 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeABot-PhysWorld: Interactive World Foundation Model for Robotic Manipulation with Physics Alignment
Mar 24, 2026Video-based world models offer a powerful paradigm for embodied simulation and planning, yet state-of-the-art models often generate physically implausible manipulations - such as object penetration and anti-gravity motion - due to training on generic visual data and likelihood-based objectives that ignore physical laws. We present ABot-PhysWorld, a 14B Diffusion Transformer model that generates visually realistic, physically plausible, and action-controllable videos. Built on a curated dataset of three million manipulation clips with physics-aware annotation, it uses a novel DPO-based post-training framework with decoupled discriminators to suppress unphysical behaviors while preserving visual quality. A parallel context block enables precise spatial action injection for cross-embodiment control. To better evaluate generalization, we introduce EZSbench, the first training-independent embodied zero-shot benchmark combining real and synthetic unseen robot-task-scene combinations. It employs a decoupled protocol to separately assess physical realism and action alignment. ABot-PhysWorld achieves new state-of-the-art performance on PBench and EZSbench, surpassing Veo 3.1 and Sora v2 Pro in physical plausibility and trajectory consistency. We will release EZSbench to promote standardized evaluation in embodied video generation.
ABot-M0: VLA Foundation Model for Robotic Manipulation with Action Manifold Learning
Feb 11, 2026Building general-purpose embodied agents across diverse hardware remains a central challenge in robotics, often framed as the ''one-brain, many-forms'' paradigm. Progress is hindered by fragmented data, inconsistent representations, and misaligned training objectives. We present ABot-M0, a framework that builds a systematic data curation pipeline while jointly optimizing model architecture and training strategies, enabling end-to-end transformation of heterogeneous raw data into unified, efficient representations. From six public datasets, we clean, standardize, and balance samples to construct UniACT-dataset, a large-scale dataset with over 6 million trajectories and 9,500 hours of data, covering diverse robot morphologies and task scenarios. Unified pre-training improves knowledge transfer and generalization across platforms and tasks, supporting general-purpose embodied intelligence. To improve action prediction efficiency and stability, we propose the Action Manifold Hypothesis: effective robot actions lie not in the full high-dimensional space but on a low-dimensional, smooth manifold governed by physical laws and task constraints. Based on this, we introduce Action Manifold Learning (AML), which uses a DiT backbone to predict clean, continuous action sequences directly. This shifts learning from denoising to projection onto feasible manifolds, improving decoding speed and policy stability. ABot-M0 supports modular perception via a dual-stream mechanism that integrates VLM semantics with geometric priors and multi-view inputs from plug-and-play 3D modules such as VGGT and Qwen-Image-Edit, enhancing spatial understanding without modifying the backbone and mitigating standard VLM limitations in 3D reasoning. Experiments show components operate independently with additive benefits. We will release all code and pipelines for reproducibility and future research.
SAGA: Surface-Aligned Gaussian Avatar
Dec 01, 2024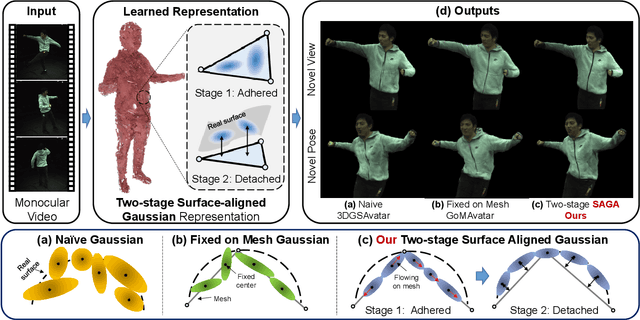

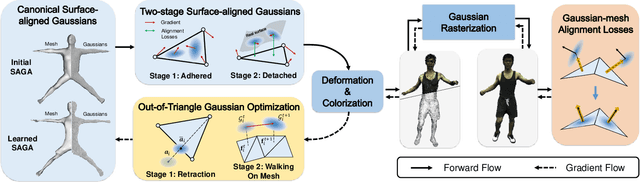
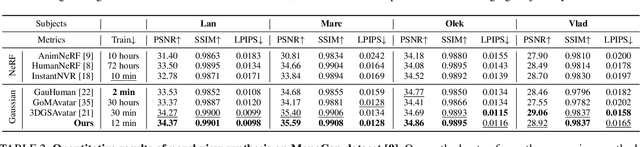
