 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDDM: Bridging Synthetic-to-Real Domain Gap from Physics-Guided Diffusion for Real-world Image Dehazing
Apr 30, 2025Due to the domain gap between real-world and synthetic hazy images, current data-driven dehazing algorithms trained on synthetic datasets perform well on synthetic data but struggle to generalize to real-world scenarios. To address this challenge, we propose \textbf{I}mage \textbf{D}ehazing \textbf{D}iffusion \textbf{M}odels (IDDM), a novel diffusion process that incorporates the atmospheric scattering model into noise diffusion. IDDM aims to use the gradual haze formation process to help the denoising Unet robustly learn the distribution of clear images from the conditional input hazy images. We design a specialized training strategy centered around IDDM. Diffusion models are leveraged to bridge the domain gap from synthetic to real-world, while the atmospheric scattering model provides physical guidance for haze formation. During the forward process, IDDM simultaneously introduces haze and noise into clear images, and then robustly separates them during the sampling process. By training with physics-guided information, IDDM shows the ability of domain generalization, and effectively restores the real-world hazy images despite being trained on synthetic datasets. Extensive experiments demonstrate the effectiveness of our method through both quantitative and qualitative comparisons with state-of-the-art approaches.
GLAM: Global-Local Variation Awareness in Mamba-based World Model
Jan 21, 2025



Mimicking the real interaction trajectory in the inference of the world model has been shown to improve the sample efficiency of model-based reinforcement learning (MBRL) algorithms. Many methods directly use known state sequences for reasoning. However, this approach fails to enhance the quality of reasoning by capturing the subtle variation between states. Much like how humans infer trends in event development from this variation, in this work, we introduce Global-Local variation Awareness Mamba-based world model (GLAM) that improves reasoning quality by perceiving and predicting variation between states. GLAM comprises two Mambabased parallel reasoning modules, GMamba and LMamba, which focus on perceiving variation from global and local perspectives, respectively, during the reasoning process. GMamba focuses on identifying patterns of variation between states in the input sequence and leverages these patterns to enhance the prediction of future state variation. LMamba emphasizes reasoning about unknown information, such as rewards, termination signals, and visual representations, by perceiving variation in adjacent states. By integrating the strengths of the two modules, GLAM accounts for highervalue variation in environmental changes, providing the agent with more efficient imagination-based training. We demonstrate that our method outperforms existing methods in normalized human scores on the Atari 100k benchmark.
