 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeCromCL: Weakly Supervised Cross-Modality Contrastive Learning for Transcription-only Supervised Text Spotting
Jul 28, 2024Transcription-only Supervised Text Spotting aims to learn text spotters relying only on transcriptions but no text boundaries for supervision, thus eliminating expensive boundary annotation. The crux of this task lies in locating each transcription in scene text images without location annotations. In this work, we formulate this challenging problem as a Weakly Supervised Cross-modality Contrastive Learning problem, and design a simple yet effective model dubbed WeCromCL that is able to detect each transcription in a scene image in a weakly supervised manner. Unlike typical methods for cross-modality contrastive learning that focus on modeling the holistic semantic correlation between an entire image and a text description, our WeCromCL conducts atomistic contrastive learning to model the character-wise appearance consistency between a text transcription and its correlated region in a scene image to detect an anchor point for the transcription in a weakly supervised manner. The detected anchor points by WeCromCL are further used as pseudo location labels to guide the learning of text spotting. Extensive experiments on four challenging benchmarks demonstrate the superior performance of our model over other methods. Code will be released.
Domain-Rectifying Adapter for Cross-Domain Few-Shot Segmentation
Apr 16, 2024



Few-shot semantic segmentation (FSS) has achieved great success on segmenting objects of novel classes, supported by only a few annotated samples. However, existing FSS methods often underperform in the presence of domain shifts, especially when encountering new domain styles that are unseen during training. It is suboptimal to directly adapt or generalize the entire model to new domains in the few-shot scenario. Instead, our key idea is to adapt a small adapter for rectifying diverse target domain styles to the source domain. Consequently, the rectified target domain features can fittingly benefit from the well-optimized source domain segmentation model, which is intently trained on sufficient source domain data. Training domain-rectifying adapter requires sufficiently diverse target domains. We thus propose a novel local-global style perturbation method to simulate diverse potential target domains by perturbating the feature channel statistics of the individual images and collective statistics of the entire source domain, respectively. Additionally, we propose a cyclic domain alignment module to facilitate the adapter effectively rectifying domains using a reverse domain rectification supervision. The adapter is trained to rectify the image features from diverse synthesized target domains to align with the source domain. During testing on target domains, we start by rectifying the image features and then conduct few-shot segmentation on the domain-rectified features. Extensive experiments demonstrate the effectiveness of our method, achieving promising results on cross-domain few-shot semantic segmentation tasks. Our code is available at https://github.com/Matt-Su/DR-Adapter.
OrthCaps: An Orthogonal CapsNet with Sparse Attention Routing and Pruning
Mar 20, 2024



Redundancy is a persistent challenge in Capsule Networks (CapsNet),leading to high computational costs and parameter counts. Although previous works have introduced pruning after the initial capsule layer, dynamic routing's fully connected nature and non-orthogonal weight matrices reintroduce redundancy in deeper layers. Besides, dynamic routing requires iterating to converge, further increasing computational demands. In this paper, we propose an Orthogonal Capsule Network (OrthCaps) to reduce redundancy, improve routing performance and decrease parameter counts. Firstly, an efficient pruned capsule layer is introduced to discard redundant capsules. Secondly, dynamic routing is replaced with orthogonal sparse attention routing, eliminating the need for iterations and fully connected structures. Lastly, weight matrices during routing are orthogonalized to sustain low capsule similarity, which is the first approach to introduce orthogonality into CapsNet as far as we know. Our experiments on baseline datasets affirm the efficiency and robustness of OrthCaps in classification tasks, in which ablation studies validate the criticality of each component. Remarkably, OrthCaps-Shallow outperforms other Capsule Network benchmarks on four datasets, utilizing only 110k parameters, which is a mere 1.25% of a standard Capsule Network's total. To the best of our knowledge, it achieves the smallest parameter count among existing Capsule Networks. Similarly, OrthCaps-Deep demonstrates competitive performance across four datasets, utilizing only 1.2% of the parameters required by its counterparts.
