 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPAR: Dynamic Patchification for Efficient Autoregressive Visual Generation
Dec 26, 2025Decoder-only autoregressive image generation typically relies on fixed-length tokenization schemes whose token counts grow quadratically with resolution, substantially increasing the computational and memory demands of attention. We present DPAR, a novel decoder-only autoregressive model that dynamically aggregates image tokens into a variable number of patches for efficient image generation. Our work is the first to demonstrate that next-token prediction entropy from a lightweight and unsupervised autoregressive model provides a reliable criterion for merging tokens into larger patches based on information content. DPAR makes minimal modifications to the standard decoder architecture, ensuring compatibility with multimodal generation frameworks and allocating more compute to generation of high-information image regions. Further, we demonstrate that training with dynamically sized patches yields representations that are robust to patch boundaries, allowing DPAR to scale to larger patch sizes at inference. DPAR reduces token count by 1.81x and 2.06x on Imagenet 256 and 384 generation resolution respectively, leading to a reduction of up to 40% FLOPs in training costs. Further, our method exhibits faster convergence and improves FID by up to 27.1% relative to baseline models.
Measuring Time-Series Dataset Similarity using Wasserstein Distance
Jul 29, 2025



The emergence of time-series foundation model research elevates the growing need to measure the (dis)similarity of time-series datasets. A time-series dataset similarity measure aids research in multiple ways, including model selection, finetuning, and visualization. In this paper, we propose a distribution-based method to measure time-series dataset similarity by leveraging the Wasserstein distance. We consider a time-series dataset an empirical instantiation of an underlying multivariate normal distribution (MVN). The similarity between two time-series datasets is thus computed as the Wasserstein distance between their corresponding MVNs. Comprehensive experiments and visualization show the effectiveness of our approach. Specifically, we show how the Wasserstein distance helps identify similar time-series datasets and facilitates inference performance estimation of foundation models in both out-of-distribution and transfer learning evaluation, with high correlations between our proposed measure and the inference loss (>0.60).
Model-agnostic Coreset Selection via LLM-based Concept Bottlenecks
Feb 23, 2025



Coreset Selection (CS) identifies a subset of training data that achieves model performance comparable to using the entire dataset. Many state-of-the-art CS methods, select coresets using scores whose computation requires training the downstream model on the entire dataset and recording changes in its behavior on samples as it trains (training dynamics). These scores are inefficient to compute and hard to interpret as they do not indicate whether a sample is difficult to learn in general or only for a specific model. Our work addresses these challenges by proposing an interpretable score that gauges a sample's difficulty using human-understandable textual attributes (concepts) independent of any downstream model. Specifically, we measure the alignment between a sample's visual features and concept bottlenecks, derived via large language models, by training a linear concept bottleneck layer and compute the sample's difficulty score using it. We then use this score and a stratified sampling strategy to identify the coreset. Crucially, our score is efficiently computable without training the downstream model on the full dataset even once, leads to high-performing coresets for various downstream models, and is computable even for an unlabeled dataset. Through experiments on CIFAR-10, CIFAR-100, and ImageNet-1K, we show our coresets outperform random subsets, even at high pruning rates, and achieve model performance comparable to or better than coresets found by training dynamics-based methods.
Dynamic Domains, Dynamic Solutions: DPCore for Continual Test-Time Adaptation
Jun 15, 2024



Continual Test-Time Adaptation (TTA) seeks to adapt a source pre-trained model to continually changing, unlabeled target domains. Existing TTA methods are typically designed for environments where domain changes occur gradually and can struggle in more dynamic scenarios. Inspired by the principles of online K-Means, this paper introduces a novel approach to continual TTA through visual prompting. We propose a Dynamic Prompt Coreset that not only preserves knowledge from previously visited domains but also accommodates learning from new potential domains. This is complemented by a distance-based weight updating mechanism that ensures the coreset remains current and relevant. Our approach employs a fixed model architecture alongside the coreset and an innovative updating system to effectively mitigate challenges such as catastrophic forgetting and error accumulation. Extensive testing across various benchmarks-including ImageNet-C, CIFAR100-C, and CIFAR10-C-demonstrates that our method consistently outperforms state-of-the-art (SOTA) alternatives, particularly excelling in dynamically changing environments.
Test-time Assessment of a Model's Performance on Unseen Domains via Optimal Transport
May 02, 2024