GAFusion: Adaptive Fusing LiDAR and Camera with Multiple Guidance for 3D Object Detection
Nov 01, 2024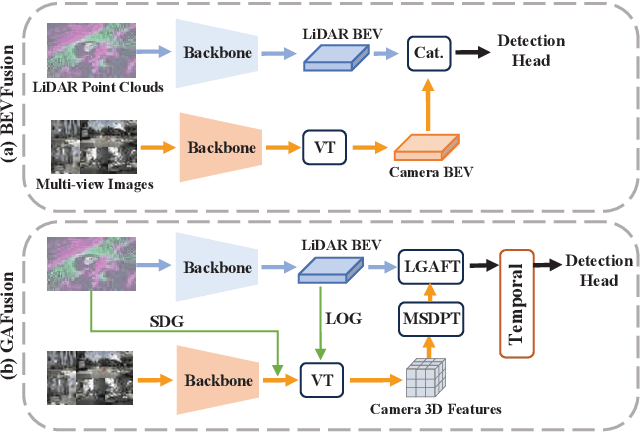
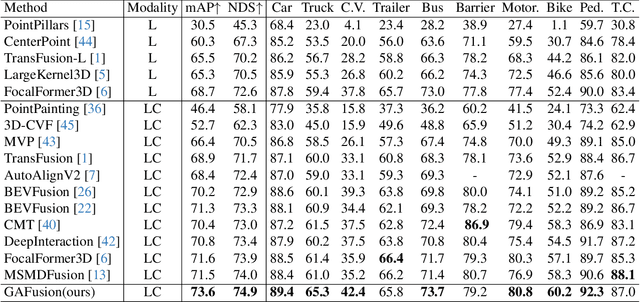
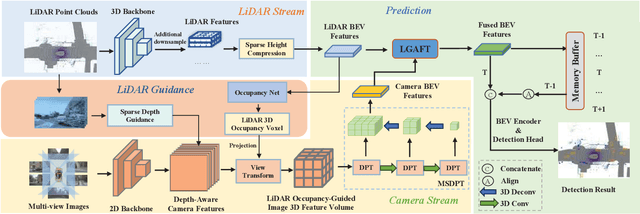
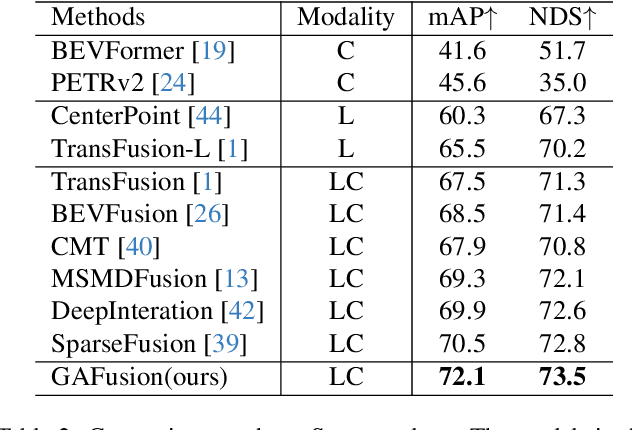
Recent years have witnessed the remarkable progress of 3D multi-modality object detection methods based on the Bird's-Eye-View (BEV) perspective. However, most of them overlook the complementary interaction and guidance between LiDAR and camera. In this work, we propose a novel multi-modality 3D objection detection method, named GAFusion, with LiDAR-guided global interaction and adaptive fusion. Specifically, we introduce sparse depth guidance (SDG) and LiDAR occupancy guidance (LOG) to generate 3D features with sufficient depth information. In the following, LiDAR-guided adaptive fusion transformer (LGAFT) is developed to adaptively enhance the interaction of different modal BEV features from a global perspective. Meanwhile, additional downsampling with sparse height compression and multi-scale dual-path transformer (MSDPT) are designed to enlarge the receptive fields of different modal features. Finally, a temporal fusion module is introduced to aggregate features from previous frames. GAFusion achieves state-of-the-art 3D object detection results with 73.6$\%$ mAP and 74.9$\%$ NDS on the nuScenes test set.
Unbiased Faster R-CNN for Single-source Domain Generalized Object Detection
May 24, 2024

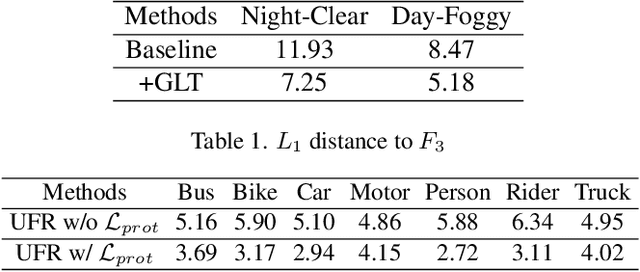

Single-source domain generalization (SDG) for object detection is a challenging yet essential task as the distribution bias of the unseen domain degrades the algorithm performance significantly. However, existing methods attempt to extract domain-invariant features, neglecting that the biased data leads the network to learn biased features that are non-causal and poorly generalizable. To this end, we propose an Unbiased Faster R-CNN (UFR) for generalizable feature learning. Specifically, we formulate SDG in object detection from a causal perspective and construct a Structural Causal Model (SCM) to analyze the data bias and feature bias in the task, which are caused by scene confounders and object attribute confounders. Based on the SCM, we design a Global-Local Transformation module for data augmentation, which effectively simulates domain diversity and mitigates the data bias. Additionally, we introduce a Causal Attention Learning module that incorporates a designed attention invariance loss to learn image-level features that are robust to scene confounders. Moreover, we develop a Causal Prototype Learning module with an explicit instance constraint and an implicit prototype constraint, which further alleviates the negative impact of object attribute confounders. Experimental results on five scenes demonstrate the prominent generalization ability of our method, with an improvement of 3.9% mAP on the Night-Clear scene.
