 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Multi-Task Clustering
Dec 30, 2025Spectral clustering has emerged as one of the most effective clustering algorithms due to its superior performance. However, most existing models are designed for centralized settings, rendering them inapplicable in modern decentralized environments. Moreover, current federated learning approaches often suffer from poor generalization performance due to reliance on unreliable pseudo-labels, and fail to capture the latent correlations amongst heterogeneous clients. To tackle these limitations, this paper proposes a novel framework named Federated Multi-Task Clustering (i.e.,FMTC), which intends to learn personalized clustering models for heterogeneous clients while collaboratively leveraging their shared underlying structure in a privacy-preserving manner. More specifically, the FMTC framework is composed of two main components: client-side personalized clustering module, which learns a parameterized mapping model to support robust out-of-sample inference, bypassing the need for unreliable pseudo-labels; and server-side tensorial correlation module, which explicitly captures the shared knowledge across all clients. This is achieved by organizing all client models into a unified tensor and applying a low-rank regularization to discover their common subspace. To solve this joint optimization problem, we derive an efficient, privacy-preserving distributed algorithm based on the Alternating Direction Method of Multipliers, which decomposes the global problem into parallel local updates on clients and an aggregation step on the server. To the end, several extensive experiments on multiple real-world datasets demonstrate that our proposed FMTC framework significantly outperforms various baseline and state-of-the-art federated clustering algorithms.
OpenVLN: Open-world aerial Vision-Language Navigation
Nov 09, 2025Vision-language models (VLMs) have been widely-applied in ground-based vision-language navigation (VLN). However, the vast complexity of outdoor aerial environments compounds data acquisition challenges and imposes long-horizon trajectory planning requirements on Unmanned Aerial Vehicles (UAVs), introducing novel complexities for aerial VLN. To address these challenges, we propose a data-efficient Open-world aerial Vision-Language Navigation (i.e., OpenVLN) framework, which could execute language-guided flight with limited data constraints and enhance long-horizon trajectory planning capabilities in complex aerial environments. Specifically, we reconfigure a reinforcement learning framework to optimize the VLM for UAV navigation tasks, which can efficiently fine-tune VLM by using rule-based policies under limited training data. Concurrently, we introduce a long-horizon planner for trajectory synthesis that dynamically generates precise UAV actions via value-based rewards. To the end, we conduct sufficient navigation experiments on the TravelUAV benchmark with dataset scaling across diverse reward settings. Our method demonstrates consistent performance gains of up to 4.34% in Success Rate, 6.19% in Oracle Success Rate, and 4.07% in Success weighted by Path Length over baseline methods, validating its deployment efficacy for long-horizon UAV navigation in complex aerial environments.
GLAM: Global-Local Variation Awareness in Mamba-based World Model
Jan 21, 2025



Mimicking the real interaction trajectory in the inference of the world model has been shown to improve the sample efficiency of model-based reinforcement learning (MBRL) algorithms. Many methods directly use known state sequences for reasoning. However, this approach fails to enhance the quality of reasoning by capturing the subtle variation between states. Much like how humans infer trends in event development from this variation, in this work, we introduce Global-Local variation Awareness Mamba-based world model (GLAM) that improves reasoning quality by perceiving and predicting variation between states. GLAM comprises two Mambabased parallel reasoning modules, GMamba and LMamba, which focus on perceiving variation from global and local perspectives, respectively, during the reasoning process. GMamba focuses on identifying patterns of variation between states in the input sequence and leverages these patterns to enhance the prediction of future state variation. LMamba emphasizes reasoning about unknown information, such as rewards, termination signals, and visual representations, by perceiving variation in adjacent states. By integrating the strengths of the two modules, GLAM accounts for highervalue variation in environmental changes, providing the agent with more efficient imagination-based training. We demonstrate that our method outperforms existing methods in normalized human scores on the Atari 100k benchmark.