SA$^2$VP: Spatially Aligned-and-Adapted Visual Prompt
Dec 16, 2023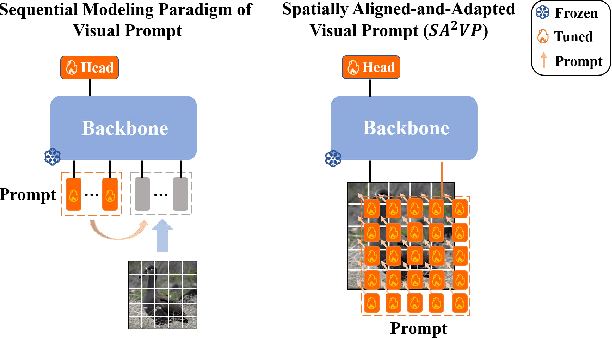
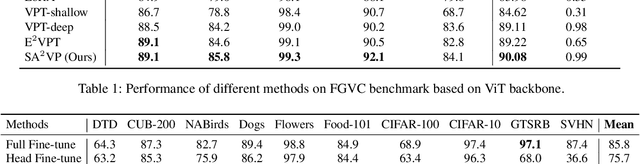
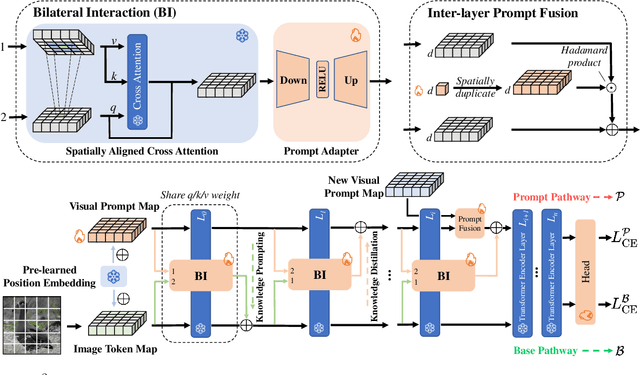

As a prominent parameter-efficient fine-tuning technique in NLP, prompt tuning is being explored its potential in computer vision. Typical methods for visual prompt tuning follow the sequential modeling paradigm stemming from NLP, which represents an input image as a flattened sequence of token embeddings and then learns a set of unordered parameterized tokens prefixed to the sequence representation as the visual prompts for task adaptation of large vision models. While such sequential modeling paradigm of visual prompt has shown great promise, there are two potential limitations. First, the learned visual prompts cannot model the underlying spatial relations in the input image, which is crucial for image encoding. Second, since all prompt tokens play the same role of prompting for all image tokens without distinction, it lacks the fine-grained prompting capability, i.e., individual prompting for different image tokens. In this work, we propose the \mymodel model (\emph{SA$^2$VP}), which learns a two-dimensional prompt token map with equal (or scaled) size to the image token map, thereby being able to spatially align with the image map. Each prompt token is designated to prompt knowledge only for the spatially corresponding image tokens. As a result, our model can conduct individual prompting for different image tokens in a fine-grained manner. Moreover, benefiting from the capability of preserving the spatial structure by the learned prompt token map, our \emph{SA$^2$VP} is able to model the spatial relations in the input image, leading to more effective prompting. Extensive experiments on three challenging benchmarks for image classification demonstrate the superiority of our model over other state-of-the-art methods for visual prompt tuning. Code is available at \emph{https://github.com/tommy-xq/SA2VP}.
Million-scale Object Detection with Large Vision Model
Dec 19, 2022Over the past few years, developing a broad, universal, and general-purpose computer vision system has become a hot topic. A powerful universal system would be capable of solving diverse vision tasks simultaneously without being restricted to a specific problem or a specific data domain, which is of great importance in practical real-world computer vision applications. This study pushes the direction forward by concentrating on the million-scale multi-domain universal object detection problem. The problem is not trivial due to its complicated nature in terms of cross-dataset category label duplication, label conflicts, and the hierarchical taxonomy handling. Moreover, what is the resource-efficient way to utilize emerging large pre-trained vision models for million-scale cross-dataset object detection remains an open challenge. This paper tries to address these challenges by introducing our practices in label handling, hierarchy-aware loss design and resource-efficient model training with a pre-trained large model. Our method is ranked second in the object detection track of Robust Vision Challenge 2022 (RVC 2022). We hope our detailed study would serve as an alternative practice paradigm for similar problems in the community. The code is available at https://github.com/linfeng93/Large-UniDet.
