 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperGrasp: Single-View Object Grasping via Superquadric Similarity Matching, Evaluation, and Refinement
Mar 31, 2026Robotic grasping from single-view observations remains a critical challenge in manipulation. Existing methods still struggle to generate stable and valid grasp poses when confronted with incomplete geometric information. To address these limitations, we propose SuperGrasp, a novel two-stage framework for single-view grasping with parallel-jaw grippers that decomposes the grasping process into initial grasp pose generation and subsequent grasp evaluation and refinement. In the first stage, we introduce a Similarity Matching Module that efficiently retrieves grasp candidates by matching the input single-view point cloud with a pre-computed primitive dataset based on superquadric coefficients. In the second stage, we propose E-RNet, an end-to-end network that expands the graspaware region and takes the initial grasp closure region as a local anchor region, enabling more accurate and reliable evaluation and refinement of grasp candidates. To enhance generalization, we construct a primitive dataset containing 1.5k primitives for similarity matching and collect a large-scale point cloud dataset with 100k stable grasp labels from 124 objects for network training. Extensive experiments in both simulation and realworld environments demonstrate that our method achieves stable grasping performance and strong generalization across varying scenes and novel objects.
GAPG: Geometry Aware Push-Grasping Synergy for Goal-Oriented Manipulation in Clutter
Mar 22, 2026Grasping target objects is a fundamental skill for robotic manipulation, but in cluttered environments with stacked or occluded objects, a single-step grasp is often insufficient. To address this, previous work has introduced pushing as an auxiliary action to create graspable space. However, these methods often struggle with both stability and efficiency because they neglect the scene's geometric information, which is essential for evaluating grasp robustness and ensuring that pushing actions are safe and effective. To this end, we propose a geometry-aware push-grasp synergy framework that leverages point cloud data to integrate grasp and push evaluation. Specifically, the grasp evaluation module analyzes the geometric relationship between the gripper's point cloud and the points enclosed within its closing region to determine grasp feasibility and stability. Guided by this, the push evaluation module predicts how pushing actions influence future graspable space, enabling the robot to select actions that reliably transform non-graspable states into graspable ones. By jointly reasoning about geometry in both grasping and pushing, our framework achieves safer, more efficient, and more reliable manipulation in cluttered settings. Our method is extensively tested in simulation and real-world environments in various scenarios. Experimental results demonstrate that our model generalizes well to real-world scenes and unseen objects.
Technical Report: Towards Spatial Feature Regularization in Deep-Learning-Based Array-SAR Reconstruction
Dec 22, 2024Array synthetic aperture radar (Array-SAR), also known as tomographic SAR (TomoSAR), has demonstrated significant potential for high-quality 3D mapping, particularly in urban areas.While deep learning (DL) methods have recently shown strengths in reconstruction, most studies rely on pixel-by-pixel reconstruction, neglecting spatial features like building structures, leading to artifacts such as holes and fragmented edges. Spatial feature regularization, effective in traditional methods, remains underexplored in DL-based approaches. Our study integrates spatial feature regularization into DL-based Array-SAR reconstruction, addressing key questions: What spatial features are relevant in urban-area mapping? How can these features be effectively described, modeled, regularized, and incorporated into DL networks? The study comprises five phases: spatial feature description and modeling, regularization, feature-enhanced network design, evaluation, and discussions. Sharp edges and geometric shapes in urban scenes are analyzed as key features. An intra-slice and inter-slice strategy is proposed, using 2D slices as reconstruction units and fusing them into 3D scenes through parallel and serial fusion. Two computational frameworks-iterative reconstruction with enhancement and light reconstruction with enhancement-are designed, incorporating spatial feature modules into DL networks, leading to four specialized reconstruction networks. Using our urban building simulation dataset and two public datasets, six tests evaluate close-point resolution, structural integrity, and robustness in urban scenarios. Results show that spatial feature regularization significantly improves reconstruction accuracy, retrieves more complete building structures, and enhances robustness by reducing noise and outliers.
