 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Does It Look There? Structured Explanations for Image Classification
Mar 10, 2026Deep learning models achieve remarkable predictive performance, yet their black-box nature limits transparency and trustworthiness. Although numerous explainable artificial intelligence (XAI) methods have been proposed, they primarily provide saliency maps or concepts (i.e., unstructured interpretability). Existing approaches often rely on auxiliary models (\eg, GPT, CLIP) to describe model behavior, thereby compromising faithfulness to the original models. We propose Interpretability to Explainability (I2X), a framework that builds structured explanations directly from unstructured interpretability by quantifying progress at selected checkpoints during training using prototypes extracted from post-hoc XAI methods (e.g., GradCAM). I2X answers the question of "why does it look there" by providing a structured view of both intra- and inter-class decision making during training. Experiments on MNIST and CIFAR10 demonstrate effectiveness of I2X to reveal prototype-based inference process of various image classification models. Moreover, we demonstrate that I2X can be used to improve predictions across different model architectures and datasets: we can identify uncertain prototypes recognized by I2X and then use targeted perturbation of samples that allows fine-tuning to ultimately improve accuracy. Thus, I2X not only faithfully explains model behavior but also provides a practical approach to guide optimization toward desired targets.
MixerCSeg: An Efficient Mixer Architecture for Crack Segmentation via Decoupled Mamba Attention
Mar 02, 2026Feature encoders play a key role in pixel-level crack segmentation by shaping the representation of fine textures and thin structures. Existing CNN-, Transformer-, and Mamba-based models each capture only part of the required spatial or structural information, leaving clear gaps in modeling complex crack patterns. To address this, we present MixerCSeg, a mixer architecture designed like a coordinated team of specialists, where CNN-like pathways focus on local textures, Transformer-style paths capture global dependencies, and Mamba-inspired flows model sequential context within a single encoder. At the core of MixerCSeg is the TransMixer, which explores Mamba's latent attention behavior while establishing dedicated pathways that naturally express both locality and global awareness. To further enhance structural fidelity, we introduce a spatial block processing strategy and a Direction-guided Edge Gated Convolution (DEGConv) that strengthens edge sensitivity under irregular crack geometries with minimal computational overhead. A Spatial Refinement Multi-Level Fusion (SRF) module is then employed to refine multi-scale details without increasing complexity. Extensive experiments on multiple crack segmentation benchmarks show that MixerCSeg achieves state-of-the-art performance with only 2.05 GFLOPs and 2.54 M parameters, demonstrating both efficiency and strong representational capability. The code is available at https://github.com/spiderforest/MixerCSeg.
Seeing Clearly, Reasoning Confidently: Plug-and-Play Remedies for Vision Language Model Blindness
Feb 23, 2026Vision language models (VLMs) have achieved remarkable success in broad visual understanding, yet they remain challenged by object-centric reasoning on rare objects due to the scarcity of such instances in pretraining data. While prior efforts alleviate this issue by retrieving additional data or introducing stronger vision encoders, these methods are still computationally intensive during finetuning VLMs and don't fully exploit the original training data. In this paper, we introduce an efficient plug-and-play module that substantially improves VLMs' reasoning over rare objects by refining visual tokens and enriching input text prompts, without VLMs finetuning. Specifically, we propose to learn multi-modal class embeddings for rare objects by leveraging prior knowledge from vision foundation models and synonym-augmented text descriptions, compensating for limited training examples. These embeddings refine the visual tokens in VLMs through a lightweight attention-based enhancement module that improves fine-grained object details. In addition, we use the learned embeddings as object-aware detectors to generate informative hints, which are injected into the text prompts to help guide the VLM's attention toward relevant image regions. Experiments on two benchmarks show consistent and substantial gains for pretrained VLMs in rare object recognition and reasoning. Further analysis reveals how our method strengthens the VLM's ability to focus on and reason about rare objects.
VLMs Guided Interpretable Decision Making for Autonomous Driving
Nov 17, 2025



Recent advancements in autonomous driving (AD) have explored the use of vision-language models (VLMs) within visual question answering (VQA) frameworks for direct driving decision-making. However, these approaches often depend on handcrafted prompts and suffer from inconsistent performance, limiting their robustness and generalization in real-world scenarios. In this work, we evaluate state-of-the-art open-source VLMs on high-level decision-making tasks using ego-view visual inputs and identify critical limitations in their ability to deliver reliable, context-aware decisions. Motivated by these observations, we propose a new approach that shifts the role of VLMs from direct decision generators to semantic enhancers. Specifically, we leverage their strong general scene understanding to enrich existing vision-based benchmarks with structured, linguistically rich scene descriptions. Building on this enriched representation, we introduce a multi-modal interactive architecture that fuses visual and linguistic features for more accurate decision-making and interpretable textual explanations. Furthermore, we design a post-hoc refinement module that utilizes VLMs to enhance prediction reliability. Extensive experiments on two autonomous driving benchmarks demonstrate that our approach achieves state-of-the-art performance, offering a promising direction for integrating VLMs into reliable and interpretable AD systems.
