 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning with Electronic Health Records is vulnerable to Backdoor Trigger Attacks
Jun 15, 2021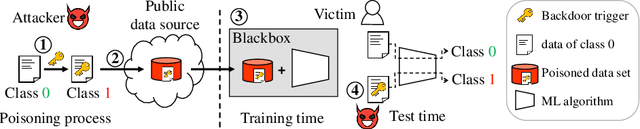
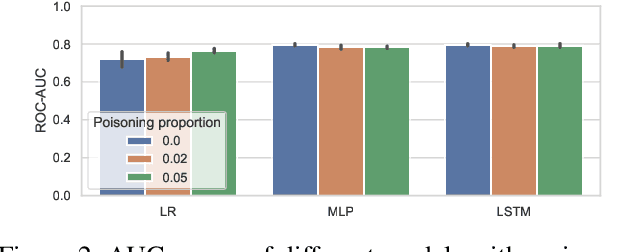
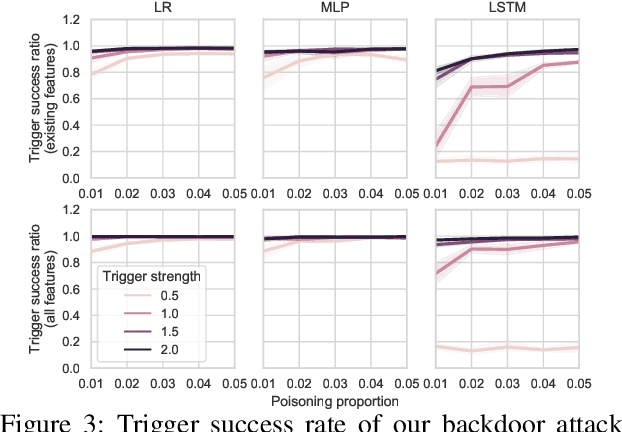
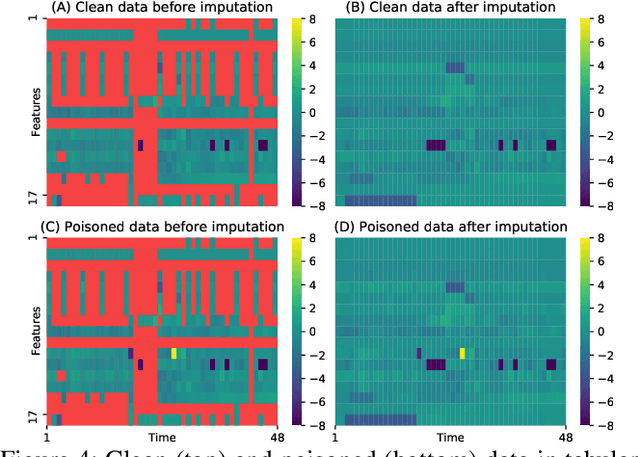
Electronic Health Records (EHRs) provide a wealth of information for machine learning algorithms to predict the patient outcome from the data including diagnostic information, vital signals, lab tests, drug administration, and demographic information. Machine learning models can be built, for example, to evaluate patients based on their predicted mortality or morbidity and to predict required resources for efficient resource management in hospitals. In this paper, we demonstrate that an attacker can manipulate the machine learning predictions with EHRs easily and selectively at test time by backdoor attacks with the poisoned training data. Furthermore, the poison we create has statistically similar features to the original data making it hard to detect, and can also attack multiple machine learning models without any knowledge of the models. With less than 5% of the raw EHR data poisoned, we achieve average attack success rates of 97% on mortality prediction tasks with MIMIC-III database against Logistic Regression, Multilayer Perceptron, and Long Short-term Memory models simultaneously.
