 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperGrasp: Single-View Object Grasping via Superquadric Similarity Matching, Evaluation, and Refinement
Mar 31, 2026Robotic grasping from single-view observations remains a critical challenge in manipulation. Existing methods still struggle to generate stable and valid grasp poses when confronted with incomplete geometric information. To address these limitations, we propose SuperGrasp, a novel two-stage framework for single-view grasping with parallel-jaw grippers that decomposes the grasping process into initial grasp pose generation and subsequent grasp evaluation and refinement. In the first stage, we introduce a Similarity Matching Module that efficiently retrieves grasp candidates by matching the input single-view point cloud with a pre-computed primitive dataset based on superquadric coefficients. In the second stage, we propose E-RNet, an end-to-end network that expands the graspaware region and takes the initial grasp closure region as a local anchor region, enabling more accurate and reliable evaluation and refinement of grasp candidates. To enhance generalization, we construct a primitive dataset containing 1.5k primitives for similarity matching and collect a large-scale point cloud dataset with 100k stable grasp labels from 124 objects for network training. Extensive experiments in both simulation and realworld environments demonstrate that our method achieves stable grasping performance and strong generalization across varying scenes and novel objects.
UniMotion: A Unified Framework for Motion-Text-Vision Understanding and Generation
Mar 23, 2026We present UniMotion, to our knowledge the first unified framework for simultaneous understanding and generation of human motion, natural language, and RGB images within a single architecture. Existing unified models handle only restricted modality subsets (e.g., Motion-Text or static Pose-Image) and predominantly rely on discrete tokenization, which introduces quantization errors and disrupts temporal continuity. UniMotion overcomes both limitations through a core principle: treating motion as a first-class continuous modality on equal footing with RGB. A novel Cross-Modal Aligned Motion VAE (CMA-VAE) and symmetric dual-path embedders construct parallel continuous pathways for Motion and RGB within a shared LLM backbone. To inject visual-semantic priors into motion representations without requiring images at inference, we propose Dual-Posterior KL Alignment (DPA), which distills a vision-fused encoder's richer posterior into the motion-only encoder. To address the cold-start problem -- where text supervision alone is too sparse to calibrate the newly introduced motion pathway -- we further propose Latent Reconstruction Alignment (LRA), a self-supervised pre-training strategy that uses dense motion latents as unambiguous conditions to co-calibrate the embedder, backbone, and flow head, establishing a stable motion-aware foundation for all downstream tasks. UniMotion achieves state-of-the-art performance across seven tasks spanning any-to-any understanding, generation, and editing among the three modalities, with especially strong advantages on cross-modal compositional tasks.
GAPG: Geometry Aware Push-Grasping Synergy for Goal-Oriented Manipulation in Clutter
Mar 22, 2026Grasping target objects is a fundamental skill for robotic manipulation, but in cluttered environments with stacked or occluded objects, a single-step grasp is often insufficient. To address this, previous work has introduced pushing as an auxiliary action to create graspable space. However, these methods often struggle with both stability and efficiency because they neglect the scene's geometric information, which is essential for evaluating grasp robustness and ensuring that pushing actions are safe and effective. To this end, we propose a geometry-aware push-grasp synergy framework that leverages point cloud data to integrate grasp and push evaluation. Specifically, the grasp evaluation module analyzes the geometric relationship between the gripper's point cloud and the points enclosed within its closing region to determine grasp feasibility and stability. Guided by this, the push evaluation module predicts how pushing actions influence future graspable space, enabling the robot to select actions that reliably transform non-graspable states into graspable ones. By jointly reasoning about geometry in both grasping and pushing, our framework achieves safer, more efficient, and more reliable manipulation in cluttered settings. Our method is extensively tested in simulation and real-world environments in various scenarios. Experimental results demonstrate that our model generalizes well to real-world scenes and unseen objects.