Novel Object Synthesis via Adaptive Text-Image Harmony
Oct 28, 2024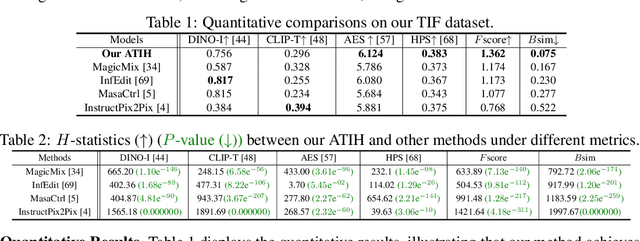
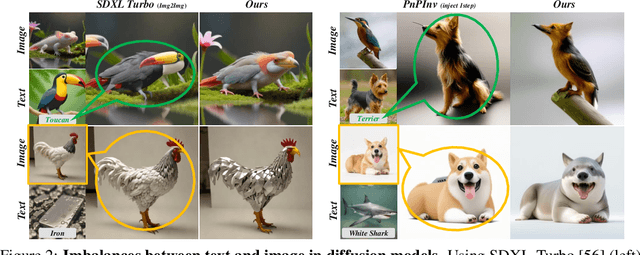
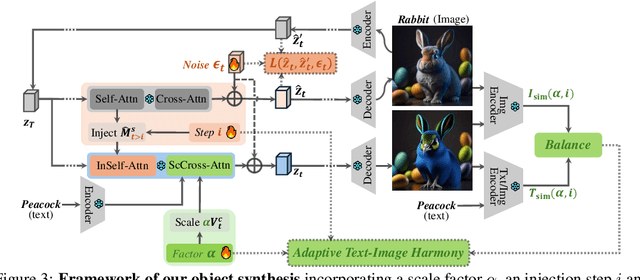
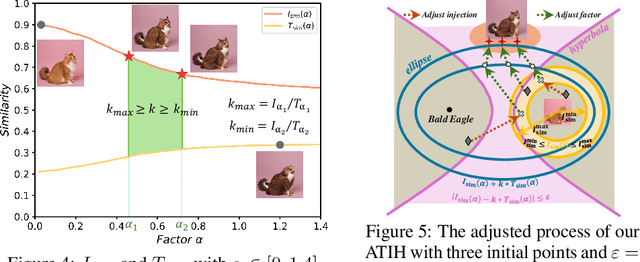
In this paper, we study an object synthesis task that combines an object text with an object image to create a new object image. However, most diffusion models struggle with this task, \textit{i.e.}, often generating an object that predominantly reflects either the text or the image due to an imbalance between their inputs. To address this issue, we propose a simple yet effective method called Adaptive Text-Image Harmony (ATIH) to generate novel and surprising objects. First, we introduce a scale factor and an injection step to balance text and image features in cross-attention and to preserve image information in self-attention during the text-image inversion diffusion process, respectively. Second, to better integrate object text and image, we design a balanced loss function with a noise parameter, ensuring both optimal editability and fidelity of the object image. Third, to adaptively adjust these parameters, we present a novel similarity score function that not only maximizes the similarities between the generated object image and the input text/image but also balances these similarities to harmonize text and image integration. Extensive experiments demonstrate the effectiveness of our approach, showcasing remarkable object creations such as colobus-glass jar. Project page: https://xzr52.github.io/ATIH/.
Cs2K: Class-specific and Class-shared Knowledge Guidance for Incremental Semantic Segmentation
Jul 12, 2024
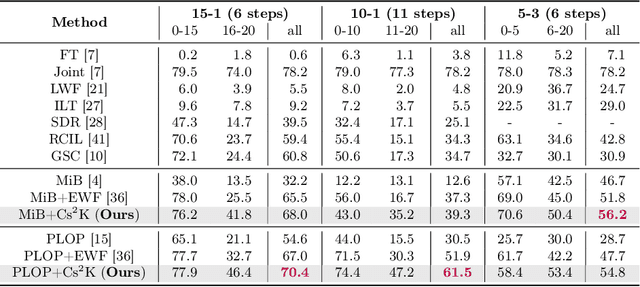
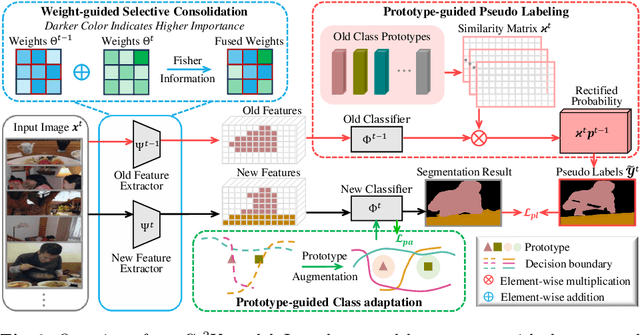
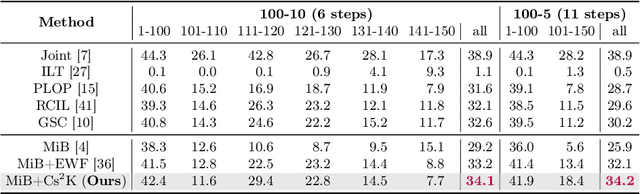
Incremental semantic segmentation endeavors to segment newly encountered classes while maintaining knowledge of old classes. However, existing methods either 1) lack guidance from class-specific knowledge (i.e., old class prototypes), leading to a bias towards new classes, or 2) constrain class-shared knowledge (i.e., old model weights) excessively without discrimination, resulting in a preference for old classes. In this paper, to trade off model performance, we propose the Class-specific and Class-shared Knowledge (Cs2K) guidance for incremental semantic segmentation. Specifically, from the class-specific knowledge aspect, we design a prototype-guided pseudo labeling that exploits feature proximity from prototypes to correct pseudo labels, thereby overcoming catastrophic forgetting. Meanwhile, we develop a prototype-guided class adaptation that aligns class distribution across datasets via learning old augmented prototypes. Moreover, from the class-shared knowledge aspect, we propose a weight-guided selective consolidation to strengthen old memory while maintaining new memory by integrating old and new model weights based on weight importance relative to old classes. Experiments on public datasets demonstrate that our proposed Cs2K significantly improves segmentation performance and is plug-and-play.