Learning to Separate Clusters of Adversarial Representations for Robust Adversarial Detection
Dec 07, 2020
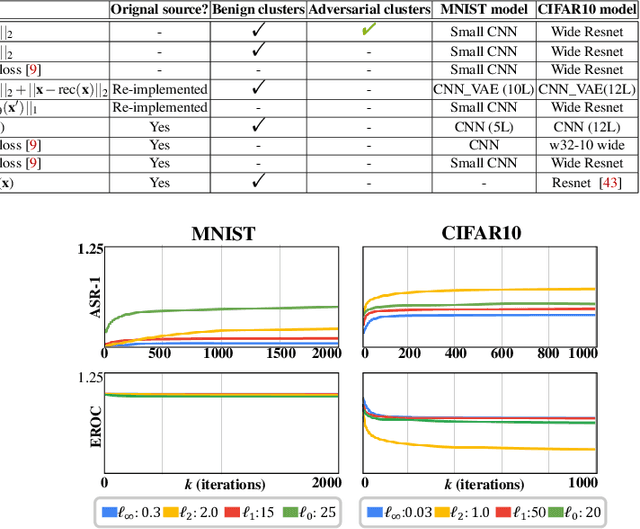
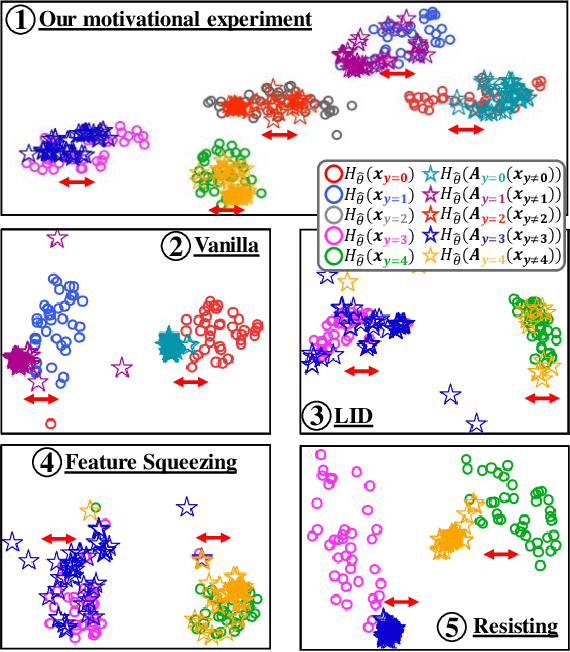
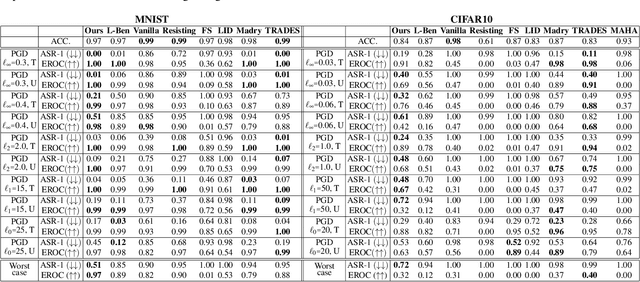
Although deep neural networks have shown promising performances on various tasks, they are susceptible to incorrect predictions induced by imperceptibly small perturbations in inputs. A large number of previous works proposed to detect adversarial attacks. Yet, most of them cannot effectively detect them against adaptive whitebox attacks where an adversary has the knowledge of the model and the defense method. In this paper, we propose a new probabilistic adversarial detector motivated by a recently introduced non-robust feature. We consider the non-robust features as a common property of adversarial examples, and we deduce it is possible to find a cluster in representation space corresponding to the property. This idea leads us to probability estimate distribution of adversarial representations in a separate cluster, and leverage the distribution for a likelihood based adversarial detector.
Learning to Disentangle Robust and Vulnerable Features for Adversarial Detection
Sep 10, 2019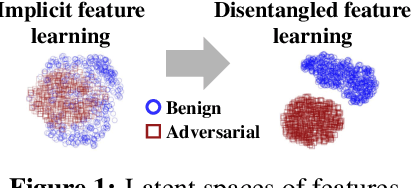


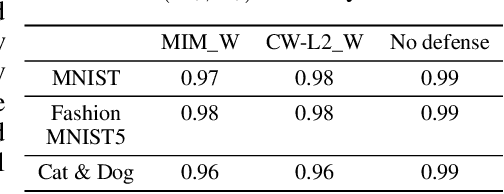
Although deep neural networks have shown promising performances on various tasks, even achieving human-level performance on some, they are shown to be susceptible to incorrect predictions even with imperceptibly small perturbations to an input. There exists a large number of previous works which proposed to defend against such adversarial attacks either by robust inference or detection of adversarial inputs. Yet, most of them cannot effectively defend against whitebox attacks where an adversary has a knowledge of the model and defense. More importantly, they do not provide a convincing reason why the generated adversarial inputs successfully fool the target models. To address these shortcomings of the existing approaches, we hypothesize that the adversarial inputs are tied to latent features that are susceptible to adversarial perturbation, which we call vulnerable features. Then based on this intuition, we propose a minimax game formulation to disentangle the latent features of each instance into robust and vulnerable ones, using variational autoencoders with two latent spaces. We thoroughly validate our model for both blackbox and whitebox attacks on MNIST, Fashion MNIST5, and Cat & Dog datasets, whose results show that the adversarial inputs cannot bypass our detector without changing its semantics, in which case the attack has failed.