 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Devil is in the Pose: Ambiguity-free 3D Rotation-invariant Learning via Pose-aware Convolution
Paper and Code
May 30, 2022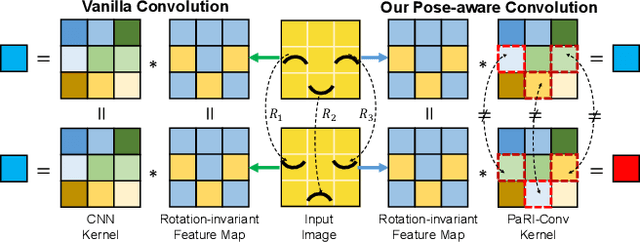
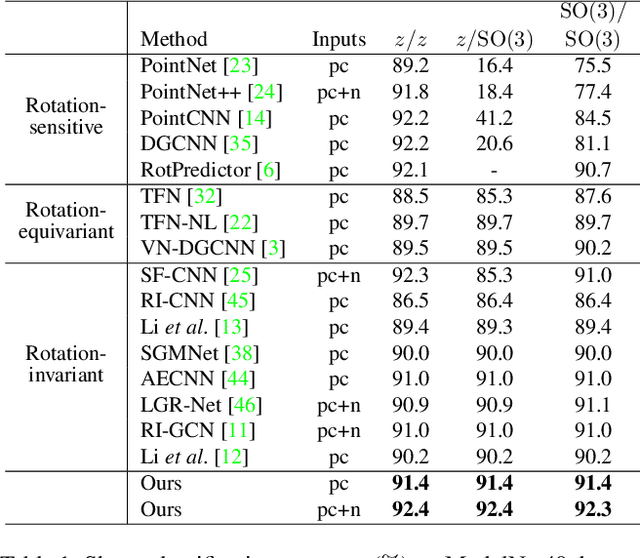
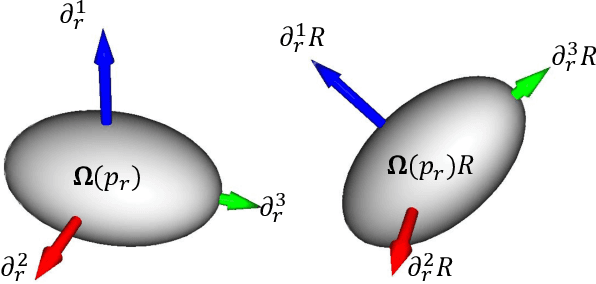
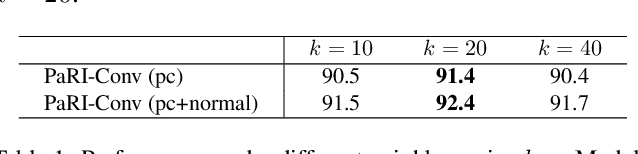
Rotation-invariant (RI) 3D deep learning methods suffer performance degradation as they typically design RI representations as input that lose critical global information comparing to 3D coordinates. Most state-of-the-arts address it by incurring additional blocks or complex global representations in a heavy and ineffective manner. In this paper, we reveal that the global information loss stems from an unexplored pose information loss problem, which can be solved more efficiently and effectively as we only need to restore more lightweight local pose in each layer, and the global information can be hierarchically aggregated in the deep networks without extra efforts. To address this problem, we develop a Pose-aware Rotation Invariant Convolution (i.e., PaRI-Conv), which dynamically adapts its kernels based on the relative poses. To implement it, we propose an Augmented Point Pair Feature (APPF) to fully encode the RI relative pose information, and a factorized dynamic kernel for pose-aware kernel generation, which can further reduce the computational cost and memory burden by decomposing the kernel into a shared basis matrix and a pose-aware diagonal matrix. Extensive experiments on shape classification and part segmentation tasks show that our PaRI-Conv surpasses the state-of-the-art RI methods while being more compact and efficient.