Learning Generalizable 3D Manipulation With 10 Demonstrations
Nov 15, 2024
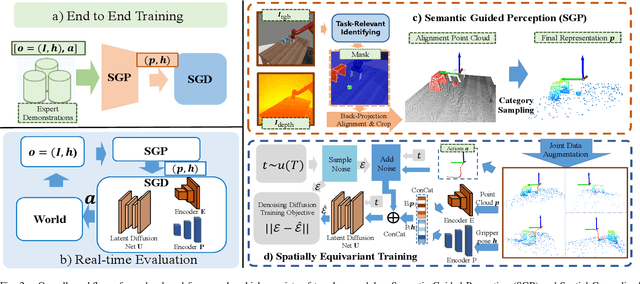


Learning robust and generalizable manipulation skills from demonstrations remains a key challenge in robotics, with broad applications in industrial automation and service robotics. While recent imitation learning methods have achieved impressive results, they often require large amounts of demonstration data and struggle to generalize across different spatial variants. In this work, we present a novel framework that learns manipulation skills from as few as 10 demonstrations, yet still generalizes to spatial variants such as different initial object positions and camera viewpoints. Our framework consists of two key modules: Semantic Guided Perception (SGP), which constructs task-focused, spatially aware 3D point cloud representations from RGB-D inputs; and Spatial Generalized Decision (SGD), an efficient diffusion-based decision-making module that generates actions via denoising. To effectively learn generalization ability from limited data, we introduce a critical spatially equivariant training strategy that captures the spatial knowledge embedded in expert demonstrations. We validate our framework through extensive experiments on both simulation benchmarks and real-world robotic systems. Our method demonstrates a 60 percent improvement in success rates over state-of-the-art approaches on a series of challenging tasks, even with substantial variations in object poses and camera viewpoints. This work shows significant potential for advancing efficient, generalizable manipulation skill learning in real-world applications.
Marrying NeRF with Feature Matching for One-step Pose Estimation
Apr 01, 2024



Given the image collection of an object, we aim at building a real-time image-based pose estimation method, which requires neither its CAD model nor hours of object-specific training. Recent NeRF-based methods provide a promising solution by directly optimizing the pose from pixel loss between rendered and target images. However, during inference, they require long converging time, and suffer from local minima, making them impractical for real-time robot applications. We aim at solving this problem by marrying image matching with NeRF. With 2D matches and depth rendered by NeRF, we directly solve the pose in one step by building 2D-3D correspondences between target and initial view, thus allowing for real-time prediction. Moreover, to improve the accuracy of 2D-3D correspondences, we propose a 3D consistent point mining strategy, which effectively discards unfaithful points reconstruted by NeRF. Moreover, current NeRF-based methods naively optimizing pixel loss fail at occluded images. Thus, we further propose a 2D matches based sampling strategy to preclude the occluded area. Experimental results on representative datasets prove that our method outperforms state-of-the-art methods, and improves inference efficiency by 90x, achieving real-time prediction at 6 FPS.
Never-Ending Embodied Robot Learning
Mar 01, 2024



Relying on large language models (LLMs), embodied robots could perform complex multimodal robot manipulation tasks from visual observations with powerful generalization ability. However, most visual behavior-cloning agents suffer from manipulation performance degradation and skill knowledge forgetting when adapting into a series of challenging unseen tasks. We here investigate the above challenge with NBCagent in embodied robots, a pioneering language-conditioned Never-ending Behavior-Cloning agent, which can continually learn observation knowledge of novel robot manipulation skills from skill-specific and skill-shared attributes. Specifically, we establish a skill-specific evolving planner to perform knowledge decoupling, which can continually embed novel skill-specific knowledge in our NBCagent agent from latent and low-rank space. Meanwhile, we propose a skill-shared semantics rendering module and a skill-shared representation distillation module to effectively transfer anti-forgetting skill-shared knowledge, further tackling catastrophic forgetting on old skills from semantics and representation aspects. Finally, we design a continual embodied robot manipulation benchmark, and several expensive experiments demonstrate the significant performance of our method. Visual results, code, and dataset are provided at: https://neragent.github.io.