Gauging the performance of ML models on data from unseen domains at test-time is essential yet a challenging problem due to the lack of labels in this setting. Moreover, the performance of these models on in-distribution data is a poor indicator of their performance on data from unseen domains. Thus, it is essential to develop metrics that can provide insights into the model's performance at test time and can be computed only with the information available at test time (such as their model parameters, the training data or its statistics, and the unlabeled test data). To this end, we propose a metric based on Optimal Transport that is highly correlated with the model's performance on unseen domains and is efficiently computable only using information available at test time. Concretely, our metric characterizes the model's performance on unseen domains using only a small amount of unlabeled data from these domains and data or statistics from the training (source) domain(s). Through extensive empirical evaluation using standard benchmark datasets, and their corruptions, we demonstrate the utility of our metric in estimating the model's performance in various practical applications. These include the problems of selecting the source data and architecture that leads to the best performance on data from an unseen domain and the problem of predicting a deployed model's performance at test time on unseen domains. Our empirical results show that our metric, which uses information from both the source and the unseen domain, is highly correlated with the model's performance, achieving a significantly better correlation than that obtained via the popular prediction entropy-based metric, which is computed solely using the data from the unseen domain.
On the Fly Neural Style Smoothing for Risk-Averse Domain Generalization
Jul 17, 2023



Achieving high accuracy on data from domains unseen during training is a fundamental challenge in domain generalization (DG). While state-of-the-art DG classifiers have demonstrated impressive performance across various tasks, they have shown a bias towards domain-dependent information, such as image styles, rather than domain-invariant information, such as image content. This bias renders them unreliable for deployment in risk-sensitive scenarios such as autonomous driving where a misclassification could lead to catastrophic consequences. To enable risk-averse predictions from a DG classifier, we propose a novel inference procedure, Test-Time Neural Style Smoothing (TT-NSS), that uses a "style-smoothed" version of the DG classifier for prediction at test time. Specifically, the style-smoothed classifier classifies a test image as the most probable class predicted by the DG classifier on random re-stylizations of the test image. TT-NSS uses a neural style transfer module to stylize a test image on the fly, requires only black-box access to the DG classifier, and crucially, abstains when predictions of the DG classifier on the stylized test images lack consensus. Additionally, we propose a neural style smoothing (NSS) based training procedure that can be seamlessly integrated with existing DG methods. This procedure enhances prediction consistency, improving the performance of TT-NSS on non-abstained samples. Our empirical results demonstrate the effectiveness of TT-NSS and NSS at producing and improving risk-averse predictions on unseen domains from DG classifiers trained with SOTA training methods on various benchmark datasets and their variations.
Analysis of Task Transferability in Large Pre-trained Classifiers
Jul 03, 2023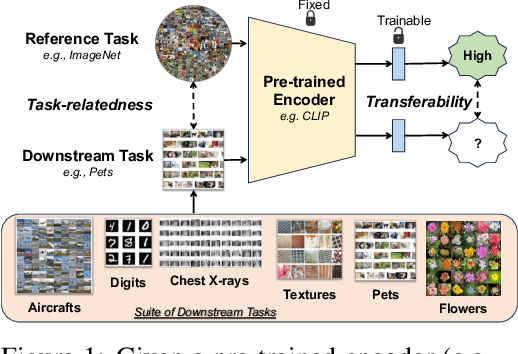