Semantic-Aware Local-Global Vision Transformer
Nov 27, 2022
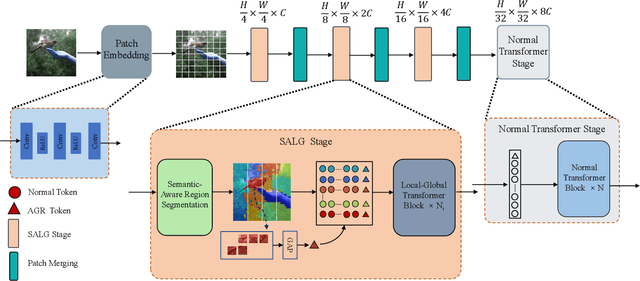
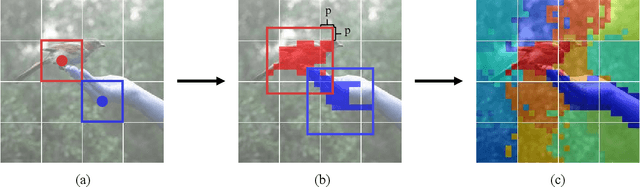

Vision Transformers have achieved remarkable progresses, among which Swin Transformer has demonstrated the tremendous potential of Transformer for vision tasks. It surmounts the key challenge of high computational complexity by performing local self-attention within shifted windows. In this work we propose the Semantic-Aware Local-Global Vision Transformer (SALG), to further investigate two potential improvements towards Swin Transformer. First, unlike Swin Transformer that performs uniform partition to produce equal size of regular windows for local self-attention, our SALG performs semantic segmentation in an unsupervised way to explore the underlying semantic priors in the image. As a result, each segmented region can correspond to a semantically meaningful part in the image, potentially leading to more effective features within each of segmented regions. Second, instead of only performing local self-attention within local windows as Swin Transformer does, the proposed SALG performs both 1) local intra-region self-attention for learning fine-grained features within each region and 2) global inter-region feature propagation for modeling global dependencies among all regions. Consequently, our model is able to obtain the global view when learning features for each token, which is the essential advantage of Transformer. Owing to the explicit modeling of the semantic priors and the proposed local-global modeling mechanism, our SALG is particularly advantageous for small-scale models when the modeling capacity is not sufficient for other models to learn semantics implicitly. Extensive experiments across various vision tasks demonstrates the merit of our model over other vision Transformers, especially in the small-scale modeling scenarios.