MM-SFENet: Multi-scale Multi-task Localization and Classification of Bladder Cancer in MRI with Spatial Feature Encoder Network
Feb 22, 2023Background and Objective: Bladder cancer is a common malignant urinary carcinoma, with muscle-invasive and non-muscle-invasive as its two major subtypes. This paper aims to achieve automated bladder cancer invasiveness localization and classification based on MRI. Method: Different from previous efforts that segment bladder wall and tumor, we propose a novel end-to-end multi-scale multi-task spatial feature encoder network (MM-SFENet) for locating and classifying bladder cancer, according to the classification criteria of the spatial relationship between the tumor and bladder wall. First, we built a backbone with residual blocks to distinguish bladder wall and tumor; then, a spatial feature encoder is designed to encode the multi-level features of the backbone to learn the criteria. Results: We substitute Smooth-L1 Loss with IoU Loss for multi-task learning, to improve the accuracy of the classification task. By testing a total of 1287 MRIs collected from 98 patients at the hospital, the mAP and IoU are used as the evaluation metrics. The experimental result could reach 93.34\% and 83.16\% on test set. Conclusions: The experimental result demonstrates the effectiveness of the proposed MM-SFENet on the localization and classification of bladder cancer. It may provide an effective supplementary diagnosis method for bladder cancer staging.
A Model-data-driven Network Embedding Multidimensional Features for Tomographic SAR Imaging
Nov 28, 2022



Deep learning (DL)-based tomographic SAR imaging algorithms are gradually being studied. Typically, they use an unfolding network to mimic the iterative calculation of the classical compressive sensing (CS)-based methods and process each range-azimuth unit individually. However, only one-dimensional features are effectively utilized in this way. The correlation between adjacent resolution units is ignored directly. To address that, we propose a new model-data-driven network to achieve tomoSAR imaging based on multi-dimensional features. Guided by the deep unfolding methodology, a two-dimensional deep unfolding imaging network is constructed. On the basis of it, we add two 2D processing modules, both convolutional encoder-decoder structures, to enhance multi-dimensional features of the imaging scene effectively. Meanwhile, to train the proposed multifeature-based imaging network, we construct a tomoSAR simulation dataset consisting entirely of simulation data of buildings. Experiments verify the effectiveness of the model. Compared with the conventional CS-based FISTA method and DL-based gamma-Net method, the result of our proposed method has better performance on completeness while having decent imaging accuracy.
AETomo-Net: A Novel Deep Learning Network for Tomographic SAR Imaging Based on Multi-dimensional Features
Sep 21, 2022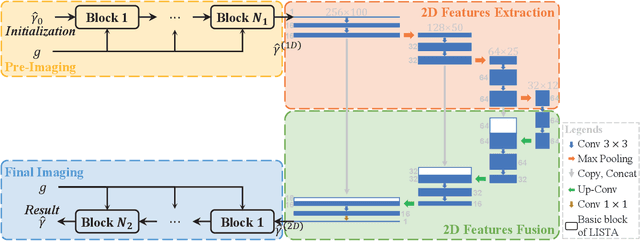
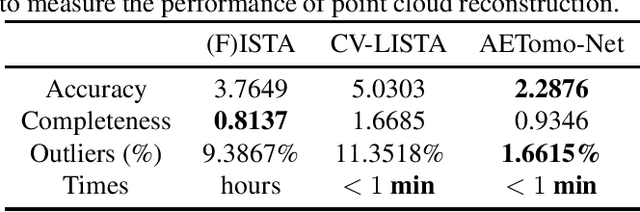
Tomographic synthetic aperture radar (TomoSAR) imaging algorithms based on deep learning can effectively reduce computational costs. The idea of existing researches is to reconstruct the elevation for each range-azimuth cell in one-dimensional using a deep-unfolding network. However, since these methods are commonly sensitive to signal sparsity level, it usually leads to some drawbacks like continuous surface fractures, too many outliers, \textit{et al}. To address them, in this paper, a novel imaging network (AETomo-Net) based on multi-dimensional features is proposed. By adding a U-Net-like structure, AETomo-Net performs reconstruction by each azimuth-elevation slice and adds 2D features extraction and fusion capabilities to the original deep unrolling network. In this way, each azimuth-elevation slice can be reconstructed with richer features and the quality of the imaging results will be improved. Experiments show that the proposed method can effectively solve the above defects while ensuring imaging accuracy and computation speed compared with the traditional ISTA-based method and CV-LISTA.