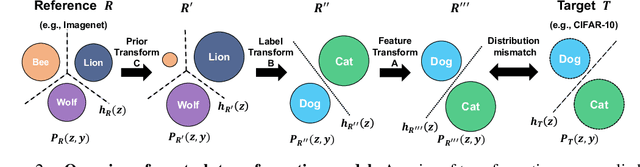
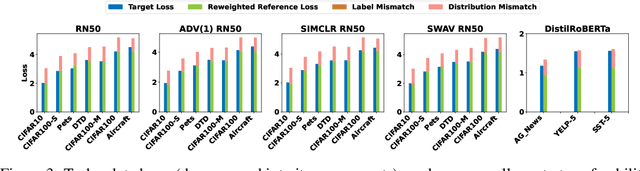
Transfer learning transfers the knowledge acquired by a model from a source task to multiple downstream target tasks with minimal fine-tuning. The success of transfer learning at improving performance, especially with the use of large pre-trained models has made transfer learning an essential tool in the machine learning toolbox. However, the conditions under which the performance is transferable to downstream tasks are not understood very well. In this work, we analyze the transfer of performance for classification tasks, when only the last linear layer of the source model is fine-tuned on the target task. We propose a novel Task Transfer Analysis approach that transforms the source distribution (and classifier) by changing the class prior distribution, label, and feature spaces to produce a new source distribution (and classifier) and allows us to relate the loss of the downstream task (i.e., transferability) to that of the source task. Concretely, our bound explains transferability in terms of the Wasserstein distance between the transformed source and downstream task's distribution, conditional entropy between the label distributions of the two tasks, and weighted loss of the source classifier on the source task. Moreover, we propose an optimization problem for learning the transforms of the source task to minimize the upper bound on transferability. We perform a large-scale empirical study by using state-of-the-art pre-trained models and demonstrate the effectiveness of our bound and optimization at predicting transferability. The results of our experiments demonstrate how factors such as task relatedness, pretraining method, and model architecture affect transferability.
Understanding the Robustness of Multi-Exit Models under Common Corruptions
Dec 03, 2022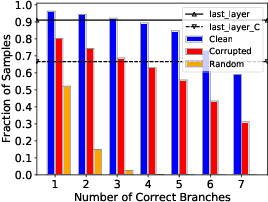
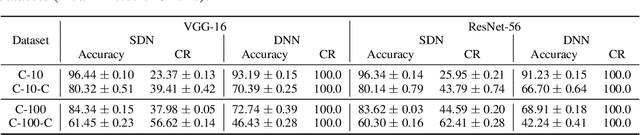
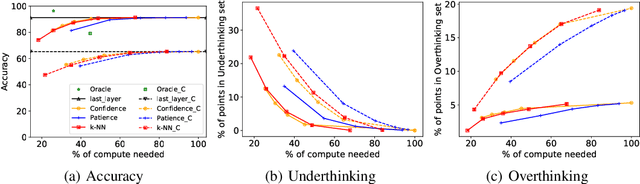
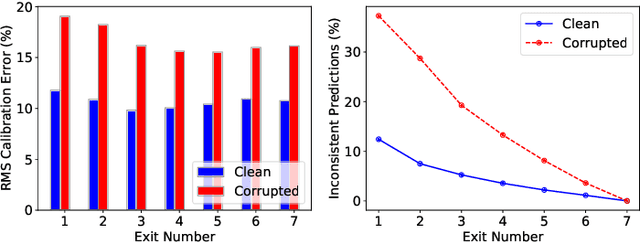
Multi-Exit models (MEMs) use an early-exit strategy to improve the accuracy and efficiency of deep neural networks (DNNs) by allowing samples to exit the network before the last layer. However, the effectiveness of MEMs in the presence of distribution shifts remains largely unexplored. Our work examines how distribution shifts generated by common image corruptions affect the accuracy/efficiency of MEMs. We find that under common corruptions, early-exiting at the first correct exit reduces the inference cost and provides a significant boost in accuracy ( 10%) over exiting at the last layer. However, with realistic early-exit strategies, which do not assume knowledge about the correct exits, MEMs still reduce inference cost but provide a marginal improvement in accuracy (1%) compared to exiting at the last layer. Moreover, the presence of distribution shift widens the gap between an MEM's maximum classification accuracy and realistic early-exit strategies by 5% on average compared with the gap on in-distribution data. Our empirical analysis shows that the lack of calibration due to a distribution shift increases the susceptibility of such early-exit strategies to exit early and increases misclassification rates. Furthermore, the lack of calibration increases the inconsistency in the predictions of the model across exits, leading to both inefficient inference and more misclassifications compared with evaluation on in-distribution data. Finally, we propose two metrics, underthinking and overthinking, that quantify the different behavior of practical early-exit strategy under distribution shifts, and provide insights into improving the practical utility of MEMs.
On Certifying and Improving Generalization to Unseen Domains
Jun 24, 2022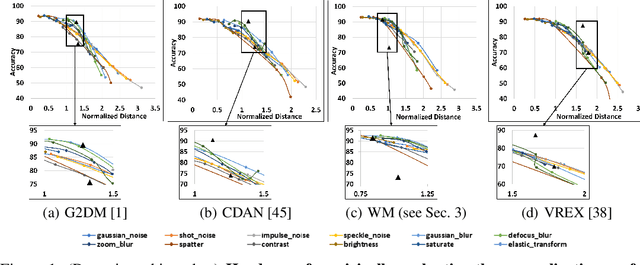
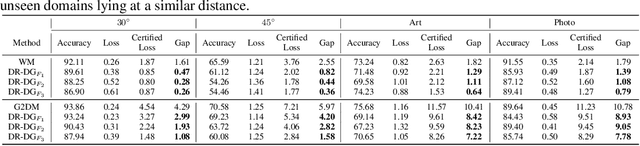