Federated Multi-Task Clustering
Dec 30, 2025Spectral clustering has emerged as one of the most effective clustering algorithms due to its superior performance. However, most existing models are designed for centralized settings, rendering them inapplicable in modern decentralized environments. Moreover, current federated learning approaches often suffer from poor generalization performance due to reliance on unreliable pseudo-labels, and fail to capture the latent correlations amongst heterogeneous clients. To tackle these limitations, this paper proposes a novel framework named Federated Multi-Task Clustering (i.e.,FMTC), which intends to learn personalized clustering models for heterogeneous clients while collaboratively leveraging their shared underlying structure in a privacy-preserving manner. More specifically, the FMTC framework is composed of two main components: client-side personalized clustering module, which learns a parameterized mapping model to support robust out-of-sample inference, bypassing the need for unreliable pseudo-labels; and server-side tensorial correlation module, which explicitly captures the shared knowledge across all clients. This is achieved by organizing all client models into a unified tensor and applying a low-rank regularization to discover their common subspace. To solve this joint optimization problem, we derive an efficient, privacy-preserving distributed algorithm based on the Alternating Direction Method of Multipliers, which decomposes the global problem into parallel local updates on clients and an aggregation step on the server. To the end, several extensive experiments on multiple real-world datasets demonstrate that our proposed FMTC framework significantly outperforms various baseline and state-of-the-art federated clustering algorithms.
OpenVLN: Open-world aerial Vision-Language Navigation
Nov 09, 2025Vision-language models (VLMs) have been widely-applied in ground-based vision-language navigation (VLN). However, the vast complexity of outdoor aerial environments compounds data acquisition challenges and imposes long-horizon trajectory planning requirements on Unmanned Aerial Vehicles (UAVs), introducing novel complexities for aerial VLN. To address these challenges, we propose a data-efficient Open-world aerial Vision-Language Navigation (i.e., OpenVLN) framework, which could execute language-guided flight with limited data constraints and enhance long-horizon trajectory planning capabilities in complex aerial environments. Specifically, we reconfigure a reinforcement learning framework to optimize the VLM for UAV navigation tasks, which can efficiently fine-tune VLM by using rule-based policies under limited training data. Concurrently, we introduce a long-horizon planner for trajectory synthesis that dynamically generates precise UAV actions via value-based rewards. To the end, we conduct sufficient navigation experiments on the TravelUAV benchmark with dataset scaling across diverse reward settings. Our method demonstrates consistent performance gains of up to 4.34% in Success Rate, 6.19% in Oracle Success Rate, and 4.07% in Success weighted by Path Length over baseline methods, validating its deployment efficacy for long-horizon UAV navigation in complex aerial environments.
TMUAD: Enhancing Logical Capabilities in Unified Anomaly Detection Models with a Text Memory Bank
Aug 29, 2025Anomaly detection, which aims to identify anomalies deviating from normal patterns, is challenging due to the limited amount of normal data available. Unlike most existing unified methods that rely on carefully designed image feature extractors and memory banks to capture logical relationships between objects, we introduce a text memory bank to enhance the detection of logical anomalies. Specifically, we propose a Three-Memory framework for Unified structural and logical Anomaly Detection (TMUAD). First, we build a class-level text memory bank for logical anomaly detection by the proposed logic-aware text extractor, which can capture rich logical descriptions of objects from input images. Second, we construct an object-level image memory bank that preserves complete object contours by extracting features from segmented objects. Third, we employ visual encoders to extract patch-level image features for constructing a patch-level memory bank for structural anomaly detection. These three complementary memory banks are used to retrieve and compare normal images that are most similar to the query image, compute anomaly scores at multiple levels, and fuse them into a final anomaly score. By unifying structural and logical anomaly detection through collaborative memory banks, TMUAD achieves state-of-the-art performance across seven publicly available datasets involving industrial and medical domains. The model and code are available at https://github.com/SIA-IDE/TMUAD.