High-level Decisions from a Safe Maneuver Catalog with Reinforcement Learning for Safe and Cooperative Automated Merging
Jul 15, 2021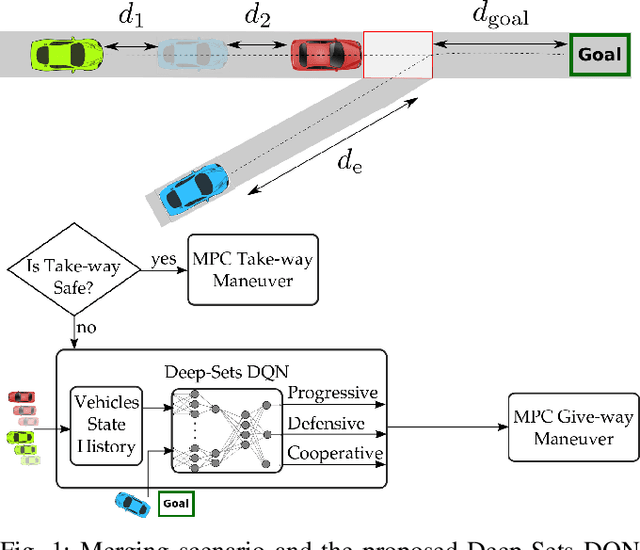
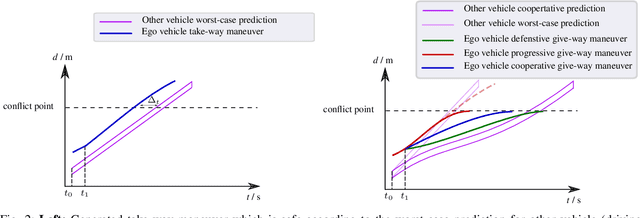
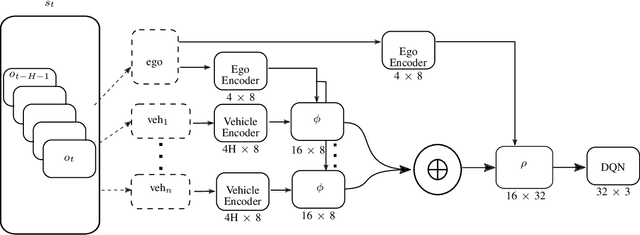
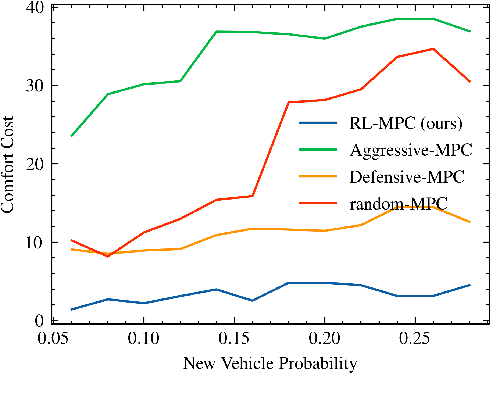
Reinforcement learning (RL) has recently been used for solving challenging decision-making problems in the context of automated driving. However, one of the main drawbacks of the presented RL-based policies is the lack of safety guarantees, since they strive to reduce the expected number of collisions but still tolerate them. In this paper, we propose an efficient RL-based decision-making pipeline for safe and cooperative automated driving in merging scenarios. The RL agent is able to predict the current situation and provide high-level decisions, specifying the operation mode of the low level planner which is responsible for safety. In order to learn a more generic policy, we propose a scalable RL architecture for the merging scenario that is not sensitive to changes in the environment configurations. According to our experiments, the proposed RL agent can efficiently identify cooperative drivers from their vehicle state history and generate interactive maneuvers, resulting in faster and more comfortable automated driving. At the same time, thanks to the safety constraints inside the planner, all of the maneuvers are collision free and safe.