MuseumMaker: Continual Style Customization without Catastrophic Forgetting
Apr 29, 2024



Pre-trained large text-to-image (T2I) models with an appropriate text prompt has attracted growing interests in customized images generation field. However, catastrophic forgetting issue make it hard to continually synthesize new user-provided styles while retaining the satisfying results amongst learned styles. In this paper, we propose MuseumMaker, a method that enables the synthesis of images by following a set of customized styles in a never-end manner, and gradually accumulate these creative artistic works as a Museum. When facing with a new customization style, we develop a style distillation loss module to extract and learn the styles of the training data for new image generation. It can minimize the learning biases caused by content of new training images, and address the catastrophic overfitting issue induced by few-shot images. To deal with catastrophic forgetting amongst past learned styles, we devise a dual regularization for shared-LoRA module to optimize the direction of model update, which could regularize the diffusion model from both weight and feature aspects, respectively. Meanwhile, to further preserve historical knowledge from past styles and address the limited representability of LoRA, we consider a task-wise token learning module where a unique token embedding is learned to denote a new style. As any new user-provided style come, our MuseumMaker can capture the nuances of the new styles while maintaining the details of learned styles. Experimental results on diverse style datasets validate the effectiveness of our proposed MuseumMaker method, showcasing its robustness and versatility across various scenarios.
Never-Ending Embodied Robot Learning
Mar 01, 2024



Relying on large language models (LLMs), embodied robots could perform complex multimodal robot manipulation tasks from visual observations with powerful generalization ability. However, most visual behavior-cloning agents suffer from manipulation performance degradation and skill knowledge forgetting when adapting into a series of challenging unseen tasks. We here investigate the above challenge with NBCagent in embodied robots, a pioneering language-conditioned Never-ending Behavior-Cloning agent, which can continually learn observation knowledge of novel robot manipulation skills from skill-specific and skill-shared attributes. Specifically, we establish a skill-specific evolving planner to perform knowledge decoupling, which can continually embed novel skill-specific knowledge in our NBCagent agent from latent and low-rank space. Meanwhile, we propose a skill-shared semantics rendering module and a skill-shared representation distillation module to effectively transfer anti-forgetting skill-shared knowledge, further tackling catastrophic forgetting on old skills from semantics and representation aspects. Finally, we design a continual embodied robot manipulation benchmark, and several expensive experiments demonstrate the significant performance of our method. Visual results, code, and dataset are provided at: https://neragent.github.io.
Create Your World: Lifelong Text-to-Image Diffusion
Sep 08, 2023Text-to-image generative models can produce diverse high-quality images of concepts with a text prompt, which have demonstrated excellent ability in image generation, image translation, etc. We in this work study the problem of synthesizing instantiations of a use's own concepts in a never-ending manner, i.e., create your world, where the new concepts from user are quickly learned with a few examples. To achieve this goal, we propose a Lifelong text-to-image Diffusion Model (L2DM), which intends to overcome knowledge "catastrophic forgetting" for the past encountered concepts, and semantic "catastrophic neglecting" for one or more concepts in the text prompt. In respect of knowledge "catastrophic forgetting", our L2DM framework devises a task-aware memory enhancement module and a elastic-concept distillation module, which could respectively safeguard the knowledge of both prior concepts and each past personalized concept. When generating images with a user text prompt, the solution to semantic "catastrophic neglecting" is that a concept attention artist module can alleviate the semantic neglecting from concept aspect, and an orthogonal attention module can reduce the semantic binding from attribute aspect. To the end, our model can generate more faithful image across a range of continual text prompts in terms of both qualitative and quantitative metrics, when comparing with the related state-of-the-art models. The code will be released at https://wenqiliang.github.io/.