This paper presents a Surface-Aligned Gaussian representation for creating animatable human avatars from monocular videos,aiming at improving the novel view and pose synthesis performance while ensuring fast training and real-time rendering. Recently,3DGS has emerged as a more efficient and expressive alternative to NeRF, and has been used for creating dynamic human avatars. However,when applied to the severely ill-posed task of monocular dynamic reconstruction, the Gaussians tend to overfit the constantly changing regions such as clothes wrinkles or shadows since these regions cannot provide consistent supervision, resulting in noisy geometry and abrupt deformation that typically fail to generalize under novel views and poses.To address these limitations, we present SAGA,i.e.,Surface-Aligned Gaussian Avatar,which aligns the Gaussians with a mesh to enforce well-defined geometry and consistent deformation, thereby improving generalization under novel views and poses. Unlike existing strict alignment methods that suffer from limited expressive power and low realism,SAGA employs a two-stage alignment strategy where the Gaussians are first adhered on while then detached from the mesh, thus facilitating both good geometry and high expressivity. In the Adhered Stage, we improve the flexibility of Adhered-on-Mesh Gaussians by allowing them to flow on the mesh, in contrast to existing methods that rigidly bind Gaussians to fixed location. In the second Detached Stage, we introduce a Gaussian-Mesh Alignment regularization, which allows us to unleash the expressivity by detaching the Gaussians but maintain the geometric alignment by minimizing their location and orientation offsets from the bound triangles. Finally, since the Gaussians may drift outside the bound triangles during optimization, an efficient Walking-on-Mesh strategy is proposed to dynamically update the bound triangles.
Learning Generalizable 3D Manipulation With 10 Demonstrations
Nov 15, 2024
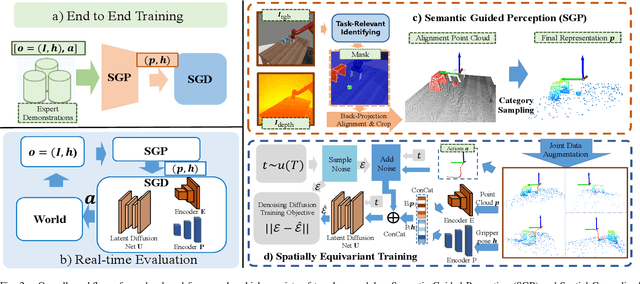


Learning robust and generalizable manipulation skills from demonstrations remains a key challenge in robotics, with broad applications in industrial automation and service robotics. While recent imitation learning methods have achieved impressive results, they often require large amounts of demonstration data and struggle to generalize across different spatial variants. In this work, we present a novel framework that learns manipulation skills from as few as 10 demonstrations, yet still generalizes to spatial variants such as different initial object positions and camera viewpoints. Our framework consists of two key modules: Semantic Guided Perception (SGP), which constructs task-focused, spatially aware 3D point cloud representations from RGB-D inputs; and Spatial Generalized Decision (SGD), an efficient diffusion-based decision-making module that generates actions via denoising. To effectively learn generalization ability from limited data, we introduce a critical spatially equivariant training strategy that captures the spatial knowledge embedded in expert demonstrations. We validate our framework through extensive experiments on both simulation benchmarks and real-world robotic systems. Our method demonstrates a 60 percent improvement in success rates over state-of-the-art approaches on a series of challenging tasks, even with substantial variations in object poses and camera viewpoints. This work shows significant potential for advancing efficient, generalizable manipulation skill learning in real-world applications.
Marrying NeRF with Feature Matching for One-step Pose Estimation
Apr 01, 2024



Given the image collection of an object, we aim at building a real-time image-based pose estimation method, which requires neither its CAD model nor hours of object-specific training. Recent NeRF-based methods provide a promising solution by directly optimizing the pose from pixel loss between rendered and target images. However, during inference, they require long converging time, and suffer from local minima, making them impractical for real-time robot applications. We aim at solving this problem by marrying image matching with NeRF. With 2D matches and depth rendered by NeRF, we directly solve the pose in one step by building 2D-3D correspondences between target and initial view, thus allowing for real-time prediction. Moreover, to improve the accuracy of 2D-3D correspondences, we propose a 3D consistent point mining strategy, which effectively discards unfaithful points reconstruted by NeRF. Moreover, current NeRF-based methods naively optimizing pixel loss fail at occluded images. Thus, we further propose a 2D matches based sampling strategy to preclude the occluded area. Experimental results on representative datasets prove that our method outperforms state-of-the-art methods, and improves inference efficiency by 90x, achieving real-time prediction at 6 FPS.