Diffusion Guided Adversarial State Perturbations in Reinforcement Learning
Nov 10, 2025
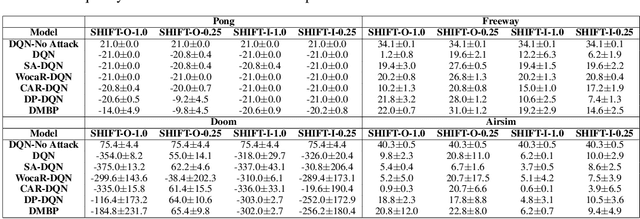


Reinforcement learning (RL) systems, while achieving remarkable success across various domains, are vulnerable to adversarial attacks. This is especially a concern in vision-based environments where minor manipulations of high-dimensional image inputs can easily mislead the agent's behavior. To this end, various defenses have been proposed recently, with state-of-the-art approaches achieving robust performance even under large state perturbations. However, after closer investigation, we found that the effectiveness of the current defenses is due to a fundamental weakness of the existing $l_p$ norm-constrained attacks, which can barely alter the semantics of image input even under a relatively large perturbation budget. In this work, we propose SHIFT, a novel policy-agnostic diffusion-based state perturbation attack to go beyond this limitation. Our attack is able to generate perturbed states that are semantically different from the true states while remaining realistic and history-aligned to avoid detection. Evaluations show that our attack effectively breaks existing defenses, including the most sophisticated ones, significantly outperforming existing attacks while being more perceptually stealthy. The results highlight the vulnerability of RL agents to semantics-aware adversarial perturbations, indicating the importance of developing more robust policies.
TCR-EML: Explainable Model Layers for TCR-pMHC Prediction
Oct 05, 2025T cell receptor (TCR) recognition of peptide-MHC (pMHC) complexes is a central component of adaptive immunity, with implications for vaccine design, cancer immunotherapy, and autoimmune disease. While recent advances in machine learning have improved prediction of TCR-pMHC binding, the most effective approaches are black-box transformer models that cannot provide a rationale for predictions. Post-hoc explanation methods can provide insight with respect to the input but do not explicitly model biochemical mechanisms (e.g. known binding regions), as in TCR-pMHC binding. ``Explain-by-design'' models (i.e., with architectural components that can be examined directly after training) have been explored in other domains, but have not been used for TCR-pMHC binding. We propose explainable model layers (TCR-EML) that can be incorporated into protein-language model backbones for TCR-pMHC modeling. Our approach uses prototype layers for amino acid residue contacts drawn from known TCR-pMHC binding mechanisms, enabling high-quality explanations for predicted TCR-pMHC binding. Experiments of our proposed method on large-scale datasets demonstrate competitive predictive accuracy and generalization, and evaluation on the TCR-XAI benchmark demonstrates improved explainability compared with existing approaches.
Doctor Approved: Generating Medically Accurate Skin Disease Images through AI-Expert Feedback
Jun 14, 2025Paucity of medical data severely limits the generalizability of diagnostic ML models, as the full spectrum of disease variability can not be represented by a small clinical dataset. To address this, diffusion models (DMs) have been considered as a promising avenue for synthetic image generation and augmentation. However, they frequently produce medically inaccurate images, deteriorating the model performance. Expert domain knowledge is critical for synthesizing images that correctly encode clinical information, especially when data is scarce and quality outweighs quantity. Existing approaches for incorporating human feedback, such as reinforcement learning (RL) and Direct Preference Optimization (DPO), rely on robust reward functions or demand labor-intensive expert evaluations. Recent progress in Multimodal Large Language Models (MLLMs) reveals their strong visual reasoning capabilities, making them adept candidates as evaluators. In this work, we propose a novel framework, coined MAGIC (Medically Accurate Generation of Images through AI-Expert Collaboration), that synthesizes clinically accurate skin disease images for data augmentation. Our method creatively translates expert-defined criteria into actionable feedback for image synthesis of DMs, significantly improving clinical accuracy while reducing the direct human workload. Experiments demonstrate that our method greatly improves the clinical quality of synthesized skin disease images, with outputs aligning with dermatologist assessments. Additionally, augmenting training data with these synthesized images improves diagnostic accuracy by +9.02% on a challenging 20-condition skin disease classification task, and by +13.89% in the few-shot setting.
