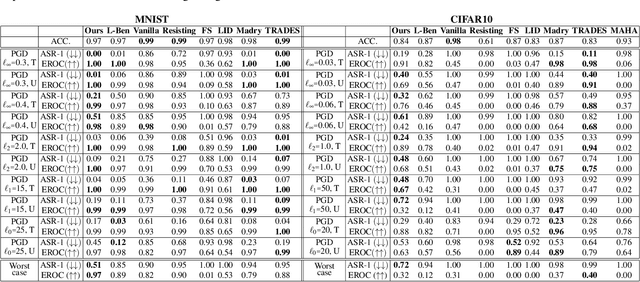
Although deep neural networks have shown promising performances on various tasks, they are susceptible to incorrect predictions induced by imperceptibly small perturbations in inputs. A large number of previous works proposed to detect adversarial attacks. Yet, most of them cannot effectively detect them against adaptive whitebox attacks where an adversary has the knowledge of the model and the defense method. In this paper, we propose a new probabilistic adversarial detector motivated by a recently introduced non-robust feature. We consider the non-robust features as a common property of adversarial examples, and we deduce it is possible to find a cluster in representation space corresponding to the property. This idea leads us to probability estimate distribution of adversarial representations in a separate cluster, and leverage the distribution for a likelihood based adversarial detector.
Montage: A Neural Network Language Model-Guided JavaScript Engine Fuzzer
Jan 14, 2020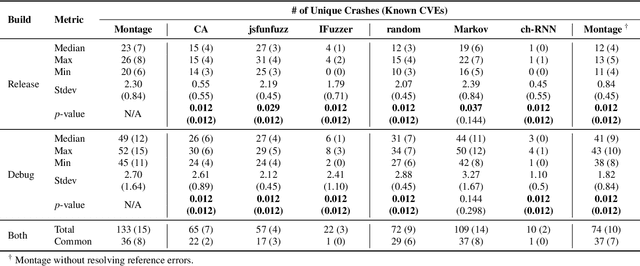
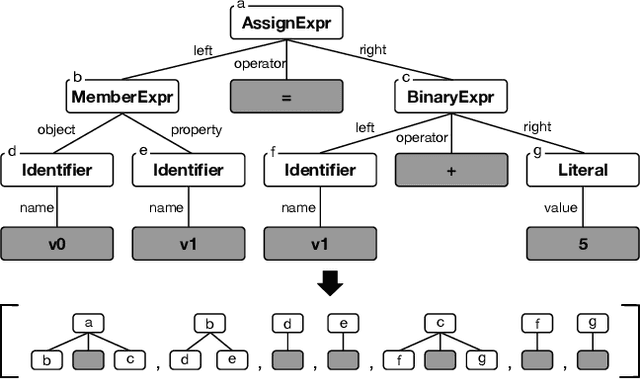
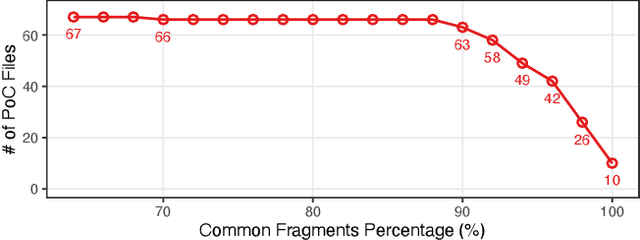
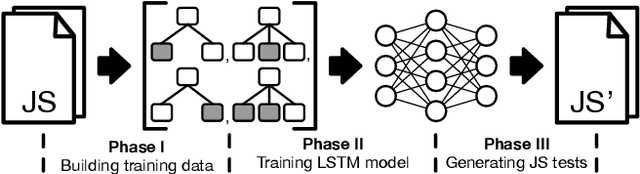
JavaScript (JS) engine vulnerabilities pose significant security threats affecting billions of web browsers. While fuzzing is a prevalent technique for finding such vulnerabilities, there have been few studies that leverage the recent advances in neural network language models (NNLMs). In this paper, we present Montage, the first NNLM-guided fuzzer for finding JS engine vulnerabilities. The key aspect of our technique is to transform a JS abstract syntax tree (AST) into a sequence of AST subtrees that can directly train prevailing NNLMs. We demonstrate that Montage is capable of generating valid JS tests, and show that it outperforms previous studies in terms of finding vulnerabilities. Montage found 37 real-world bugs, including three CVEs, in the latest JS engines, demonstrating its efficacy in finding JS engine bugs.