The Devil is in the Pose: Ambiguity-free 3D Rotation-invariant Learning via Pose-aware Convolution
May 30, 2022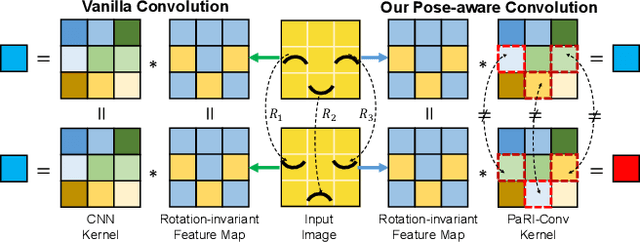
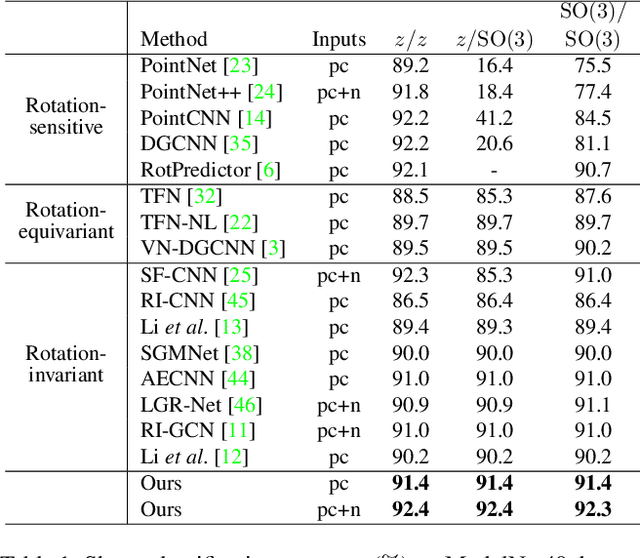
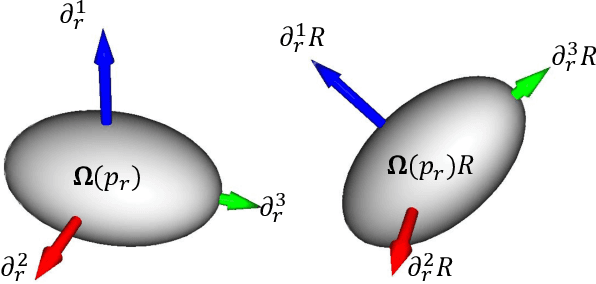
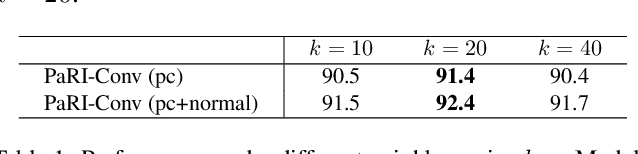
Rotation-invariant (RI) 3D deep learning methods suffer performance degradation as they typically design RI representations as input that lose critical global information comparing to 3D coordinates. Most state-of-the-arts address it by incurring additional blocks or complex global representations in a heavy and ineffective manner. In this paper, we reveal that the global information loss stems from an unexplored pose information loss problem, which can be solved more efficiently and effectively as we only need to restore more lightweight local pose in each layer, and the global information can be hierarchically aggregated in the deep networks without extra efforts. To address this problem, we develop a Pose-aware Rotation Invariant Convolution (i.e., PaRI-Conv), which dynamically adapts its kernels based on the relative poses. To implement it, we propose an Augmented Point Pair Feature (APPF) to fully encode the RI relative pose information, and a factorized dynamic kernel for pose-aware kernel generation, which can further reduce the computational cost and memory burden by decomposing the kernel into a shared basis matrix and a pose-aware diagonal matrix. Extensive experiments on shape classification and part segmentation tasks show that our PaRI-Conv surpasses the state-of-the-art RI methods while being more compact and efficient.
