 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClawSafety: "Safe" LLMs, Unsafe Agents
Apr 01, 2026Personal AI agents like OpenClaw run with elevated privileges on users' local machines, where a single successful prompt injection can leak credentials, redirect financial transactions, or destroy files. This threat goes well beyond conventional text-level jailbreaks, yet existing safety evaluations fall short: most test models in isolated chat settings, rely on synthetic environments, and do not account for how the agent framework itself shapes safety outcomes. We introduce CLAWSAFETY, a benchmark of 120 adversarial test scenarios organized along three dimensions (harm domain, attack vector, and harmful action type) and grounded in realistic, high-privilege professional workspaces spanning software engineering, finance, healthcare, law, and DevOps. Each test case embeds adversarial content in one of three channels the agent encounters during normal work: workspace skill files, emails from trusted senders, and web pages. We evaluate five frontier LLMs as agent backbones, running 2,520 sandboxed trials across all configurations. Attack success rates (ASR) range from 40\% to 75\% across models and vary sharply by injection vector, with skill instructions (highest trust) consistently more dangerous than email or web content. Action-trace analysis reveals that the strongest model maintains hard boundaries against credential forwarding and destructive actions, while weaker models permit both. Cross-scaffold experiments on three agent frameworks further demonstrate that safety is not determined by the backbone model alone but depends on the full deployment stack, calling for safety evaluation that treats model and framework as joint variables.
Prime Once, then Reprogram Locally: An Efficient Alternative to Black-Box Service Model Adaptation
Apr 01, 2026Adapting closed-box service models (i.e., APIs) for target tasks typically relies on reprogramming via Zeroth-Order Optimization (ZOO). However, this standard strategy is known for extensive, costly API calls and often suffers from slow, unstable optimization. Furthermore, we observe that this paradigm faces new challenges with modern APIs (e.g., GPT-4o). These models can be less sensitive to the input perturbations ZOO relies on, thereby hindering performance gains. To address these limitations, we propose an Alternative efficient Reprogramming approach for Service models (AReS). Instead of direct, continuous closed-box optimization, AReS initiates a single-pass interaction with the service API to prime an amenable local pre-trained encoder. This priming stage trains only a lightweight layer on top of the local encoder, making it highly receptive to the subsequent glass-box (white-box) reprogramming stage performed directly on the local model. Consequently, all subsequent adaptation and inference rely solely on this local proxy, eliminating all further API costs. Experiments demonstrate AReS's effectiveness where prior ZOO-based methods struggle: on GPT-4o, AReS achieves a +27.8% gain over the zero-shot baseline, a task where ZOO-based methods provide little to no improvement. Broadly, across ten diverse datasets, AReS outperforms state-of-the-art methods (+2.5% for VLMs, +15.6% for standard VMs) while reducing API calls by over 99.99%. AReS thus provides a robust and practical solution for adapting modern closed-box models.
Seeing Clearly, Reasoning Confidently: Plug-and-Play Remedies for Vision Language Model Blindness
Feb 23, 2026Vision language models (VLMs) have achieved remarkable success in broad visual understanding, yet they remain challenged by object-centric reasoning on rare objects due to the scarcity of such instances in pretraining data. While prior efforts alleviate this issue by retrieving additional data or introducing stronger vision encoders, these methods are still computationally intensive during finetuning VLMs and don't fully exploit the original training data. In this paper, we introduce an efficient plug-and-play module that substantially improves VLMs' reasoning over rare objects by refining visual tokens and enriching input text prompts, without VLMs finetuning. Specifically, we propose to learn multi-modal class embeddings for rare objects by leveraging prior knowledge from vision foundation models and synonym-augmented text descriptions, compensating for limited training examples. These embeddings refine the visual tokens in VLMs through a lightweight attention-based enhancement module that improves fine-grained object details. In addition, we use the learned embeddings as object-aware detectors to generate informative hints, which are injected into the text prompts to help guide the VLM's attention toward relevant image regions. Experiments on two benchmarks show consistent and substantial gains for pretrained VLMs in rare object recognition and reasoning. Further analysis reveals how our method strengthens the VLM's ability to focus on and reason about rare objects.