EasyTrack: Efficient and Compact One-stream 3D Point Clouds Tracker
Apr 12, 2024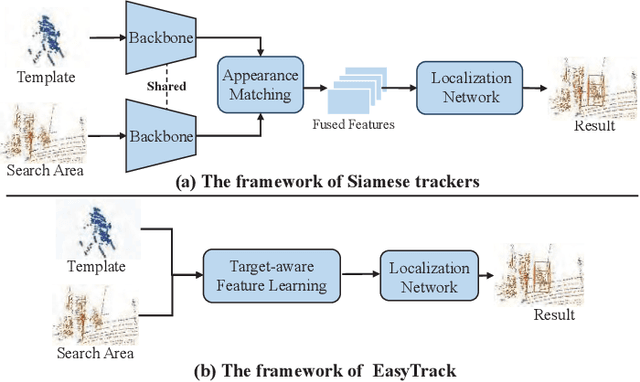
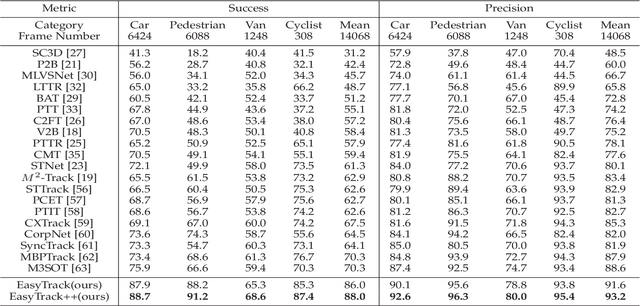
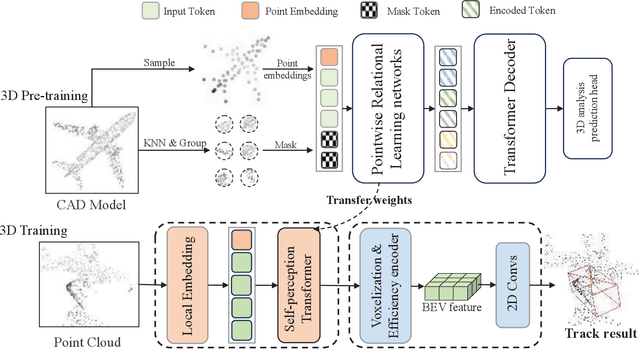
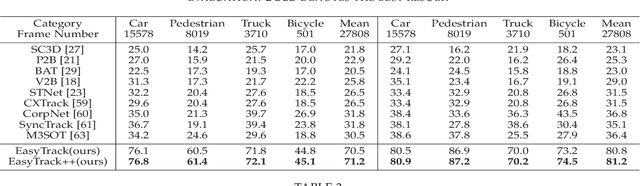
Most of 3D single object trackers (SOT) in point clouds follow the two-stream multi-stage 3D Siamese or motion tracking paradigms, which process the template and search area point clouds with two parallel branches, built on supervised point cloud backbones. In this work, beyond typical 3D Siamese or motion tracking, we propose a neat and compact one-stream transformer 3D SOT paradigm from the novel perspective, termed as \textbf{EasyTrack}, which consists of three special designs: 1) A 3D point clouds tracking feature pre-training module is developed to exploit the masked autoencoding for learning 3D point clouds tracking representations. 2) A unified 3D tracking feature learning and fusion network is proposed to simultaneously learns target-aware 3D features, and extensively captures mutual correlation through the flexible self-attention mechanism. 3) A target location network in the dense bird's eye view (BEV) feature space is constructed for target classification and regression. Moreover, we develop an enhanced version named EasyTrack++, which designs the center points interaction (CPI) strategy to reduce the ambiguous targets caused by the noise point cloud background information. The proposed EasyTrack and EasyTrack++ set a new state-of-the-art performance ($\textbf{18\%}$, $\textbf{40\%}$ and $\textbf{3\%}$ success gains) in KITTI, NuScenes, and Waymo while runing at \textbf{52.6fps} with few parameters (\textbf{1.3M}). The code will be available at https://github.com/KnightApple427/Easytrack.