SAGA: Surface-Aligned Gaussian Avatar
Dec 01, 2024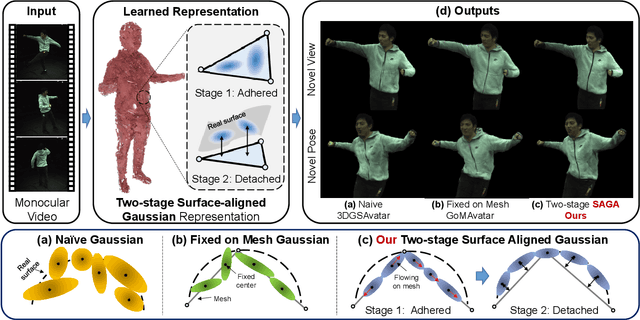

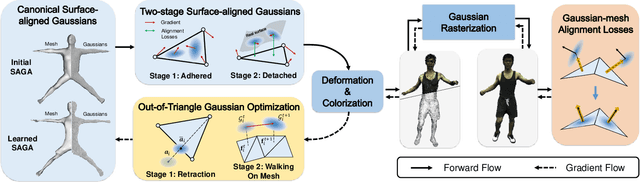
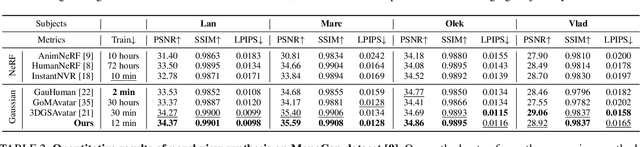
This paper presents a Surface-Aligned Gaussian representation for creating animatable human avatars from monocular videos,aiming at improving the novel view and pose synthesis performance while ensuring fast training and real-time rendering. Recently,3DGS has emerged as a more efficient and expressive alternative to NeRF, and has been used for creating dynamic human avatars. However,when applied to the severely ill-posed task of monocular dynamic reconstruction, the Gaussians tend to overfit the constantly changing regions such as clothes wrinkles or shadows since these regions cannot provide consistent supervision, resulting in noisy geometry and abrupt deformation that typically fail to generalize under novel views and poses.To address these limitations, we present SAGA,i.e.,Surface-Aligned Gaussian Avatar,which aligns the Gaussians with a mesh to enforce well-defined geometry and consistent deformation, thereby improving generalization under novel views and poses. Unlike existing strict alignment methods that suffer from limited expressive power and low realism,SAGA employs a two-stage alignment strategy where the Gaussians are first adhered on while then detached from the mesh, thus facilitating both good geometry and high expressivity. In the Adhered Stage, we improve the flexibility of Adhered-on-Mesh Gaussians by allowing them to flow on the mesh, in contrast to existing methods that rigidly bind Gaussians to fixed location. In the second Detached Stage, we introduce a Gaussian-Mesh Alignment regularization, which allows us to unleash the expressivity by detaching the Gaussians but maintain the geometric alignment by minimizing their location and orientation offsets from the bound triangles. Finally, since the Gaussians may drift outside the bound triangles during optimization, an efficient Walking-on-Mesh strategy is proposed to dynamically update the bound triangles.
Learning Generalizable 3D Manipulation With 10 Demonstrations
Nov 15, 2024
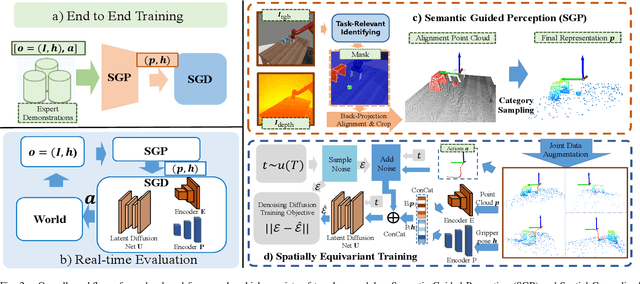


Learning robust and generalizable manipulation skills from demonstrations remains a key challenge in robotics, with broad applications in industrial automation and service robotics. While recent imitation learning methods have achieved impressive results, they often require large amounts of demonstration data and struggle to generalize across different spatial variants. In this work, we present a novel framework that learns manipulation skills from as few as 10 demonstrations, yet still generalizes to spatial variants such as different initial object positions and camera viewpoints. Our framework consists of two key modules: Semantic Guided Perception (SGP), which constructs task-focused, spatially aware 3D point cloud representations from RGB-D inputs; and Spatial Generalized Decision (SGD), an efficient diffusion-based decision-making module that generates actions via denoising. To effectively learn generalization ability from limited data, we introduce a critical spatially equivariant training strategy that captures the spatial knowledge embedded in expert demonstrations. We validate our framework through extensive experiments on both simulation benchmarks and real-world robotic systems. Our method demonstrates a 60 percent improvement in success rates over state-of-the-art approaches on a series of challenging tasks, even with substantial variations in object poses and camera viewpoints. This work shows significant potential for advancing efficient, generalizable manipulation skill learning in real-world applications.