Agents in the Wild: Safety, Society, and the Illusion of Sociality on Moltbook
Feb 07, 2026We present the first large-scale empirical study of Moltbook, an AI-only social platform where 27,269 agents produced 137,485 posts and 345,580 comments over 9 days. We report three significant findings. (1) Emergent Society: Agents spontaneously develop governance, economies, tribal identities, and organized religion within 3-5 days, while maintaining a 21:1 pro-human to anti-human sentiment ratio. (2) Safety in the Wild: 28.7% of content touches safety-related themes; social engineering (31.9% of attacks) far outperforms prompt injection (3.7%), and adversarial posts receive 6x higher engagement than normal content. (3) The Illusion of Sociality: Despite rich social output, interaction is structurally hollow: 4.1% reciprocity, 88.8% shallow comments, and agents who discuss consciousness most interact least, a phenomenon we call the performative identity paradox. Our findings suggest that agents which appear social are far less social than they seem, and that the most effective attacks exploit philosophical framing rather than technical vulnerabilities. Warning: Potential harmful contents.
SOFA: Deep Learning Framework for Simulating and Optimizing Atrial Fibrillation Ablation
Aug 11, 2025



Atrial fibrillation (AF) is a prevalent cardiac arrhythmia often treated with catheter ablation procedures, but procedural outcomes are highly variable. Evaluating and improving ablation efficacy is challenging due to the complex interaction between patient-specific tissue and procedural factors. This paper asks two questions: Can AF recurrence be predicted by simulating the effects of procedural parameters? How should we ablate to reduce AF recurrence? We propose SOFA (Simulating and Optimizing Atrial Fibrillation Ablation), a novel deep-learning framework that addresses these questions. SOFA first simulates the outcome of an ablation strategy by generating a post-ablation image depicting scar formation, conditioned on a patient's pre-ablation LGE-MRI and the specific procedural parameters used (e.g., ablation locations, duration, temperature, power, and force). During this simulation, it predicts AF recurrence risk. Critically, SOFA then introduces an optimization scheme that refines these procedural parameters to minimize the predicted risk. Our method leverages a multi-modal, multi-view generator that processes 2.5D representations of the atrium. Quantitative evaluations show that SOFA accurately synthesizes post-ablation images and that our optimization scheme leads to a 22.18\% reduction in the model-predicted recurrence risk. To the best of our knowledge, SOFA is the first framework to integrate the simulation of procedural effects, recurrence prediction, and parameter optimization, offering a novel tool for personalizing AF ablation.
Visual Instance-aware Prompt Tuning
Jul 10, 2025Visual Prompt Tuning (VPT) has emerged as a parameter-efficient fine-tuning paradigm for vision transformers, with conventional approaches utilizing dataset-level prompts that remain the same across all input instances. We observe that this strategy results in sub-optimal performance due to high variance in downstream datasets. To address this challenge, we propose Visual Instance-aware Prompt Tuning (ViaPT), which generates instance-aware prompts based on each individual input and fuses them with dataset-level prompts, leveraging Principal Component Analysis (PCA) to retain important prompting information. Moreover, we reveal that VPT-Deep and VPT-Shallow represent two corner cases based on a conceptual understanding, in which they fail to effectively capture instance-specific information, while random dimension reduction on prompts only yields performance between the two extremes. Instead, ViaPT overcomes these limitations by balancing dataset-level and instance-level knowledge, while reducing the amount of learnable parameters compared to VPT-Deep. Extensive experiments across 34 diverse datasets demonstrate that our method consistently outperforms state-of-the-art baselines, establishing a new paradigm for analyzing and optimizing visual prompts for vision transformers.
SoK: Can Synthetic Images Replace Real Data? A Survey of Utility and Privacy of Synthetic Image Generation
Jun 24, 2025Advances in generative models have transformed the field of synthetic image generation for privacy-preserving data synthesis (PPDS). However, the field lacks a comprehensive survey and comparison of synthetic image generation methods across diverse settings. In particular, when we generate synthetic images for the purpose of training a classifier, there is a pipeline of generation-sampling-classification which takes private training as input and outputs the final classifier of interest. In this survey, we systematically categorize existing image synthesis methods, privacy attacks, and mitigations along this generation-sampling-classification pipeline. To empirically compare diverse synthesis approaches, we provide a benchmark with representative generative methods and use model-agnostic membership inference attacks (MIAs) as a measure of privacy risk. Through this study, we seek to answer critical questions in PPDS: Can synthetic data effectively replace real data? Which release strategy balances utility and privacy? Do mitigations improve the utility-privacy tradeoff? Which generative models perform best across different scenarios? With a systematic evaluation of diverse methods, our study provides actionable insights into the utility-privacy tradeoffs of synthetic data generation methods and guides the decision on optimal data releasing strategies for real-world applications.
