 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSA$^2$VP: Spatially Aligned-and-Adapted Visual Prompt
Paper and Code
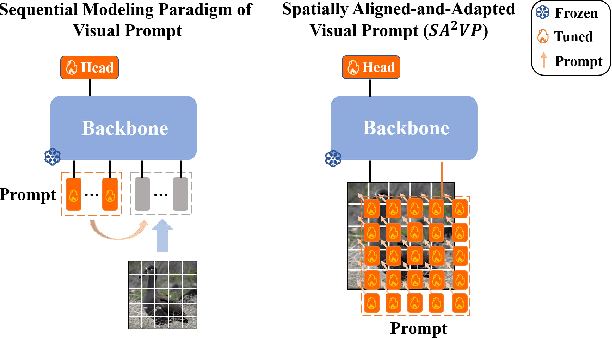
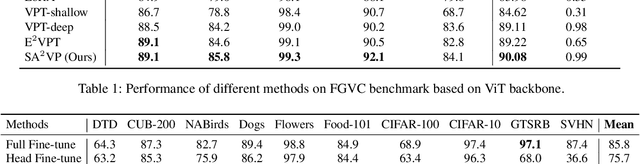
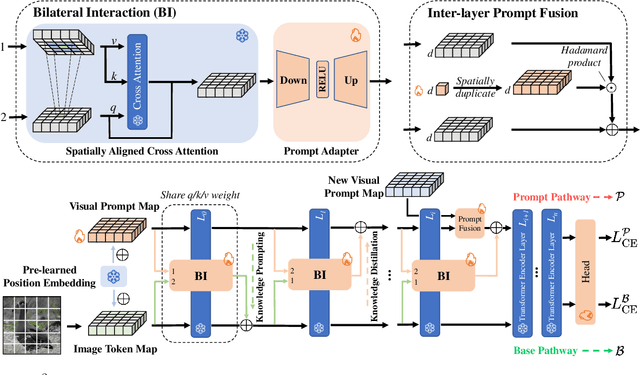

As a prominent parameter-efficient fine-tuning technique in NLP, prompt tuning is being explored its potential in computer vision. Typical methods for visual prompt tuning follow the sequential modeling paradigm stemming from NLP, which represents an input image as a flattened sequence of token embeddings and then learns a set of unordered parameterized tokens prefixed to the sequence representation as the visual prompts for task adaptation of large vision models. While such sequential modeling paradigm of visual prompt has shown great promise, there are two potential limitations. First, the learned visual prompts cannot model the underlying spatial relations in the input image, which is crucial for image encoding. Second, since all prompt tokens play the same role of prompting for all image tokens without distinction, it lacks the fine-grained prompting capability, i.e., individual prompting for different image tokens. In this work, we propose the \mymodel model (\emph{SA$^2$VP}), which learns a two-dimensional prompt token map with equal (or scaled) size to the image token map, thereby being able to spatially align with the image map. Each prompt token is designated to prompt knowledge only for the spatially corresponding image tokens. As a result, our model can conduct individual prompting for different image tokens in a fine-grained manner. Moreover, benefiting from the capability of preserving the spatial structure by the learned prompt token map, our \emph{SA$^2$VP} is able to model the spatial relations in the input image, leading to more effective prompting. Extensive experiments on three challenging benchmarks for image classification demonstrate the superiority of our model over other state-of-the-art methods for visual prompt tuning. Code is available at \emph{https://github.com/tommy-xq/SA2VP}.