Exploring Self- and Cross-Triplet Correlations for Human-Object Interaction Detection
Jan 11, 2024



Human-Object Interaction (HOI) detection plays a vital role in scene understanding, which aims to predict the HOI triplet in the form of <human, object, action>. Existing methods mainly extract multi-modal features (e.g., appearance, object semantics, human pose) and then fuse them together to directly predict HOI triplets. However, most of these methods focus on seeking for self-triplet aggregation, but ignore the potential cross-triplet dependencies, resulting in ambiguity of action prediction. In this work, we propose to explore Self- and Cross-Triplet Correlations (SCTC) for HOI detection. Specifically, we regard each triplet proposal as a graph where Human, Object represent nodes and Action indicates edge, to aggregate self-triplet correlation. Also, we try to explore cross-triplet dependencies by jointly considering instance-level, semantic-level, and layout-level relations. Besides, we leverage the CLIP model to assist our SCTC obtain interaction-aware feature by knowledge distillation, which provides useful action clues for HOI detection. Extensive experiments on HICO-DET and V-COCO datasets verify the effectiveness of our proposed SCTC.
Robust 3D Tracking with Quality-Aware Shape Completion
Dec 17, 20233D single object tracking remains a challenging problem due to the sparsity and incompleteness of the point clouds. Existing algorithms attempt to address the challenges in two strategies. The first strategy is to learn dense geometric features based on the captured sparse point cloud. Nevertheless, it is quite a formidable task since the learned dense geometric features are with high uncertainty for depicting the shape of the target object. The other strategy is to aggregate the sparse geometric features of multiple templates to enrich the shape information, which is a routine solution in 2D tracking. However, aggregating the coarse shape representations can hardly yield a precise shape representation. Different from 2D pixels, 3D points of different frames can be directly fused by coordinate transform, i.e., shape completion. Considering that, we propose to construct a synthetic target representation composed of dense and complete point clouds depicting the target shape precisely by shape completion for robust 3D tracking. Specifically, we design a voxelized 3D tracking framework with shape completion, in which we propose a quality-aware shape completion mechanism to alleviate the adverse effect of noisy historical predictions. It enables us to effectively construct and leverage the synthetic target representation. Besides, we also develop a voxelized relation modeling module and box refinement module to improve tracking performance. Favorable performance against state-of-the-art algorithms on three benchmarks demonstrates the effectiveness and generalization ability of our method.
SA$^2$VP: Spatially Aligned-and-Adapted Visual Prompt
Dec 16, 2023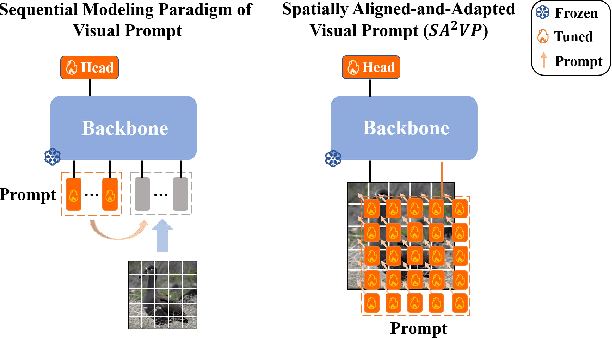
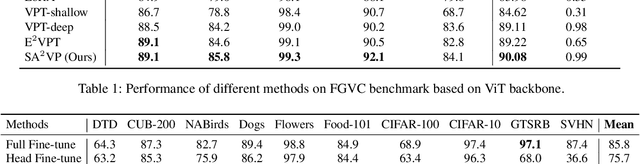
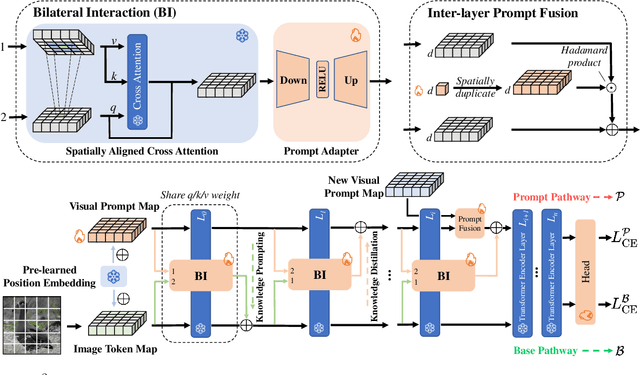

As a prominent parameter-efficient fine-tuning technique in NLP, prompt tuning is being explored its potential in computer vision. Typical methods for visual prompt tuning follow the sequential modeling paradigm stemming from NLP, which represents an input image as a flattened sequence of token embeddings and then learns a set of unordered parameterized tokens prefixed to the sequence representation as the visual prompts for task adaptation of large vision models. While such sequential modeling paradigm of visual prompt has shown great promise, there are two potential limitations. First, the learned visual prompts cannot model the underlying spatial relations in the input image, which is crucial for image encoding. Second, since all prompt tokens play the same role of prompting for all image tokens without