 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Generalizable 3D Manipulation With 10 Demonstrations
Nov 15, 2024
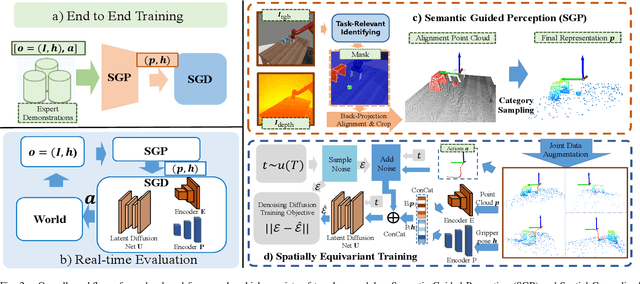


Learning robust and generalizable manipulation skills from demonstrations remains a key challenge in robotics, with broad applications in industrial automation and service robotics. While recent imitation learning methods have achieved impressive results, they often require large amounts of demonstration data and struggle to generalize across different spatial variants. In this work, we present a novel framework that learns manipulation skills from as few as 10 demonstrations, yet still generalizes to spatial variants such as different initial object positions and camera viewpoints. Our framework consists of two key modules: Semantic Guided Perception (SGP), which constructs task-focused, spatially aware 3D point cloud representations from RGB-D inputs; and Spatial Generalized Decision (SGD), an efficient diffusion-based decision-making module that generates actions via denoising. To effectively learn generalization ability from limited data, we introduce a critical spatially equivariant training strategy that captures the spatial knowledge embedded in expert demonstrations. We validate our framework through extensive experiments on both simulation benchmarks and real-world robotic systems. Our method demonstrates a 60 percent improvement in success rates over state-of-the-art approaches on a series of challenging tasks, even with substantial variations in object poses and camera viewpoints. This work shows significant potential for advancing efficient, generalizable manipulation skill learning in real-world applications.