 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Object Detection by Knowledge Distillation Using Bag-of-Visual-Words Representations
Paper and Code
Jul 25, 2022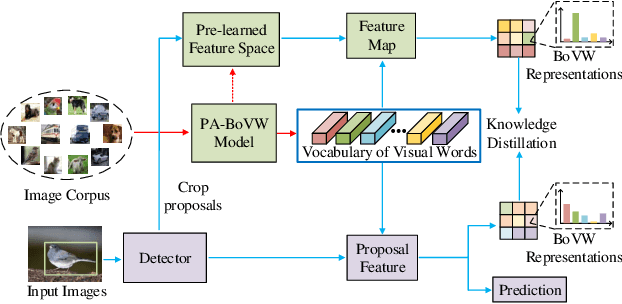
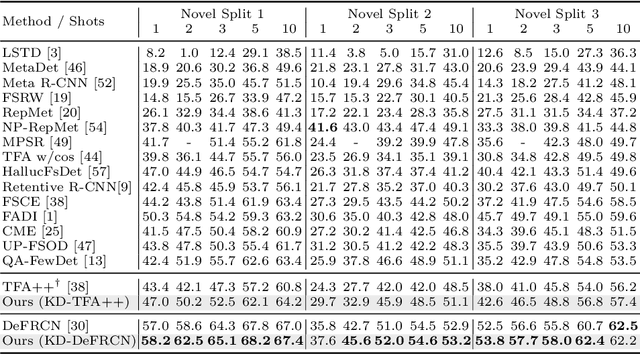
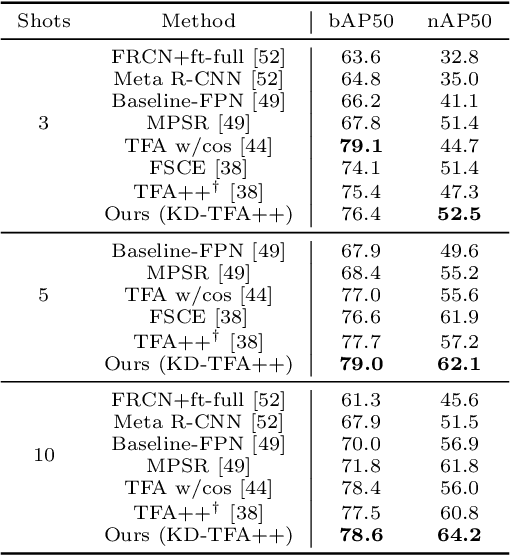

While fine-tuning based methods for few-shot object detection have achieved remarkable progress, a crucial challenge that has not been addressed well is the potential class-specific overfitting on base classes and sample-specific overfitting on novel classes. In this work we design a novel knowledge distillation framework to guide the learning of the object detector and thereby restrain the overfitting in both the pre-training stage on base classes and fine-tuning stage on novel classes. To be specific, we first present a novel Position-Aware Bag-of-Visual-Words model for learning a representative bag of visual words (BoVW) from a limited size of image set, which is used to encode general images based on the similarities between the learned visual words and an image. Then we perform knowledge distillation based on the fact that an image should have consistent BoVW representations in two different feature spaces. To this end, we pre-learn a feature space independently from the object detection, and encode images using BoVW in this space. The obtained BoVW representation for an image can be considered as distilled knowledge to guide the learning of object detector: the extracted features by the object detector for the same image are expected to derive the consistent BoVW representations with the distilled knowledge. Extensive experiments validate the effectiveness of our method and demonstrate the superiority over other state-of-the-art methods.