Cs2K: Class-specific and Class-shared Knowledge Guidance for Incremental Semantic Segmentation
Jul 12, 2024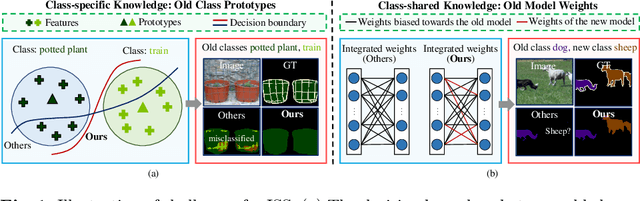
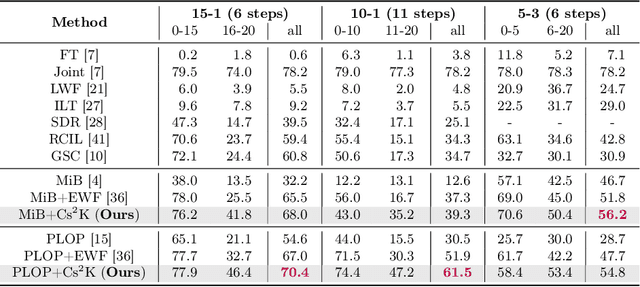
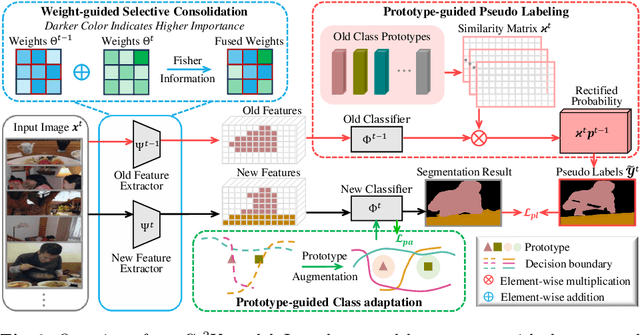
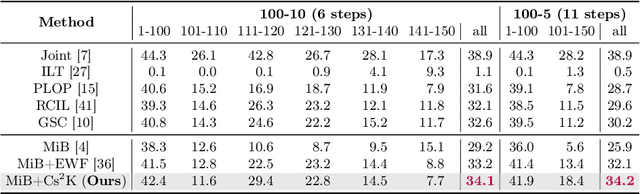
Incremental semantic segmentation endeavors to segment newly encountered classes while maintaining knowledge of old classes. However, existing methods either 1) lack guidance from class-specific knowledge (i.e., old class prototypes), leading to a bias towards new classes, or 2) constrain class-shared knowledge (i.e., old model weights) excessively without discrimination, resulting in a preference for old classes. In this paper, to trade off model performance, we propose the Class-specific and Class-shared Knowledge (Cs2K) guidance for incremental semantic segmentation. Specifically, from the class-specific knowledge aspect, we design a prototype-guided pseudo labeling that exploits feature proximity from prototypes to correct pseudo labels, thereby overcoming catastrophic forgetting. Meanwhile, we develop a prototype-guided class adaptation that aligns class distribution across datasets via learning old augmented prototypes. Moreover, from the class-shared knowledge aspect, we propose a weight-guided selective consolidation to strengthen old memory while maintaining new memory by integrating old and new model weights based on weight importance relative to old classes. Experiments on public datasets demonstrate that our proposed Cs2K significantly improves segmentation performance and is plug-and-play.
MuseumMaker: Continual Style Customization without Catastrophic Forgetting
Apr 29, 2024



Pre-trained large text-to-image (T2I) models with an appropriate text prompt has attracted growing interests in customized images generation field. However, catastrophic forgetting issue make it hard to continually synthesize new user-provided styles while retaining the satisfying results amongst learned styles. In this paper, we propose MuseumMaker, a method that enables the synthesis of images by following a set of customized styles in a never-end manner, and gradually accumulate these creative artistic works as a Museum. When facing with a new customization style, we develop a style distillation loss module to extract and learn the styles of the training data for new image generation. It can minimize the learning biases caused by content of new training images, and address the catastrophic overfitting issue induced by few-shot images. To deal with catastrophic forgetting amongst past learned styles, we devise a dual regularization for shared-LoRA module to optimize the direction of model update, which could regularize the diffusion model from both weight and feature aspects, respectively. Meanwhile, to further preserve historical knowledge from past styles and address the limited representability of LoRA, we consider a task-wise token learning module where a unique token embedding is learned to denote a new style. As any new user-provided style come, our MuseumMaker can capture the nuances of the new styles while maintaining the details of learned styles. Experimental results on diverse style datasets validate the effectiveness of our proposed MuseumMaker method, showcasing its robustness and versatility across various scenarios.