Unsupervised Dense Deformation Embedding Network for Template-Free Shape Correspondence
Aug 26, 2021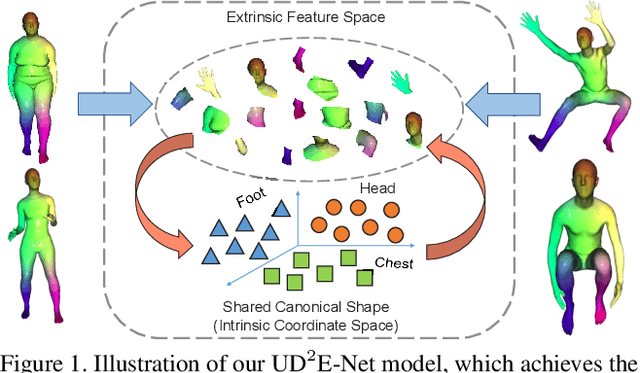
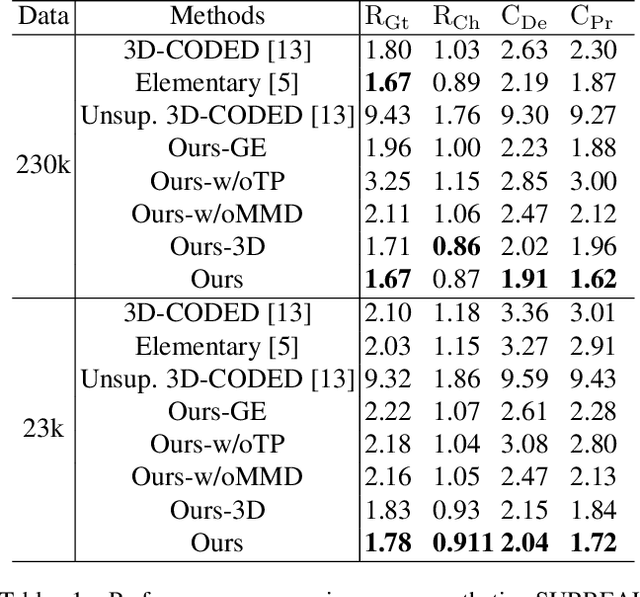
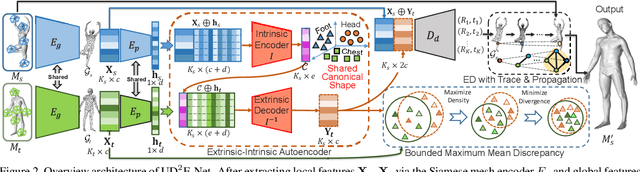
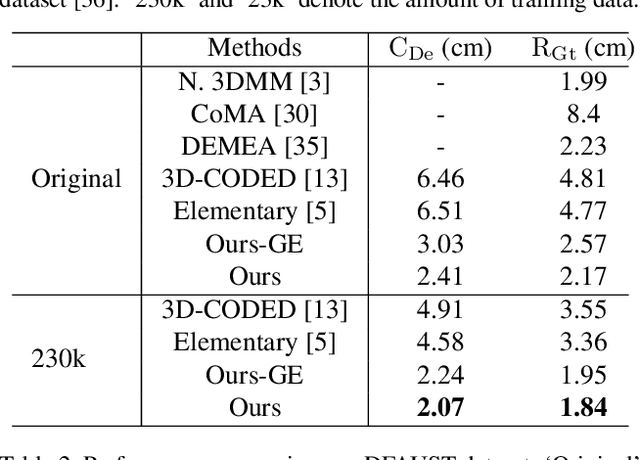
Shape correspondence from 3D deformation learning has attracted appealing academy interests recently. Nevertheless, current deep learning based methods require the supervision of dense annotations to learn per-point translations, which severely overparameterize the deformation process. Moreover, they fail to capture local geometric details of original shape via global feature embedding. To address these challenges, we develop a new Unsupervised Dense Deformation Embedding Network (i.e., UD^2E-Net), which learns to predict deformations between non-rigid shapes from dense local features. Since it is non-trivial to match deformation-variant local features for deformation prediction, we develop an Extrinsic-Intrinsic Autoencoder to frst encode extrinsic geometric features from source into intrinsic coordinates in a shared canonical shape, with which the decoder then synthesizes corresponding target features. Moreover, a bounded maximum mean discrepancy loss is developed to mitigate the distribution divergence between the synthesized and original features. To learn natural deformation without dense supervision, we introduce a coarse parameterized deformation graph, for which a novel trace and propagation algorithm is proposed to improve both the quality and effciency of the deformation. Our UD^2E-Net outperforms state-of-the-art unsupervised methods by 24% on Faust Inter challenge and even supervised methods by 13% on Faust Intra challenge.