Heterogeneous Forgetting Compensation for Class-Incremental Learning
Aug 24, 2023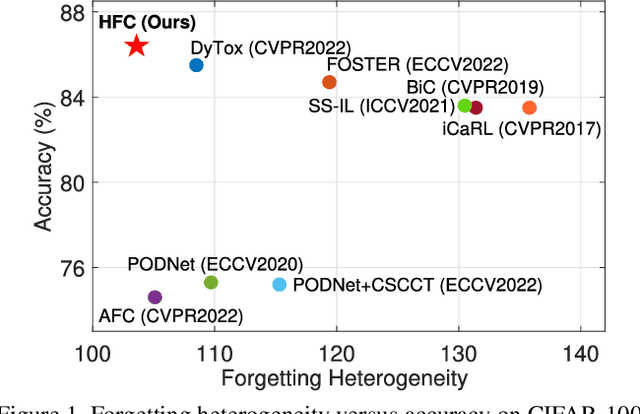



Class-incremental learning (CIL) has achieved remarkable successes in learning new classes consecutively while overcoming catastrophic forgetting on old categories. However, most existing CIL methods unreasonably assume that all old categories have the same forgetting pace, and neglect negative influence of forgetting heterogeneity among different old classes on forgetting compensation. To surmount the above challenges, we develop a novel Heterogeneous Forgetting Compensation (HFC) model, which can resolve heterogeneous forgetting of easy-to-forget and hard-to-forget old categories from both representation and gradient aspects. Specifically, we design a task-semantic aggregation block to alleviate heterogeneous forgetting from representation aspect. It aggregates local category information within each task to learn task-shared global representations. Moreover, we develop two novel plug-and-play losses: a gradient-balanced forgetting compensation loss and a gradient-balanced relation distillation loss to alleviate forgetting from gradient aspect. They consider gradient-balanced compensation to rectify forgetting heterogeneity of old categories and heterogeneous relation consistency. Experiments on several representative datasets illustrate effectiveness of our HFC model. The code is available at https://github.com/JiahuaDong/HFC.
I3DOD: Towards Incremental 3D Object Detection via Prompting
Aug 24, 2023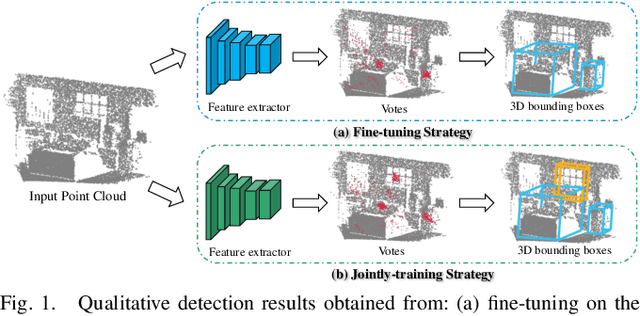
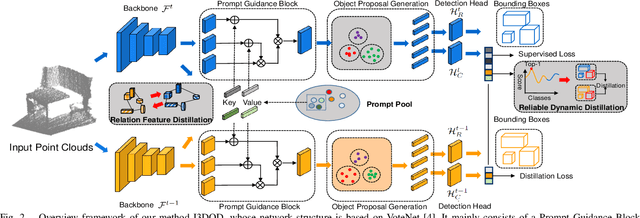
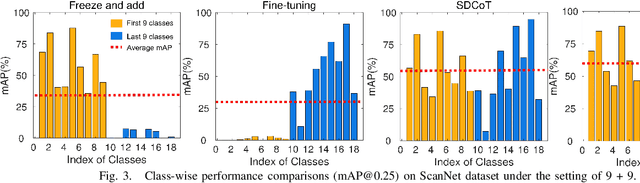

3D object detection has achieved significant performance in many fields, e.g., robotics system, autonomous driving, and augmented reality. However, most existing methods could cause catastrophic forgetting of old classes when performing on the class-incremental scenarios. Meanwhile, the current class-incremental 3D object detection methods neglect the relationships between the object localization information and category semantic information and assume all the knowledge of old model is reliable. To address the above challenge, we present a novel Incremental 3D Object Detection framework with the guidance of prompting, i.e., I3DOD. Specifically, we propose a task-shared prompts mechanism to learn the matching relationships between the object localization information and category semantic information. After training on the current task, these prompts will be stored in our prompt pool, and perform the relationship of old classes in the next task. Moreover, we design a reliable distillation strategy to transfer knowledge from two aspects: a reliable dynamic distillation is developed to filter out the negative knowledge and transfer the reliable 3D knowledge to new detection model; the relation feature is proposed to capture the responses relation in feature space and protect plasticity of the model when learning novel 3D classes. To the end, we conduct comprehensive experiments on two benchmark datasets and our method outperforms the state-of-the-art object detection methods by 0.6% - 2.7% in terms of mAP@0.25.