distinction, it lacks the fine-grained prompting capability, i.e., individual prompting for different image tokens. In this work, we propose the \mymodel model (\emph{SA$^2$VP}), which learns a two-dimensional prompt token map with equal (or scaled) size to the image token map, thereby being able to spatially align with the image map. Each prompt token is designated to prompt knowledge only for the spatially corresponding image tokens. As a result, our model can conduct individual prompting for different image tokens in a fine-grained manner. Moreover, benefiting from the capability of preserving the spatial structure by the learned prompt token map, our \emph{SA$^2$VP} is able to model the spatial relations in the input image, leading to more effective prompting. Extensive experiments on three challenging benchmarks for image classification demonstrate the superiority of our model over other state-of-the-art methods for visual prompt tuning. Code is available at \emph{https://github.com/tommy-xq/SA2VP}.
D$^2$ST-Adapter: Disentangled-and-Deformable Spatio-Temporal Adapter for Few-shot Action Recognition
Dec 03, 2023



Adapting large pre-trained image models to few-shot action recognition has proven to be an effective and efficient strategy for learning robust feature extractors, which is essential for few-shot learning. Typical fine-tuning based adaptation paradigm is prone to overfitting in the few-shot learning scenarios and offers little modeling flexibility for learning temporal features in video data. In this work we present the Disentangled-and-Deformable Spatio-Temporal Adapter (D$^2$ST-Adapter), a novel adapter tuning framework for few-shot action recognition, which is designed in a dual-pathway architecture to encode spatial and temporal features in a disentangled manner. Furthermore, we devise the Deformable Spatio-Temporal Attention module as the core component of D$^2$ST-Adapter, which can be tailored to model both spatial and temporal features in corresponding pathways, allowing our D$^2$ST-Adapter to encode features in a global view in 3D spatio-temporal space while maintaining a lightweight design. Extensive experiments with instantiations of our method on both pre-trained ResNet and ViT demonstrate the superiority of our method over state-of-the-art methods for few-shot action recognition. Our method is particularly well-suited to challenging scenarios where temporal dynamics are critical for action recognition.
Activating the Discriminability of Novel Classes for Few-shot Segmentation
Dec 02, 2022Despite the remarkable success of existing methods for few-shot segmentation, there remain two crucial challenges. First, the feature learning for novel classes is suppressed during the training on base classes in that the novel classes are always treated as background. Thus, the semantics of novel classes are not well learned. Second, most of existing methods fail to consider the underlying semantic gap between the support and the query resulting from the representative bias by the scarce support samples. To circumvent these two challenges, we propose to activate the discriminability of novel classes explicitly in both the feature encoding stage and the prediction stage for segmentation. In the feature encoding stage, we design the Semantic-Preserving Feature Learning module (SPFL) to first exploit and then retain the latent semantics contained in the whole input image, especially those in the background that belong to novel classes. In the prediction stage for segmentation, we learn an Self-Refined Online Foreground-Background classifier (SROFB), which is able to refine itself using the high-confidence pixels of query image to facilitate its adaptation to the query image and bridge the support-query semantic gap. Extensive experiments on PASCAL-5$^i$ and COCO-20$^i$ datasets demonstrates the advantages of these two novel designs both quantitatively and qualitatively.