Domain Generalization (DG) aims to learn models whose performance remains high on unseen domains encountered at test-time by using data from multiple related source domains. Many existing DG algorithms reduce the divergence between source distributions in a representation space to potentially align the unseen domain close to the sources. This is motivated by the analysis that explains generalization to unseen domains using distributional distance (such as the Wasserstein distance) to the sources. However, due to the openness of the DG objective, it is challenging to evaluate DG algorithms comprehensively using a few benchmark datasets. In particular, we demonstrate that the accuracy of the models trained with DG methods varies significantly across unseen domains, generated from popular benchmark datasets. This highlights that the performance of DG methods on a few benchmark datasets may not be representative of their performance on unseen domains in the wild. To overcome this roadblock, we propose a universal certification framework based on distributionally robust optimization (DRO) that can efficiently certify the worst-case performance of any DG method. This enables a data-independent evaluation of a DG method complementary to the empirical evaluations on benchmark datasets. Furthermore, we propose a training algorithm that can be used with any DG method to provably improve their certified performance. Our empirical evaluation demonstrates the effectiveness of our method at significantly improving the worst-case loss (i.e., reducing the risk of failure of these models in the wild) without incurring a significant performance drop on benchmark datasets.
Certified Adversarial Defenses Meet Out-of-Distribution Corruptions: Benchmarking Robustness and Simple Baselines
Dec 01, 2021

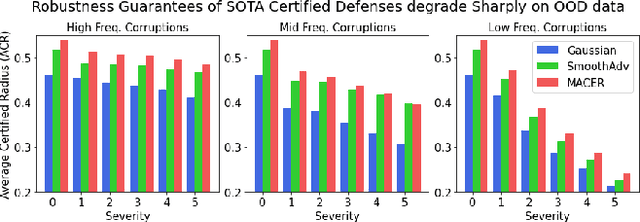

Certified robustness guarantee gauges a model's robustness to test-time attacks and can assess the model's readiness for deployment in the real world. In this work, we critically examine how the adversarial robustness guarantees from randomized smoothing-based certification methods change when state-of-the-art certifiably robust models encounter out-of-distribution (OOD) data. Our analysis demonstrates a previously unknown vulnerability of these models to low-frequency OOD data such as weather-related corruptions, rendering these models unfit for deployment in the wild. To alleviate this issue, we propose a novel data augmentation scheme, FourierMix, that produces augmentations to improve the spectral coverage of the training data. Furthermore, we propose a new regularizer that encourages consistent predictions on noise perturbations of the augmented data to improve the quality of the smoothed models. We find that FourierMix augmentations help eliminate the spectral bias of certifiably robust models enabling them to achieve significantly better robustness guarantees on a range of OOD benchmarks. Our evaluation also uncovers the inability of current OOD benchmarks at highlighting the spectral biases of the models. To this end, we propose a comprehensive benchmarking suite that contains corruptions from different regions in the spectral domain. Evaluation of models trained with popular augmentation methods on the proposed suite highlights their spectral biases and establishes the superiority of FourierMix trained models at achieving better-certified robustness guarantees under OOD shifts over the entire frequency spectrum.