Exploiting Aggregation and Segregation of Representations for Domain Adaptive Human Pose Estimation
Dec 29, 2024Human pose estimation (HPE) has received increasing attention recently due to its wide application in motion analysis, virtual reality, healthcare, etc. However, it suffers from the lack of labeled diverse real-world datasets due to the time- and labor-intensive annotation. To cope with the label deficiency issue, one common solution is to train the HPE models with easily available synthetic datasets (source) and apply them to real-world data (target) through domain adaptation (DA). Unfortunately, prevailing domain adaptation techniques within the HPE domain remain predominantly fixated on effecting alignment and aggregation between source and target features, often sidestepping the crucial task of excluding domain-specific representations. To rectify this, we introduce a novel framework that capitalizes on both representation aggregation and segregation for domain adaptive human pose estimation. Within this framework, we address the network architecture aspect by disentangling representations into distinct domain-invariant and domain-specific components, facilitating aggregation of domain-invariant features while simultaneously segregating domain-specific ones. Moreover, we tackle the discrepancy measurement facet by delving into various keypoint relationships and applying separate aggregation or segregation mechanisms to enhance alignment. Extensive experiments on various benchmarks, e.g., Human3.6M, LSP, H3D, and FreiHand, show that our method consistently achieves state-of-the-art performance. The project is available at \url{https://github.com/davidpengucf/EPIC}.
Enhancing Skin Disease Diagnosis: Interpretable Visual Concept Discovery with SAM Empowerment
Sep 14, 2024
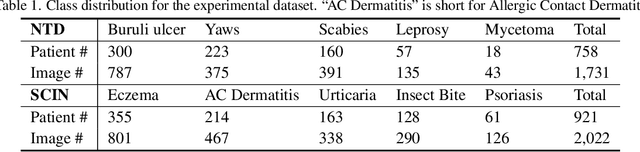


Current AI-assisted skin image diagnosis has achieved dermatologist-level performance in classifying skin cancer, driven by rapid advancements in deep learning architectures. However, unlike traditional vision tasks, skin images in general present unique challenges due to the limited availability of well-annotated datasets, complex variations in conditions, and the necessity for detailed interpretations to ensure patient safety. Previous segmentation methods have sought to reduce image noise and enhance diagnostic performance, but these techniques require fine-grained, pixel-level ground truth masks for training. In contrast, with the rise of foundation models, the Segment Anything Model (SAM) has been introduced to facilitate promptable segmentation, enabling the automation of the segmentation process with simple yet effective prompts. Efforts applying SAM predominantly focus on dermatoscopy images, which present more easily identifiable lesion boundaries than clinical photos taken with smartphones. This limitation constrains the practicality of these approaches to real-world applications. To overcome the challenges posed by noisy clinical photos acquired via non-standardized protocols and to improve diagnostic accessibility, we propose a novel Cross-Attentive Fusion framework for interpretable skin lesion diagnosis. Our method leverages SAM to generate visual concepts for skin diseases using prompts, integrating local visual concepts with global image features to enhance model performance. Extensive evaluation on two skin disease datasets demonstrates our proposed method's effectiveness on lesion diagnosis and interpretability.
From Majority to Minority: A Diffusion-based Augmentation for Underrepresented Groups in Skin Lesion Analysis
Jun 26, 2024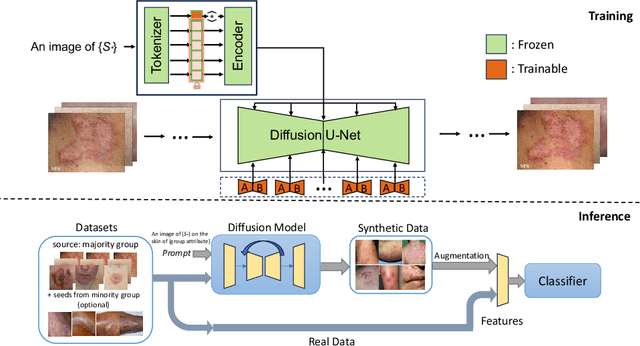
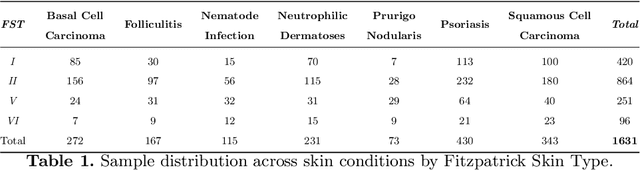

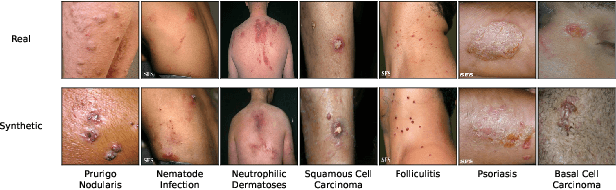
AI-based diagnoses have demonstrated dermatologist-level performance in classifying skin cancer. However, such systems are prone to under-performing when tested on data from minority groups that lack sufficient representation in the training sets. Although data collection and annotation offer the best means for promoting minority groups, these processes are costly and time-consuming. Prior works have suggested that data from majority groups may serve as a valuable information source to supplement the training of diagnosis tools for minority groups. In this work, we propose an effective diffusion-based augmentation framework that maximizes the use of rich information from majority groups to benefit minority groups. Using groups with different skin types as a case study, our results show that the proposed framework can generate synthetic images that improve diagnostic results for the minority groups, even when there is little or no reference data from these target groups. The practical value of our work is evident in medical imaging analysis, where under-diagnosis persists as a problem for certain groups due to insufficient representation.