Learning Generalizable Latent Representations for Novel Degradations in Super Resolution
Jul 25, 2022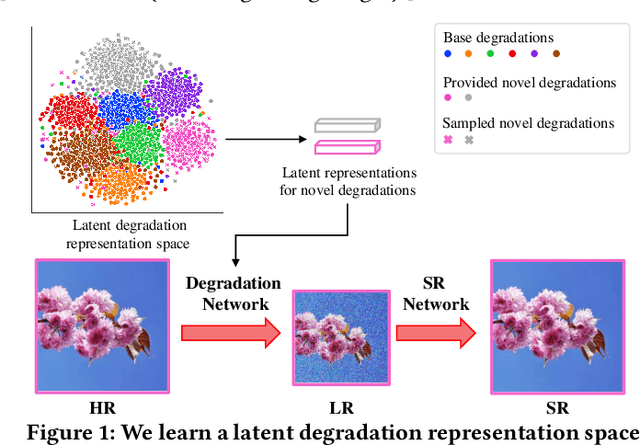

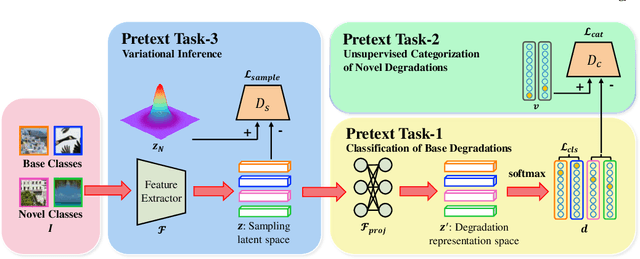
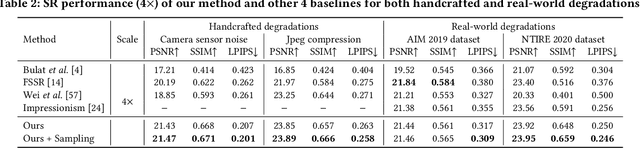
Typical methods for blind image super-resolution (SR) focus on dealing with unknown degradations by directly estimating them or learning the degradation representations in a latent space. A potential limitation of these methods is that they assume the unknown degradations can be simulated by the integration of various handcrafted degradations (e.g., bicubic downsampling), which is not necessarily true. The real-world degradations can be beyond the simulation scope by the handcrafted degradations, which are referred to as novel degradations. In this work, we propose to learn a latent representation space for degradations, which can be generalized from handcrafted (base) degradations to novel degradations. The obtained representations for a novel degradation in this latent space are then leveraged to generate degraded images consistent with the novel degradation to compose paired training data for SR model. Furthermore, we perform variational inference to match the posterior of degradations in latent representation space with a prior distribution (e.g., Gaussian distribution). Consequently, we are able to sample more high-quality representations for a novel degradation to augment the training data for SR model. We conduct extensive experiments on both synthetic and real-world datasets to validate the effectiveness and advantages of our method for blind super-resolution with novel degradations.
Few-Shot Object Detection by Knowledge Distillation Using Bag-of-Visual-Words Representations
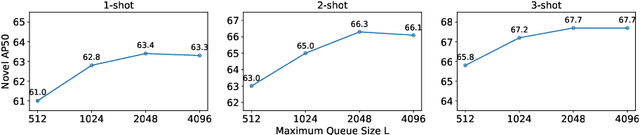
Jul 25, 2022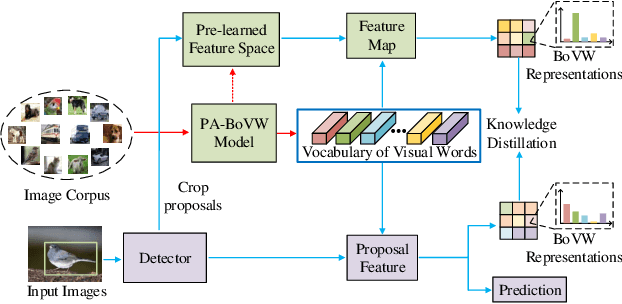
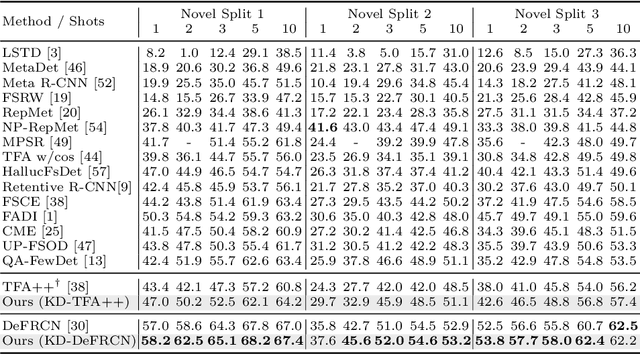
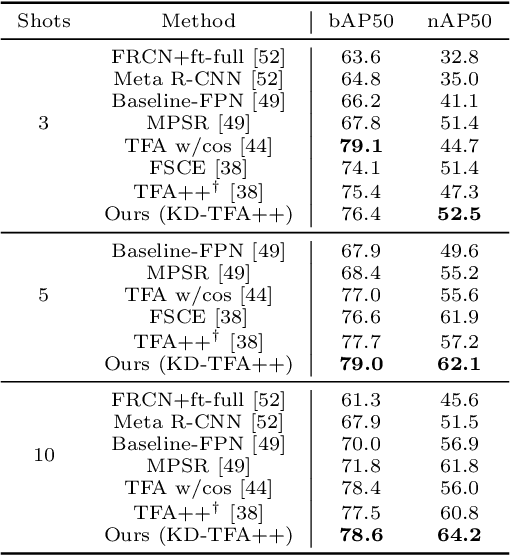

While fine-tuning based methods for few-shot object detection have achieved remarkable progress, a crucial challenge that has not been addressed well is the potential class-specific overfitting on base classes and sample-specific overfitting on novel classes. In this work we design a novel knowledge distillation framework to guide the learning of the object detector and thereby restrain the overfitting in both the pre-training stage on base classes and fine-tuning stage on novel classes. To be specific, we first present a novel Position-Aware Bag-of-Visual-Words model for learning a representative bag of visual words (BoVW) from a limited size of image set, which is used to encode general images based on the similarities between the learned visual words and an image. Then we perform knowledge distillation based on the fact that an image should have consistent BoVW representations in two different feature spaces. To this end, we pre-learn a feature space independently from the object detection, and encode images using BoVW in this space. The obtained BoVW representation for an image can be considered as distilled knowledge to guide the learning of object detector: the extracted features by the object detector for the same image are expected to derive the consistent BoVW representations with the distilled knowledge. Extensive experiments validate the effectiveness of our method and demonstrate the superiority over other state-of-the-art methods.