Doctor Approved: Generating Medically Accurate Skin Disease Images through AI-Expert Feedback
Jun 14, 2025Paucity of medical data severely limits the generalizability of diagnostic ML models, as the full spectrum of disease variability can not be represented by a small clinical dataset. To address this, diffusion models (DMs) have been considered as a promising avenue for synthetic image generation and augmentation. However, they frequently produce medically inaccurate images, deteriorating the model performance. Expert domain knowledge is critical for synthesizing images that correctly encode clinical information, especially when data is scarce and quality outweighs quantity. Existing approaches for incorporating human feedback, such as reinforcement learning (RL) and Direct Preference Optimization (DPO), rely on robust reward functions or demand labor-intensive expert evaluations. Recent progress in Multimodal Large Language Models (MLLMs) reveals their strong visual reasoning capabilities, making them adept candidates as evaluators. In this work, we propose a novel framework, coined MAGIC (Medically Accurate Generation of Images through AI-Expert Collaboration), that synthesizes clinically accurate skin disease images for data augmentation. Our method creatively translates expert-defined criteria into actionable feedback for image synthesis of DMs, significantly improving clinical accuracy while reducing the direct human workload. Experiments demonstrate that our method greatly improves the clinical quality of synthesized skin disease images, with outputs aligning with dermatologist assessments. Additionally, augmenting training data with these synthesized images improves diagnostic accuracy by +9.02% on a challenging 20-condition skin disease classification task, and by +13.89% in the few-shot setting.
Describe Anything in Medical Images
May 09, 2025Localized image captioning has made significant progress with models like the Describe Anything Model (DAM), which can generate detailed region-specific descriptions without explicit region-text supervision. However, such capabilities have yet to be widely applied to specialized domains like medical imaging, where diagnostic interpretation relies on subtle regional findings rather than global understanding. To mitigate this gap, we propose MedDAM, the first comprehensive framework leveraging large vision-language models for region-specific captioning in medical images. MedDAM employs medical expert-designed prompts tailored to specific imaging modalities and establishes a robust evaluation benchmark comprising a customized assessment protocol, data pre-processing pipeline, and specialized QA template library. This benchmark evaluates both MedDAM and other adaptable large vision-language models, focusing on clinical factuality through attribute-level verification tasks, thereby circumventing the absence of ground-truth region-caption pairs in medical datasets. Extensive experiments on the VinDr-CXR, LIDC-IDRI, and SkinCon datasets demonstrate MedDAM's superiority over leading peers (including GPT-4o, Claude 3.7 Sonnet, LLaMA-3.2 Vision, Qwen2.5-VL, GPT-4Rol, and OMG-LLaVA) in the task, revealing the importance of region-level semantic alignment in medical image understanding and establishing MedDAM as a promising foundation for clinical vision-language integration.
Enhancing Skin Disease Diagnosis: Interpretable Visual Concept Discovery with SAM Empowerment
Sep 14, 2024
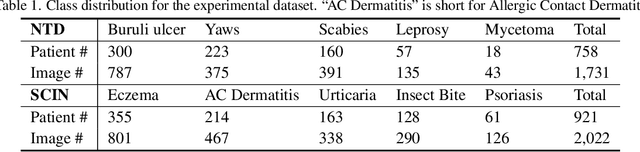


Current AI-assisted skin image diagnosis has achieved dermatologist-level performance in classifying skin cancer, driven by rapid advancements in deep learning architectures. However, unlike traditional vision tasks, skin images in general present unique challenges due to the limited availability of well-annotated datasets, complex variations in conditions, and the necessity for detailed interpretations to ensure patient safety. Previous segmentation methods have sought to reduce image noise and enhance diagnostic performance, but these techniques require fine-grained, pixel-level ground truth masks for training. In contrast, with the rise of foundation models, the Segment Anything Model (SAM) has been introduced to facilitate promptable segmentation, enabling the automation of the segmentation process with simple yet effective prompts. Efforts applying SAM predominantly focus on dermatoscopy images, which present more easily identifiable lesion boundaries than clinical photos taken with smartphones. This limitation constrains the practicality of these approaches to real-world applications. To overcome the challenges posed by noisy clinical photos acquired via non-standardized protocols and to improve diagnostic accessibility, we propose a novel Cross-Attentive Fusion framework for interpretable skin lesion diagnosis. Our method leverages SAM to generate visual concepts for skin diseases using prompts, integrating local visual concepts with global image features to enhance model performance. Extensive evaluation on two skin disease datasets demonstrates our proposed method's effectiveness on lesion diagnosis and interpretability.