 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Task Transferability in Large Pre-trained Classifiers
Paper and Code
Jul 03, 2023

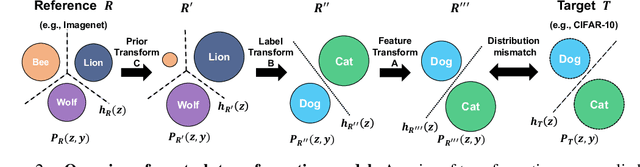
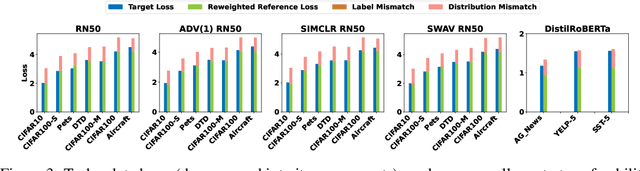
Transfer learning transfers the knowledge acquired by a model from a source task to multiple downstream target tasks with minimal fine-tuning. The success of transfer learning at improving performance, especially with the use of large pre-trained models has made transfer learning an essential tool in the machine learning toolbox. However, the conditions under which the performance is transferable to downstream tasks are not understood very well. In this work, we analyze the transfer of performance for classification tasks, when only the last linear layer of the source model is fine-tuned on the target task. We propose a novel Task Transfer Analysis approach that transforms the source distribution (and classifier) by changing the class prior distribution, label, and feature spaces to produce a new source distribution (and classifier) and allows us to relate the loss of the downstream task (i.e., transferability) to that of the source task. Concretely, our bound explains transferability in terms of the Wasserstein distance between the transformed source and downstream task's distribution, conditional entropy between the label distributions of the two tasks, and weighted loss of the source classifier on the source task. Moreover, we propose an optimization problem for learning the transforms of the source task to minimize the upper bound on transferability. We perform a large-scale empirical study by using state-of-the-art pre-trained models and demonstrate the effectiveness of our bound and optimization at predicting transferability. The results of our experiments demonstrate how factors such as task relatedness, pretraining method, and model architecture affect transferability.