Multi-Faceted Distillation of Base-Novel Commonality for Few-shot Object Detection
Jul 22, 2022


Most of existing methods for few-shot object detection follow the fine-tuning paradigm, which potentially assumes that the class-agnostic generalizable knowledge can be learned and transferred implicitly from base classes with abundant samples to novel classes with limited samples via such a two-stage training strategy. However, it is not necessarily true since the object detector can hardly distinguish between class-agnostic knowledge and class-specific knowledge automatically without explicit modeling. In this work we propose to learn three types of class-agnostic commonalities between base and novel classes explicitly: recognition-related semantic commonalities, localization-related semantic commonalities and distribution commonalities. We design a unified distillation framework based on a memory bank, which is able to perform distillation of all three types of commonalities jointly and efficiently. Extensive experiments demonstrate that our method can be readily integrated into most of existing fine-tuning based methods and consistently improve the performance by a large margin.
Global-Local Stepwise Generative Network for Ultra High-Resolution Image Restoration
Jul 16, 2022



While the research on image background restoration from regular size of degraded images has achieved remarkable progress, restoring ultra high-resolution (e.g., 4K) images remains an extremely challenging task due to the explosion of computational complexity and memory usage, as well as the deficiency of annotated data. In this paper we present a novel model for ultra high-resolution image restoration, referred to as the Global-Local Stepwise Generative Network (GLSGN), which employs a stepwise restoring strategy involving four restoring pathways: three local pathways and one global pathway. The local pathways focus on conducting image restoration in a fine-grained manner over local but high-resolution image patches, while the global pathway performs image restoration coarsely on the scale-down but intact image to provide cues for the local pathways in a global view including semantics and noise patterns. To smooth the mutual collaboration between these four pathways, our GLSGN is designed to ensure the inter-pathway consistency in four aspects in terms of low-level content, perceptual attention, restoring intensity and high-level semantics, respectively. As another major contribution of this work, we also introduce the first ultra high-resolution dataset to date for both reflection removal and rain streak removal, comprising 4,670 real-world and synthetic images. Extensive experiments across three typical tasks for image background restoration, including image reflection removal, image rain streak removal and image dehazing, show that our GLSGN consistently outperforms state-of-the-art methods.